Aggregate Millions of Database Rows in a Spring Controller
Learn how to perform ultra-fast aggregations in Java with Spring and Speedment—even with large datasets with millions of rows.
Join the DZone community and get the full member experience.
Join For FreeThe Spring Framework makes it really easy to quickly set up a RESTful API to a relational database using JPA and Spring Web, as long as the API matches the structure of the database. In many APIs, however, the REST-endpoint doesn't correspond to a particular table but rather an aggregate of the fields. In those cases, you still need to write your own REST Controllers, but if the database has millions of rows, then those aggregates might take some time to compute.
In this article, I will show you how to write a very efficient REST Controller representing a JSON aggregate by using the json-stream plugin in Speedment Enterprise to quickly aggregate large JSON sequences without materializing them on the heap. The demo uses the Enterprise Edition of Speedment, for which you can get a free trial using the Initializer on the Speedment Website.
Background
Speedment is an open source stream-oriented ORM for Java that generates entity and manager classes using a relational database as the source-of-truth. The data is then queried using standard Java 8 streams, without a single line of SQL.
Speedment Enterprise adds a highly efficient in-JVM-memory datastore to this ORM. Instead of translating the streams to SQL, the streams can be executed natively on the in-memory model. To avoid garbage collection limitations, entities are stored in DirectBuffers outside the main heap. Only the columns used in the stream need to be materialized on the heap, and most predicates can be short-circuited without iterating over the entire set.
json-stream is an official plugin for Speedment Enterprise that makes it possible to aggregate Speedment streams as JSON objects in a very efficient manner. It is different from, for example, Jackson and Gson in that it knows the internal storage layout used in Speedment Enterprise and therefore doesn't need to materialize the entities to aggregate them into JSON.
Introduction
In this article, I am using an example database called Employees designed for MySQL to illustrate a common aggregation problem. A company keeps records on the salary of each employee going back to 1985. They want to be able to select a time period and see what the average salary was during that time, based on the criteria specified by the user.
Using regular SQL, we can express it like this:
mysql> select count(emp_no),min(from_date),max(to_date),avg(salary)
from salaries where from_date < '1989-01-01'
and to_date >= '1988-01-01';
+---------------+----------------+--------------+-------------+
| count(emp_no) | min(from_date) | max(to_date) | avg(salary) |
+---------------+----------------+--------------+-------------+
| 133923 | 1987-01-01 | 1989-12-31 | 55477.8502 |
+---------------+----------------+--------------+-------------+
1 row in set (0.66 sec)If we want to create a simple REST service in Spring that performs this calculation and returns it as a JSON Object, we could do the following:
@GetMapping
Result getEmployeeSalaries(@RequestParam String from,
@RequestParam String to) {
return template.queryForObject(
"select count(emp_no),min(from_date),max(to_date),avg(salary) " +
"from salaries where from_date < ? and to_date >= ?;",
(rs, n) -> new Result(rs),
to, from
);
}The Result class is defined like this (using Project Lombok to reduce boilerplate):
@Data
static class Result {
private final long count;
private final String from, to, average;
Result(ResultSet rs) throws SQLException {
count = rs.getLong(1);
from = rs.getString(2);
to = rs.getString(3);
average = Utils.CASH.format(rs.getDouble(4));
}
}If we now point the browser to /jdbc?from=1988-01-01&to=1989-01-01, we will see the aggregated result:
{
"count": 133923,
"from": "1987-01-01",
"to": "1989-12-31",
"average": "$55,477.85"
}However, the performance is far from the best. This simple service takes about 700 ms to produce the aggregate.

Of course, we could cache the most common queries on the server, but it would still take us time to calculate results that have never been requested. Instead, let's try to rewrite the same service, but with Speedment.
Step 1: Configuration
I have prepared a Speedment configuration file and put the /src/main/json folder into my project. I can then call mvn speedment:generate to generate all necessary entities and managers.
Next, we need to configure the Speedment application. To do this, I created a file called SpeedmentConfig.java like this:
@Configuration
public class SpeedmentConfig {
private final Environment env;
SpeedmentConfig(Environment env) {
this.env = requireNonNull(env);
}
@Bean(destroyMethod = "stop")
EmployeesApplication getApplication() {
return new EmployeesApplicationBuilder()
.withConnectionUrl(env.getProperty("spring.datasource.url"))
.withUsername(env.getProperty("spring.datasource.username"))
.withPassword(env.getProperty("spring.datasource.password"))
.withBundle(DataStoreBundle.class)
.withBundle(JsonBundle.class)
.build();
}
...
}The username and password are set in the Spring application.properties file. I still need to define three additional beans, however. We need a Manager so that I can query the Salaries-table, a DataStoreComponent that allows us to initialize the Speedment DataStoreComponent, and a JsonComponent so that we can setup custom JSON aggregators.
@Bean
DataStoreComponent getDataStoreComponent(EmployeesApplication app) {
return app.getOrThrow(DataStoreComponent.class);
}
@Bean
JsonComponent getJsonComponent(EmployeesApplication app) {
return app.getOrThrow(JsonComponent.class);
}
@Bean
SalaryManager getSalaryManager(EmployeesApplication app) {
return app.getOrThrow(SalaryManager.class);
}We have now integrated Speedment with Spring!
Step 2: Controller Class
Let's take a look at the Controller- class. First, we need to make these three beans accessible in the controller by autowiring them. I prefer to have all my member variables final, so I will use Project Lombok to generate an all-argument constructor.
@RestController
@AllArgsConstructor
@RequestMapping("/speedment")
public class SpeedmentController {
private final SalaryManager salaries;
private final DataStoreComponent datastore;
private final JsonComponent json;
...
}Next, we need to tell Spring to populate the in-memory store as soon as the beans have been initialized. We can do this with the @PostConstruct-annotation.
@PostConstruct
void loadInitialState() {
datastore.load();
}The controller logic is pretty much the same as earlier, except that we will use a Java 8 Stream to query the database instead of a SQL String. The big advantage of this is that we can add more criteria to the service later on with very little modifications to the code. Filtering the stream is as simple as adding a .filter() operation.
@GetMapping
String getEmployeeSalaries(@RequestParam String from,
@RequestParam String to) {
return salaries.stream()
.filter(Salary.FROM_DATE.lessThan(Utils.toEpochSecond(to)))
.filter(Salary.TO_DATE.greaterOrEqual(Utils.toEpochSecond(from)))
.collect(
json.collector(Salary.class)
.put("count", count())
.put("from", min(Salary.FROM_DATE, Utils::fromEpochSecond))
.put("to", max(Salary.TO_DATE, Utils::fromEpochSecond))
.put("average", average(Salary.SALARY, Utils::toCurrency))
.build()
);
}(I have mapped the dates to epoch second integers in Speedment for performance reasons. That is why you see Utils.toEpochSecond and Utils.fromEpochSecond in the logic above).
Step 3: Re-Deploy
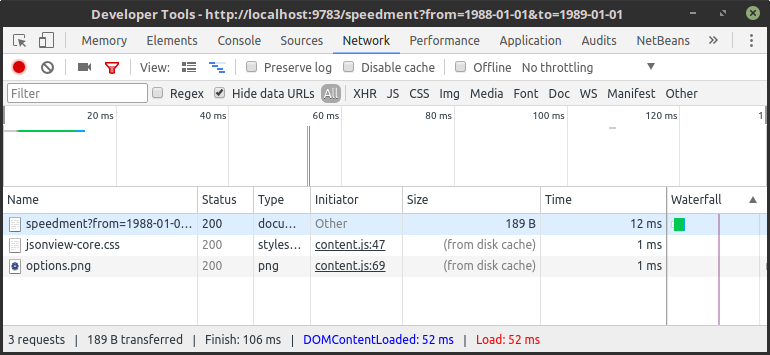
If we rerun the service, we can see that the endpoint still works just as before:
{
"count": 133923,
"from": "1987-01-01",
"to": "1989-12-31",
"average": "$55,477.85"
}The difference is that the request is 60 times faster. Imagine what a speedup factor of 60 would do to your existing applications: For example, instead of a10-second delay, you get a delay of less than 200 ms, which is hardly noticeable by end users.
Conclusion
JSON aggregation of relational data in Spring can be done very efficiently using Speedment Enterprise with the datastore and json-stream plugins. It fits nicely with other Spring components and is very easy to set up.
If you want to try this example for yourself, you can download it from this GitHub page. You can get a free trial of Speedment Enterprise on the Speedment website.
Published at DZone with permission of Emil Forslund, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments