Be Aware: Floating Point Operations on ARM Cortex-M4F
Check out this post to learn more about floating data types in embedded applications.
Join the DZone community and get the full member experience.
Join For FreeMy mantra is *not* to use any floating point data types in embedded applications, or at least to avoid them whenever possible: for most applications, they are not necessary and can be replaced by fixed point operations. Not only floating point operations have numerical problems, but they can also lead to performance problems as in the following (simplified) example:
#define NOF 64
static uint32_t samples[NOF];
static float Fsamples[NOF];
float fZeroCurrent = 8.0;
static void ProcessSamples(void) {
int i;
for (i=0; i<NOF; i++) {
Fsamples[i] = samples[i]*3.3/4096.0 - fZeroCurrent;
}
}ARM designed the Cortex-M4 architecture in a way it is possible to have an FPU added. For example, the NXP ARM Cortex-M4 on the FRDM-K64F board has an FPU present.

MK64FN1M0VLL12 on FRDM-K64F
The question is: how long will that function need to perform the operations?
Looking at the loop, it does:
Fsamples[i] = samples[i]*3.3/4096.0 - fZeroCurrent; Which is to load a 32-bit value, then perform a floating point multiplication, followed by a floating point division and floating point subtraction, then store the result back in the result array.
The NXP MCUXpresso IDE has a cool feature showing the number of CPU cycles spent (see Measuring ARM Cortex-M CPU Cycles Spent with the MCUXpresso Eclipse Registers View). So, running that function (without any special optimization settings in the compiler takes:

Cycle Delta
0x4b9d or 19’357 CPU cycles for the whole loop. Measuring only one iteration of the loop takes 0x12f or 303 cycles, one might wonder why it takes such a long time, as we do have an FPU?
The answer is in the assembly code: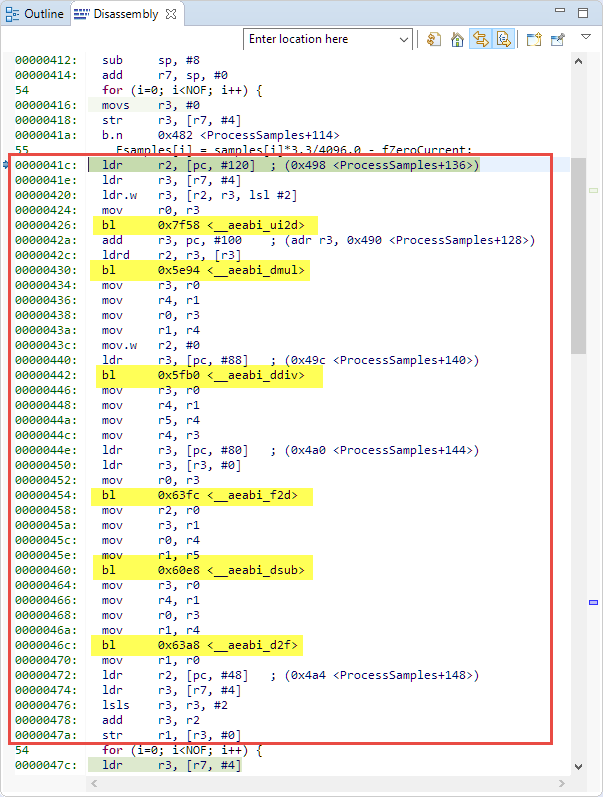
This actually shows that it does not use the FPU but, instead, uses software floating point operations from the standard library?
The answer is the way the operation is written in C:
Fsamples[i] = samples[i]*3.3/4096.0 - fZeroCurrent;We have here a uint32_t multiplied with a floating point number:
samples[i]*3.3The thing is that a constant as ‘3.3’ in C is of type *double*. As such, the operation will first convert the uint32_t to a double, and then perform the multiplication as double operation.
Same for the division and subtraction: it will be performed as double operation:
samples[i]*3.3/4096.0Same for the subtraction with the float variable: because the left operation result is double, it has to be performed as double operation.
samples[i]*3.3/4096.0 - fZeroCurrentFinally, the result is converted from a double to a float to store it in the array:
Fsamples[i] = samples[i]*3.3/4096.0 - fZeroCurrent;Now, the library routines called should be clear in the above assembly code:
- __aeabi_ui2d: convert unsigned int to double
- __aeabi_dmul: double multiplication
- __aeabi_ddiv: double division
- __aeabi_f2d: float to double conversion
- __aeabi_dsub: double subtraction
- __aeabi_d2f: double to float conversion
But why is this done in software and not in hardware, as we have an FPU?
The answer is that the ARM Cortex-M4F has only a *single precision* (float) FPU, and not a double precision (double) FPU. As such, it only can do float operations in hardware but not for double type.
The solution, in this case, is to use float (and not double) constants. In C, the ‘f’ suffix can be used to mark constants as float:
Fsamples[i] = samples[i]*3.3f/4096.0f - fZeroCurrent;With this, the code changes to this:

Using Single Precision FPU Instructions
So now, it is using single precision instructions of the FPU. This only takes 0x30 (48) cycles for a single iteration or 0xc5a (3162) for the whole thing: 6 times faster.
The example can be even further optimized with:
Fsamples[i] = samples[i]*(3.3f/4096.0f) - fZeroCurrent;Other Considerations
Using float or double is not bad per se: it all depends on how it is used and if they are really necessary. Using fixed-point arithmetic is not without issues, and standard sin/cos functions use double, so you don’t want to re-invent the wheel.
CENTIVALUES
One way to use a float type say for a temperature value:
floattemperature; /* e.g. -37.512 */Instead, it might be a better idea to use a ‘centi-temperature’ or ‘milli’ integer variable type:
int32_t centiTemperature; /* -37512 corresponds to -37.512 */That way, normal integer operations can be used.
GCC SINGLE PRECISION CONSTANTS
The GNU GCC compiler offers to treat double constants as 3.0 as single precision constants (3.0f) using the following option:
-fsingle-precision-constant causes floating-point constants to be loaded in single precision even when this is not exact. This avoids promoting operations on single precision variables to double precision like in x + 1.0/3.0. Note that this also uses single precision constants in operations on double precision variables. This can improve performance due to less memory traffic.
See https://gcc.gnu.org/wiki/FloatingPointMath
RTOS
The other consideration is: if using the FPU, it means potentially stacking more registers. This is a possible performance problem for an RTOS like FreeRTOS (see https://www.freertos.org/Using-FreeRTOS-on-Cortex-A-Embedded-Processors.html). The ARM Cortex-M4 supports a ‘lacy stacking’ (see https://stackoverflow.com/questions/38614776/cortex-m4f-lazy-fpu-stacking). So, if the FPU is used, it means more stacked registers. If no FPU is used, then it is better to select the M4 port in FreeRTOS:

M4 and M4F in FreeRTOS
Summary
I recommend not to use any float and double data types if not necessary. And if you have an FPU, pay attention if it is only a single precision FPU, or if the hardware supports both single and double precision FPU. If having a single precision FPU only, using the ‘f’ suffix for constants and casting things to (float) can make a big difference. But keep in mind that float and double have different precision, so this might not solve every problem.
Happy Floating!
PS: If in need for a double precision FPU, have a look at the ARM Cortex-M7 (e.g. First steps: ARM Cortex-M7 and FreeRTOS on NXP TWR-KV58F220M or First Steps with the NXP i.MX RT1064-EVK Board)
Links
- Measuring ARM Cortex-M CPU Cycles Spent with the MCUXpresso Eclipse Registers View
- Cycle Counting on ARM Cortex-M with DWT
- MCUXpresso IDE: http://mcuxpresso.nxp.com/ide/
- DWT Registers: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0439b/BABJFFGJ.html
- DWT Control Register: http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0337e/ch11s05s01.html
Published at DZone with permission of Erich Styger, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments