Threads, ThreadPools, and Executors: Multi-Thread Processing In Java
This detailed description of how implementations of the Java Executor interface work focuses on relations between all of the Executors and their use cases.
Join the DZone community and get the full member experience.
Join For FreeConcurrency is one of the most complex problems we (developers) can face in our daily work. Additionally, it is also one of the most common problems that we may face while solving our day-to-day issues. The combination of both these factors is what truly makes concurrency and multithreading the most dangerous issues software engineers may encounter.

What is more, solving concurrency problems with low-level abstractions can be quite a cognitive challenge and lead to complex, nondeterministic errors. That is why most languages introduce higher-level abstractions that allow us to solve concurrency-related problems with relative ease and not spend time tweaking low-level switches.
In this article, I would like to dive deeper into such abstractions provided by the Java standard library, namely the ExecutorService interface and its implementations. I also want this article to be an entry point for my next article about benchmarking Java Streams.
Before that, let's have a quick recap on processes and threads:
What Is a Process?
It is the simplest unit that can be executed on its own inside our computers. Thanks to the processes, we can split the work being done inside our machines into smaller, more modular, and manageable parts.
Such an approach allows us to make particular parts more focused and thus more performant. A split like that also makes it possible to take full advantage of multiple cores build-in our CPUs.
In general, each process is an instance of a particular program — for example, our up-and-running Java process is a JVM program instance.
Moreover, each process is rooted inside the OS and has its own unique set of resources, accesses, and behavior (the program code) — similar to our application users.
Each process can have several threads (at least in most OS) that work together toward the completion of common tasks assigned by the process.
What Is a Thread?
It can be viewed as a branch of our code with a specific set of instructions that is executed in parallel to the work made by the rest of the application. Threads enable concurrent execution of multiple sequences of instructions within a single process.
On the software level, we can differentiate two types of threads:
- Kernel (System) threads: Threads are managed by the OS directly. The operating system kernel performs thread creation, scheduling, and management.
- Application (User) threads: Threads are managed at the user level by a thread library or runtime environment, independent of the operating system. They are not visible to the operating system kernel. Thus, the operating system manages them as if they were single-threaded processes.
Here, I will focus mostly on application threads. I will also mention CPU-related threads. These are the hardware threads, a trait of our CPUs. Its number describes the capabilities of our CPU to handle multiple threads simultaneously.
In principle, threads can share resources in a much lighter fashion than the processes. All threads within the process have access to all the data owned by its parent process.
Additionally, each thread can have its data known more commonly as thread-local variables (or, in the case of Java, newer and more recommended scoped values). What is more, switching between threads is much easier than in cases of processes.
What Is a Thread Pool?
A thread pool is a more concrete term than both thread and process. It is related to application threads and describes a set of such threads that we can use inside our application.
It works based on a very simple behavior. We just take threads one by one from the pool until the pool is empty. That’s it. However, there is an additional assumption to this rule, in particular, that the threads will be returned to the pool once their task is completed.
Of course, applications may have more than one thread pool, and in fact, the more specialized our thread pool is, the better for us. With such an approach, we can limit contention within the application and remove single points of failure. The industry standard nowadays is at least to have a separate thread pool for database connection.
Threads, ThreadPools, and Java
In older versions of Java — before Java 21 — all threads used inside the application were bound to CPU threads. Thus, they were quite expensive and heavy.
If by accident (or intent), you will spawn too many threads in your Java application; for example, via calling the “new Thread()”. Then you can very quickly run out of resources, and the performance of your application will decrease rapidly — as among others, the CPU needs to do a lot of context switching.
Project Loom, the part of the Java 21 release, aimed to address this issue by adding virtual threads — the threads that are not bound to CPU threads, so-called green threads — to the Java standard library. If you would like to know more about Loom and the changes it brings to Java threads I recommend this article.
In Java, the concept of the thread pools is implemented by a ThreadPoolExecutor — a class that represents a thread pool of finite size with the upper bound described by the maximumPoolSize parameter of the class constructor.
As a side note, I would like to add that this executor is used further in more complex executors as an internal thread pool.
Executor, ExecutorService, and Executors
Before we move to describe a more complex implementation of executor interfaces that utilize a ThreadPoolExecutor, there is one more question I would like to answer: namely, what are the Executor and ExecutorService themselves?
Executor
The Executor is an interface exposing only one method executed with the following signature: void execute(Runnable command). The interface is designed to describe a very simple operation - to be exact, that the class implementing it can do such an operation: execute a provided runnable. The interface's purpose is to provide a way of decoupling task submission from the mechanics of how the task will be run.
ExecutorService
The ExecutorService is yet another interface, the extension of the Executor interface. It has a much more powerful contract than the Executor.
With around 13 methods to override, if we decide to implement it, its main aim is to help with the management and running of asynchronous tasks via wrapping such tasks in Java Future.
Additionally, the ExecutorService extends the Autocloseable interface. This allows us to use ExecutorService in try-with-resource syntax and close the resource in an ordered fashion.
Executors
Executors class, on the other hand, is a type of util class. It is a recommended way of spawning new instances of the executors — using the new keyword is not recommended for most of the executors. What is more, it provides the methods for creating variations of callable instances, for example, callable with static return value.
With these three basic concepts described, we can move to different executor service implementations.
The Executor Services
As for now, the Java standard library supports 4 main implementations of the ExecutorService interface. Each one provides a set of more or less unique features.
They go as follows:
ThreadPoolExecutorForkJoinPoolScheduledThreadPoolExecutorThreadPerTaskExecutor
Additionally, there are three private statics implementations in the Executors class which implement ExecutorService:
DelegatedExecutorServiceDelegatedScheduledExecutorServiceAutoShutdownDelegatedExecutorService
Overall, the dependency graph between the classes looks more or less like this:

ThreadPoolExecutor
As I said before, it is an implementation of the thread pool concept in Java. This executor represents a bounded thread pool with a dynamic number of threads. What it exactly means is that TheadPoolExecutor will use a finite number of threads, but the number of used threads will never be higher than specified on pool creation.
To achieve that, ThreadPoolExecutor uses two variables: corePoolSize and maximumPoolSize. The first one — corePoolSize — describes the minimal number of threads in the pool, so even if the threads are idle, the pool will keep them alive.
On the other hand, the second one — maximumPoolSize — describes, as you probably guessed by now, the maximum number of threads owned by the pool. This is our upper bound of threads inside the pool. The pool will never have more threads than the value of this parameter.
Additionally, ThreadPoolExecutor uses BlockingQueue underneath to keep track of incoming tasks.
ThreadPoolExecutor Behavior
By default, if the current number of current up and running threads is smaller than corePoolSize, the calling of execute method will result in spawning a new thread with an incoming task as a thread’s first work to do — even if there are idle threads in the pool at the moment. If, for some reason, the pool is unable to add a new thread, the pool will move to behavior two.
If the number of running threads is higher or equal to the corePoolSize or the pool was unable to spawn a new thread, the calling of the execute method will result in an attempt to add a new task to the queue: isRunning(c) && workQueue.offer(command).
If the pool is still running, we add a new thread to the pool without any task first — the only case is when we are spawning a new thread without any task: addWorker(null, false);.
On the contrary, if the pool is not running, we remove the new command from the queue:
!isRunning(recheck) && remove(command)
Then the pool rejects the command with RejectedExecutionException: reject(command);.
If for some reason we cannot add a task to the queue, the pool is trying to start the new thread with a task as its first task: else if (!addWorker(command, false)).
If it fails to do it, the task is rejected, and the RejectedExecutionException is thrown with a message with a similar message.
Task X rejected from java.util.concurrent.ThreadPoolExecutor@3a71f4dd[Running, pool size = 1, active threads = 1, queued tasks = 0, completed tasks = 0]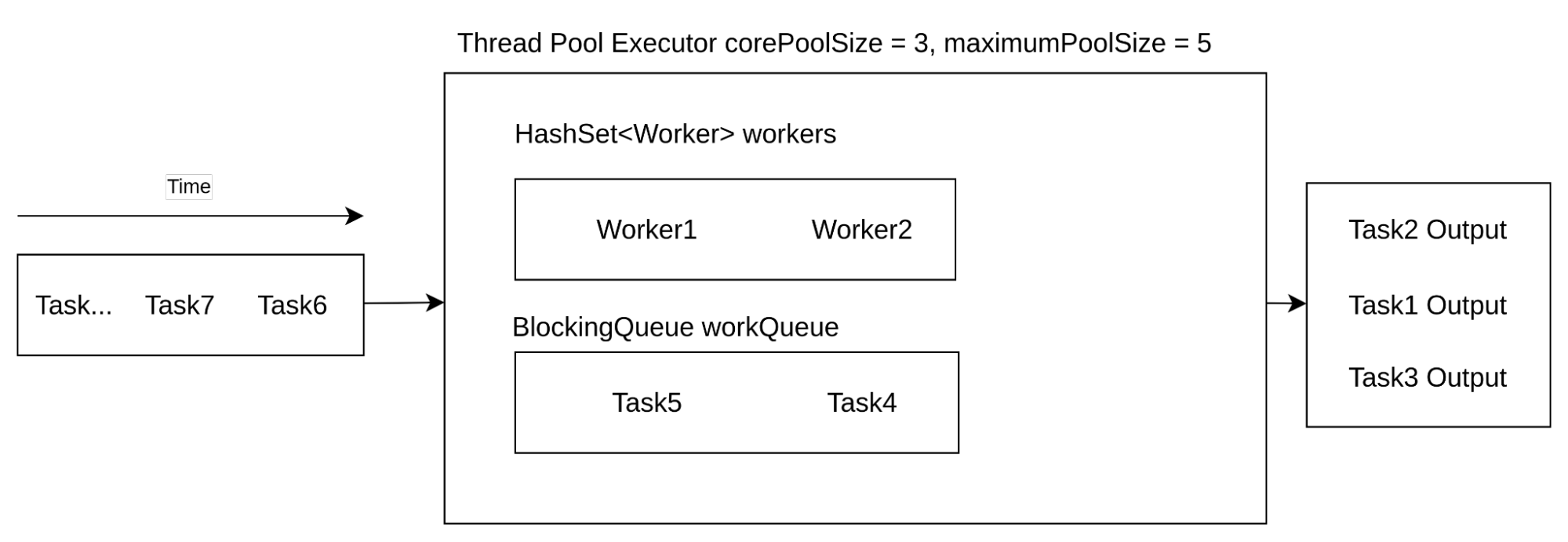
Above, you can see a very, very simplified visualization of ThreadPoolExecutor’s internal state. From here on out, you can expect two outcomes: either Task4 (or Task5) will be processed before submitting Task6 to the pool, or Task6 will be submitted to the pool before the end of Task4 (or Task5) processing.
The first scenario is quite boring, as everything stays the same from the perspective of the executor, so I will only spend a little time on this.
The second scenario is much more interesting as it will result in a change of executor state. Because the current number of running threads is smaller than corePoolSize, submitting Task6 to the executor will result in spawning a new worker for this task. The final state will look more or less like the one from below.
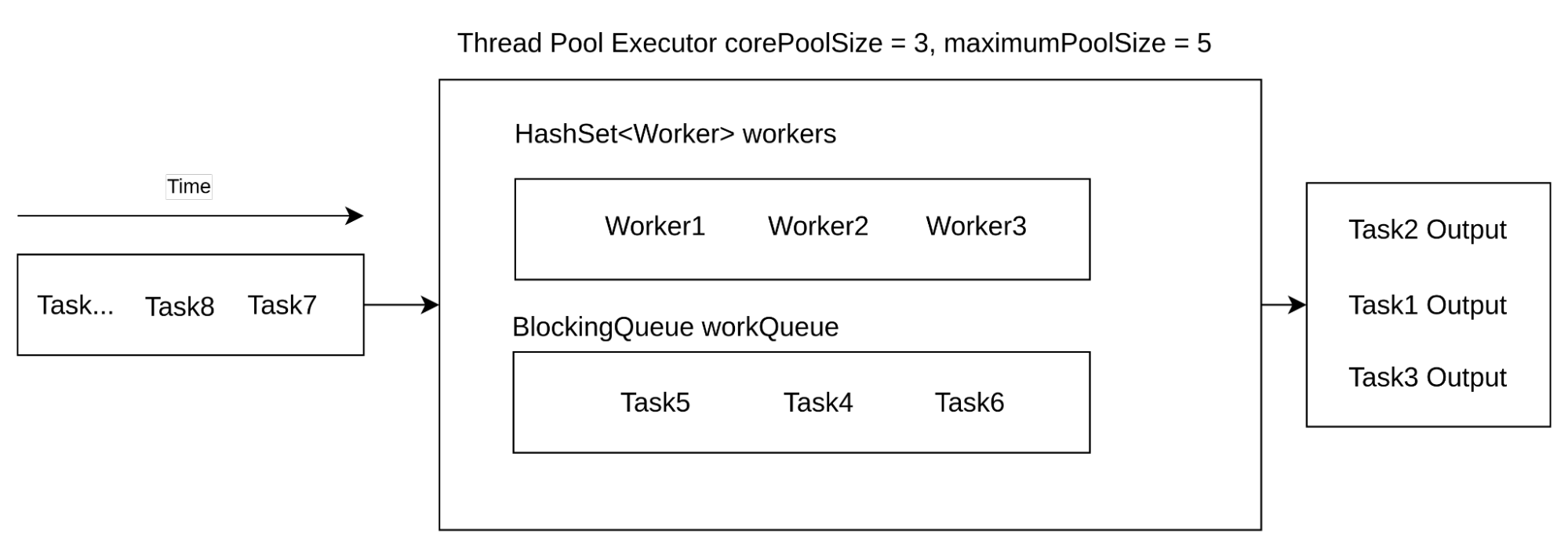
ThreadPoolExecutor Pool Size
- Fixed-size pool: By setting
corePoolSizeandmaximumPoolSizeto the same value, you can essentially create a fixed-size thread pool, and the number of threads run by the pool will never go below or above the set value — at least not for long. - Unbounded pool: By setting
maximumPoolSizeto a high enough value such asInteger.MAX_VALUE— you can make it practically unbounded. There is a practical limit of around 500 million ((2²⁹)-1) threads coming fromThreadPoolExecutorimplementation. However, I bet that your machine will be down before reaching the max.
If you would like to know more about the reasoning behind such a number being the limit, there is a very nice JavaDoc describing this. It is located just after the declaration of the ThreadPoolExecutor class. I will just drop a hint that it is related to the way how ThreadPoolExecutor holds its state.
Spawning ThreadPoolExecutor
Executors class gives you a total of 6 methods to spawn the ThreadPoolExecutor. I will describe them in the two packages, as that is how they are designed to work.
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
These methods create a fixed-size thread pool — size core and max are equal. Additionally, you can pass a threadFactory as an argument if you prefer not to use the default one from the standard library.
Executors.newFixedThreadPool(2);
Executors.newFixedThreadPool(2, Executors.defaultThreadFactory());
The batch of the next two methods:
public static ExecutorService newCachedThreadPool()
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
The methods above create de facto unbounded thread pools by setting the maxPollSize to Integer.Max; the second version is similar to the FixThreadPool, allowing the passing of a customized ThreadFactory.
Executors.newCachedThreadPool();
Executors.newCachedThreadPool(Executors.defaultThreadFactory());
And the last two methods:
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
Both methods create a thread pool that uses a single thread. What is more, methods spawn a ThreadPoolExecutors that is wrapped in AutoShutdownDelegatedExecutorService. It only exposes methods of ExecutorService: no ThreadPoolExecutor specific methods are available.
Moreover, the shutdown method is overridden with the help of Cleanable and is called when it becomes Phantom reachable.
ThreadPoolExecutor Adding New Tasks
The default way of adding new tasks to be executed by a ThreadPoolExecutor is to use one of the versions of the submit method. On the other hand, one may also use the execute method from the Executor interface directly. However, it is not the recommended way.
Using the execute method will return void, not the future: it means that you would have less control over its execution, so the choice is yours. Of course, both approaches will trigger all the logic described above with the thread pool.
Runnable task = () -> System.out.print("test");Future<?> submit = executorService.submit(task);
vs
executorService.execute(task);
ForkJoinPool
ForkJoinPool is a totally separate ExecutorService implementation whose main selling point is the concept of work stealing.
Work stealing is quite a complex concept worthy of a solely focused blog post. However, it can be reasonably simply described with high enough abstractions — all threads within the pool try to execute any task submitted to the pool, no matter its original owner.
That is why the concept is called work stealing, as the threads “steal” each other’s work. In theory, such an approach should result in noticeable performance gains, especially if submitted tasks are small or spawn other subtasks.
In the near future, I am planning to publish a separate post solely focused on work-stealing and ForkJoinFramework. Until then, you can read more about work stealing here.
ForkJoinPool Behavior
This executor is a part of the Java Fork/Join framework introduced in Java 7, a set of classes aimed to add more efficient parallel processing of tasks by utilizing the concept of work stealing. Currently, the framework is extensively used in the context of CompletableFuture and Streams.
If you want to get the most out of the ForkJoinPool, I would recommend getting familiar with the Fork/Join framework as a whole. Then, try to switch your approach to handling such tasks to one that is more in line with Fork/Join requirements.
Before going head-on into the Fork/Join framework, please do benchmarks and performance tests, as potential gains may not be as good as expected.
Additionally, there is a table in ForkJoinPool Java docs describing the method one should use for interacting with ForkJoinPool to get the best results.
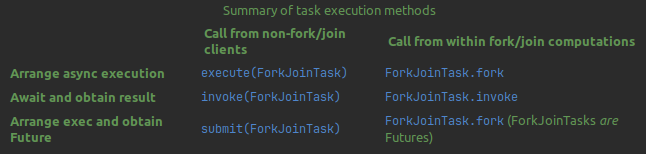
The crucial parameter in the case of ForkJoinPool is parallelism — it describes the number of worker threads the pool will be using. By default, it is equal to the number of available processors on your CPU. In most cases, it is at least a sufficient setup, and I would recommend not changing it without proper performance tests.
Keep in mind that the Java threads are CPU-bound, and we can quickly run out of processing power to progress in our task.
Spawning ForkJoinPool Instances
The Executors class provides two methods for spawning instances of ForkJoinPool:
Executors.newWorkStealingPool();
Executors.newWorkStealingPool(2);
The first one creates the forkJoinPoll with default parallelism — the number of available processors — while the second gives us the possibility to specify the parallelism level ourselves.
What is more, Executors spawn ForkJoinPool with FIFO queue underneath while the default setting of ForkJoinPool itself (for example, via new ForkJoinPool(2)) is LIFO. Using LIFO with Executors is impossible. Despite that, you can change the type of underlain queue by using the asyncMode constructor parameter of the ForkJoinPool class.
With the FIFO setting, the ForkJoinPool may be better suited for the tasks that are never joined — so for example, for callable or runnable usages.
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor adds a layer over the classic ThreadPoolExecutor and allows for scheduling tasks.
It supports three types of scheduling:
- Schedule once with a fixed delay -
schedule - Schedule with every number of time units -
scheduleAtFixedRate - Schedule with a fixed delay between execution -
scheduleWithFixedDelay
For sure, you can also use the “normal” ExecutorService API. Just remember that in this case, methods submit and execute are equal to calling the schedule method with 0 delay — instant execution of the provided task.
As ScheduledThreadPoolExecutor extends ThreadPoolExecutor, some parts of its implementation are the same as in classic ThreadPoolExecutor. Nevertheless, it is using its own implementation of task ScheduledFutureTask and queue: DelayedWorkQueue.
What is more, ScheduledThreadPoolExecutor always creates a fixed-size ThreadPoolExecutor as its underlying thread pool, so corePoolSize and MaxPoolSize are always equal.
There is, however, a catch or two hidden inside the implementation of ScheduledThreadPoolExecutor.
- Firstly, if two tasks are scheduled to run (or end up scheduled to be run) at the same time, they are executed in FIFO style based on submission time.
- The next catch is the logical consequence of the first. There are no real guarantees that a particular task will execute at a certain point in time — as, for example, it may wait in a queue from the line above.
- Last but not least, if for some reason the execution of two tasks should end up overlapping each other, the thread pool guarantees that the execution of the first one will “happen before” the later one. Essentially, in FIFO fashion, even with respect to the tasks being called from different threads.
Spawning ScheduledThreadPoolExecutor
The Executors class gives us five ways to spawn the ScheduledThreadPoolExecutor. They are organized in a similar fashion to those of ThreadPoolExecutor.
ScheduledThreadPoolExecutor with a fixed number of threads:
Executors.newScheduledThreadPool(2);
Executors.newScheduledThreadPool(2, Executors.defaultThreadFactory());
The first method allows us to create a ScheduledThreadPoolExecutor with a particular number of threads. The second method adds availability to pass the ThreadFactory of choice.
ScheduledThreadPoolExecutor with a single thread:
Executors.newSingleThreadScheduledExecutor();
Executors.newSingleThreadScheduledExecutor(Executors.defaultThreadFactory());
Create a SingleThreadScheduledExecutor whose underlying ThreadExecutorPool has only one thread. In fact, here we spawn the instance of DelegatedScheduledExecutorService, which uses ScheduledThreadPoolExecutor as a delegate, so in the end, the underlying ThreadExecutorPool of a delegate has only one thread.
The last way to spawn the ScheduledThreadPoolExecutor is via using:
Executors.unconfigurableScheduledExecutorService(new DummyScheduledExecutorServiceImpl());
This method allows you to wrap your own implementation of the ScheduledExecutorService interface with DelegatedScheduledExecutorService — one of the private static classes from the Executors class. This one only exposes the methods of the ScheduledExecutorService interface.
To a degree, we can view it as an encapsulation helper. You can have multiple public methods within your implementation, but when you wrap it with the delegate, all of them will become hidden from the users.
I am not exactly a fan of such an approach to encapsulation. It should be the problem of implementation. However, maybe I am missing some other important use cases of all of the delegates.
ThreadPerTaskExecutor
It is one of the newest additions to the Java standard library and Executors class. It is not a thread pool implementation, but rather a thread spawner. As the name suggests, each submitted task gets its own thread bound to its execution, the thread starts alongside the start of task processing.
To achieve such behavior, this executor uses its own custom implementation of Future, namely, ThreadBoundFuture. The lifecycle of threads created by these executors looks more or less like this:
- The thread is created as soon as the
Futureis created. - The thread starts working only after being programmatically started by the
Executor. - The thread is interrupted when the
Futureis interrupted. - Thread is stopped on
Futurecompletion.
What is more, if the Executor is not able to start a new thread for a particular task and no exception is thrown along the way, then the Executor will RejectedExecutionException.
Furthermore, the ThreadPerTaskExecutor holds a set of up-threads. Every time the thread is started, it will be added to the set. Respectively, when the thread is stopped, it will be removed from the set.
You can then use this set to keep track of how many threads the Executor is running at the given time via the threadCount() method.
Spawning ThreadPerTaskExecutor
The Executors class exposes two ways of spawning this Executor. I would say that one is more recommended than the other. Let’s start with the not-recommended one:
Executors.newThreadPerTaskExecutor(Executors.defaultThreadFactory());
The above method spawns ThreadPerTaskExecutor with the provided thread factory. The reason why it is not recommended, at least by me, is that the instance ThreadPerTaskExecutor will operate on plain old Java CPU-bound threads.
In such a case, if you put a high enough number of tasks through the Executor, you can very, very easily run out of processing power for your application.
Certainly, nothing stands in your way of doing the following “trick” and use virtual threads anyway.
Executors.newThreadPerTaskExecutor(Thread.ofVirtual().factory());
However, there is no reason to do that when you simply can use the following:
Executors.newVirtualThreadPerTaskExecutor();
This instance of ThreadPerTaskExecutor will take full advantage of virtual threads from Java 21. Such a setting should also greatly increase the number of tasks that your Executor will be able to handle it before running out of processing power.
Summary
As you can see, Java provides a set of different executors, from classic ThreadPool implementation via ThreadPoolExecutor to more complex ones like ThreadPerTaskExecutor, which takes full advantage of virtual threads, a feature from Java 21.
What is more, each Executor implementation has its unique trait:
ThreadPoolExecutor: ClassicThreadPoolimplementationForkJoinPool: Work-stealingScheduledThreadPoolExecutor: Periodical scheduling of tasksThreadPerTaskExecutor: Usage of virtual threads and the possibility to run a task in its separate short-lived thread
Despite that difference, all of the executors have one defining trait: all of them expose an API that makes concurrent processing of multiple tasks much easier.
I hope that this knowledge will become useful for you sometime in the future. Thank you for your time.
Note: Thank you to Michał Grabowski and Krzysztof Atlasik for the review.
Published at DZone with permission of Bartłomiej Żyliński. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments