Keep Calm and Respond: A Beginner's Heuristic to Incident Response
Incidents are scary, but they don’t have to be.
Join the DZone community and get the full member experience.
Join For FreeA few years ago, when working as a software developer building and maintaining internal platform components for a cloud company, I deleted an application from production as part of a deprecation. I had double and triple-checked references and done my due diligence communicating with the company. Within minutes, though, our alerting and monitoring systems began to flood our Slack channels, in a deluge of signals telling me something wasn’t working. The timing was pretty clear; I had broken production.
In medical dramas, the moment when things are about to go wrong is unmistakable. Sounds are muffled. High-pitched, prolonged beeps take over your ears. Vision blurs. When alarms sound, or danger is near, something takes over within you. Blood drains from your head, heat rises in your body, and your hands sweat as you begin to process the situation. Sometimes you confront the issue, sometimes you try to get as far away as possible, and sometimes, you just freeze. In my case, with red dashboards and a sudden influx of noise, I had turned into the surgical intern holding a scalpel for the first time over a critical patient, with no idea what to do.
Incidents are scary, but they don’t have to be. Doctors and surgeons undergo years of training to maintain their composure when approaching high pressure, highly complex, and high stakes problems. They have a wealth of experience to draw from in the form of their attendings and peers. They have established priorities and mental checklists to help them address the most pressing matters first: stop the bleeding and then fix the damage.
As cloud software becomes part of the critical path of our lives, incident response practices at an individual and organizational level are becoming formalized disciplines, as evidenced by the growth of site reliability engineering. As we grow collectively more experienced, incident response becomes less of an unfamiliar, stressful, or overwhelming experience and more like something you've trained and prepared for. As I’ve responded to incidents over my career, I’ve collected a few heuristics that have helped me turn my fight, flight, or freeze response into a reliable incident response practice:
- Understand what hurts for your users
- Be kind to yourself and others
- Information is key
- Focus on sustainable response
- Stop the bleeding
- Apply fixes one at a time
- Know your basics
Understand What Hurts for Your Users
In times of emergency, you learn what is truly important. When creating dashboards and alerts, it’s very easy to alert on just about anything. Who doesn’t want to know when their systems are not working as expected? This is a trick question. You want to know when people can’t use your system as expected. When all your alerts are going off, and all your graphs are red, it becomes important to distinguish between signal and noise. The signal you want to prioritize is user impact. Ask yourself:
- What pain are users experiencing?
- How widespread is the issue?
- What is the business impact? Revenue loss? Data loss?
- Are we in violation of our Service Level Agreements (SLAs)?
At the beginning of an incident, make a best effort estimate of impact based on the data that you have at hand. You can continue to assess the impact throughout the response time and even after an incident is resolved. If you’re working in an organization with a mature incident response practice, questions of impact will be codified and easy to answer. Otherwise, you can rely on metrics, logs, support tickets, or product data to make an educated guess. Use your impact estimate to determine what is the appropriate response and share your reasoning with other responders. Some companies have defined severity scales that dictate who should get paged and when. If not, think that the greater the impact, the more extreme the response. In the emergency room, the more severe and life-threatening your ailment, the faster you will be treated. A large wound will require stitches while a scratch will require a band-aid.
When I broke production by deleting a deprecated application, the first things I turned to were our customer-facing API response rates. The user error rate was over 45%; a user would encounter an error every other time they tried to do something in our product. Our users couldn’t view their accounts, pay their invoices, or do anything at all. With this information, I looked at our published severity scale and determined this required an immediate response, even though we were outside of business hours. I worked with our cloud operations team to get an incident channel created and the response initiated.
Be Kind To Yourself and Others
In today’s world of complex distributed systems and unreliable networks, it is inevitable that one day, you will break production. It’s often seen as a rite of passage when you join new teams. It can happen to even the most seasoned of engineers; a very senior engineer I once worked with broke our whole application because they had forgotten to copy and paste a closing tag in some HTML. When it does happen, be kind to yourself and remember that when these things happen, you are not to blame. We work in complex systems that are not strictly technological. They are surrounded by humans and human processes that intersect them in messy ways. Outages are just the culmination of small mistakes that, in isolation, are not a big deal. In responding to and learning from incidents, we are figuring out how to make our systems better and improve the processes that surround them.
In the moment of the incident and in the postmortem, a process for learning from incidents, strive to remain “blameless.” To act blamelessly means that we assume responders made the best decision possible with the available information at the time. When something goes wrong, it is easy to point fingers. After the fact, it’s easy to identify more optimal decisions when you have all the information and have had time to analyze things outside of the heat of the moment. If we point fingers and assume we could have made better decisions, we close the opportunity to evaluate our weaknesses with candor. When blame is spread, discourse stops. Incident postmortems are discussions intended to understand how an incident happened, how to prevent it in the future, and how to respond better in the future, not a court in which we declare who is guilty and who is innocent. By being kind to yourself and others through the spirit of blamelessness, we learn and improve together.
Information Is Key
An incident can be unpredictable and you never know what kind of information may be helpful to responders. Whether it is a daily standup or a monthly business review, we curate information for our audiences because these are well-known, well-controlled situations. However, an ongoing incident is not the right place to filter new information. Surfacing information throughout an incident serves two purposes. It gives responders more information to use as they make decisions, and it lets non-responders know the status of what is going on.
If there is an ongoing incident that is owned by another team and you are noticing abnormal behavior in your metrics and logs, surfacing that parts of your system are affected by the outage can help determine the breadth of impact and can influence response. One day, our alerts indicated that people were experiencing latency from our services and we started an incident. Around the same time, a second team told us about similar latency issues they had noticed. With this information, we were able to determine more quickly that the issue was really in the database and were able to page the correct team, resulting in a faster resolution. The other side of the coin is balance. If too many teams are surfacing the same information, it can easily become overwhelming for those managing the incident.
Having asynchronous incident communications readily available throughout the incident in a Slack channel or something similar can help keep various stakeholders like support or account representatives informed of the incident status. During our incidents, someone will periodically provide a situation report that will detail a rough timeline as well as the steps that have been taken to date. These sorts of updates help keep responders focused and stakeholders informed for a quick and effective resolution. As an added bonus, having the communication documented as it happened is very helpful in postmortems. The incident communications will give you a good idea of timeline, decisions taken, and resolutions.

Focus on Sustainable Response
In life and throughout an incident, it’s important to focus on the things you can control. This is especially relevant when you experience downtime because of a third-party vendor or a dependency on another team. Incident response is like your body’s stress response. It can give you the capability to accomplish great things in the name of self-preservation, and it’s not good to be in that state for a prolonged period of time. These periods of heightened stress can leave you exhausted afterward, and maintaining them is a sure recipe for burning yourself out. When you cannot do anything to directly impact the outcome of an incident, it’s time for you to stand down and let others take the lead.
One day, a large portion of our customers could not log in or sign up for new accounts because of an outage with a downstream vendor. Based on our severity scale, we would need to be working 24/7 to resolve the outage, but the only way to mitigate the issue would be to move to a new vendor. This was a monumental task that was not likely to be completed with quality late into the evening after a long work day. Keeping responders engaged would have been a sure way to burn them out and reduce response quality the next day. We made the call to stand down from the incident while we waited for a response from the vendor the next morning. We had workarounds in place for customers that would allow them to move forward in most cases, so we did the right thing and waited till morning.
On the other hand, in the morning, it was evident that we wouldn’t be able to get a timely resolution from the vendor. With the mounting burden on support and the growing impact of lost signups, we turned to fixes that we had control over and began the process of changing vendors. Using our knowledge of customer and support impact, we prioritized the vendor change for the areas that would unblock the most customers instead of trying to mitigate every failing system. Breaking down the problem into smaller pieces made it possible to take on this difficult task and spread out the work. This brought our time to resolution down and allowed us to make better decisions for later migrations without exhausting the incident response team.
Stop the Bleeding
When you’re in incident response mode, center your efforts on addressing user pain first: how can we best alleviate the impact to our users? A mitigation is a fix that you can implement that will restore functionality or reduce the impact of a malfunctioning part. This could mean a rollback of a recent deployment, a manual workaround with support, or a temporary configuration change. When we develop features or enhance existing ones, we are designing, architecting, and refactoring for mid to long-term stability. When you’re finding mitigations, you may do things that you wouldn’t normally do because they are inherently short sighted, but provide relief to users while you find a more permanent stable solution. In an operating room, a surgeon may clamp an artery to control bleeding while they repair an organ, and they do so knowing full well that the artery cannot remain clamped indefinitely. You want to be able to develop fixes while your system is in a stable, if not functioning state.
During my application deletion fiasco, we were able to determine that only half of our live instances were trying to connect to the deleted application. Instead of trying to get the deleted application re-deployed, or fix the configuration for the broken services, we decided to route traffic away from the faulty instances. This left us temporarily with services running in only one region, but it allowed our users to continue to use the product while we found the permanent fix. We were able to introduce a new configuration and test that the deployments would work before rerouting traffic to them. It took us 30 minutes to route traffic away and another 60 minutes to fix the instances and reroute traffic to them, leading to only 30 minutes of downtime as opposed to what could have been 90 minutes of downtime.
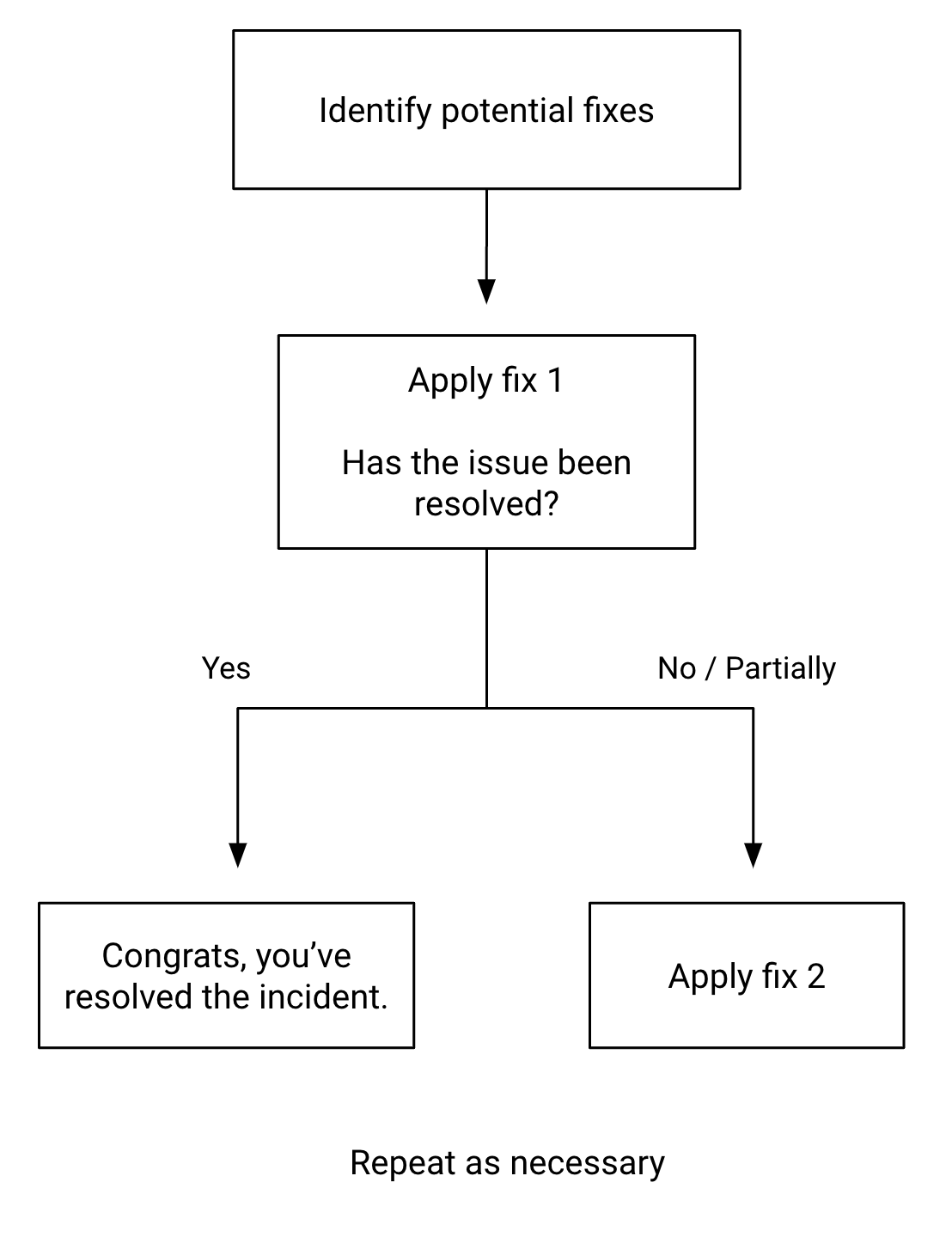
Apply Fixes One at a Time
Incidents that have a singular cause are relatively easy to approach: you find the mitigation, you apply it, and then you fix the problem. However, not all problems stem from a single cause. Symptoms may hide other problems, and issues that are benign on their own may be problematic when combined with other factors. The relationships between all these factors may not even be evident at first. Distributed systems are large and complex. A single person might not be able to thoroughly understand the full breadth of the system. To find a root cause in these cases we must rely on examining the results of controlled input to better understand what is going on; in essence, performing an experiment that a certain fix will produce a certain result. If you make two concurrent fixes, how do you know which one fixed the issue? How do you know one of the solutions didn’t make things worse?
In another outage, one of our services was suddenly receiving large bursts of traffic, leading to latency in our database calls. Our metrics showed that the database calls were taking a long time, but the database metrics were showing that the queries were completing within normal performance thresholds. We couldn’t even find the source of the traffic. After a great deal of digging, and a deep dive into the inner workings of TCP, we found the issue! Our database connection pool was not configured well for bursty traffic. We prepared to deploy a fix. In the spirit of addressing user pain and working in the areas they could control, another team was investigating the issue in parallel. They had discovered that a deployment of theirs coincided with when the outage had begun and were preparing to do a rollback. In the spirit of surfacing information, both teams were coordinating through the incident channel. Before we applied either fix, someone brought up that we should apply one fix first to see if it addressed the problem. We moved to apply the change to the connection pool, and to our joy and then immediate dismay, we had fixed the original issue but not the customer outage. Our service still couldn’t handle the volume of traffic it was receiving. At that point the other team applied their rollback and the traffic returned to normal.
By applying these fixes separately, we discovered both a connection pool misconfiguration and a bug that was causing an application to call our service many more times than it needed to. If we had simply rolled back the deployment, it was possible that in the future, similar traffic would cause our service to fail, creating another outage. With methodical application of fixes, you can better identify root causes in complex distributed systems.
Know Your Basics
Distributed systems are hard. As a beginner or even a more seasoned engineer, fully understanding them at scale is not something that our brains are made to do. These systems have a wide breadth, the pieces are complex, and they are constantly changing. However, all things in nature follow patterns, and distributed systems are no exception. You can use these to your advantage to know how to ask the right questions.
Distributed systems will often have centralized logging, metrics, and tracing. Microservices and distributed monoliths will often have API gateways or routers that provide a singular and consistent customer-facing interface to the disparate services that back them. These distributed services will likely make use of queueing mechanisms, cache stores, and databases. By having a high-level understanding of your implemented architecture, even without knowing all the complexity and nuance, you can engage the people on your team or at your company who do. A general surgeon knows how a heart works but may consult with a cardiothoracic surgeon if they find that the case requires more specialized knowledge. If you are familiar with the high-level architectural patterns in your application, you can ask the right questions to find the people with the information you need.
Parting Thoughts
We rely on healthcare professionals to treat us when the complex systems that are our bodies don’t work as we expect them to. We’ve come to rely on them as people who will methodically break down what happens in our bodies, put us back together, and heal our pain. As software developers, we don’t directly hold lives in our hands the way health workers do, but we must recognize that the world is becoming more and more dependent on the systems we build. People are building their lives around our systems with varying degrees of impact. We build entertainment systems like games and social media, but also we build systems that pay people, help them pay their bills, and coordinate transportation. When a game is down, maybe we go for a walk. When an outage fails to disburse a check, it could mean the difference between making rent and becoming homeless. If someone cannot pay obligations due to system downtime, it may have huge repercussions on their life. Responsible practice of our craft, including incident response, is how we acknowledge our responsibility to those who depend on us. Use these heuristics to center yourself on the people who rely on your systems. For their sake, keep calm and respond.
Opinions expressed by DZone contributors are their own.
Comments