Elasticsearch Client: Handling Scale and Backpressure
When scaling a high volume of records, Elasticsearch can experience backpressure and data loss. Learn about methods for dealing with this and related issues.
Join the DZone community and get the full member experience.
Join For FreeElasticsearch is a full-text search engine where JSON documents are stored, indexed, and are searchable.
Our Elasticsearch cluster consists of 14 nodes. The current scale we operate at is around 54,000 documents per second, a total of 4.6 billion records or 5TB of data per day.

Components
- Data source
- Application: Data processing/enriching
- Data source: Elasticsearch
Problem Statement
a. If you are trying to scale to thousands of records per second, then you might experience some data loss. The application might not be able to hold on to thousands of records per second and might end up dropping them or crashing due to running out of heap memory.
b. If the number of messages sent is much higher than the indexing rate, Elasticsearch rejects those messages and responds with TOO_MANY_REQUESTS (429) response codes.
Solution
We need to handle the following cases:
- A way to handle thousands of records per second input data in real time
- Avoid any data drop
- Scale as the input increases
- Zero application downtime
- Handle backpressure
Use a Distributed Queue
Introducing a distributed queue will help to deal with the huge number of incoming records. The application can dequeue a limited number of records that it is able to process. This avoids the application receiving an overwhelming amount of data.

Use Multiple Instances of an Application
Using a distributed queue like Apache Kafka, we can scale up by spawning additional instances of the application to handle the increase in data load. As long as they have the same consumer group id, every newly spawned instance will start dequeuing messages from Apache Kafka.
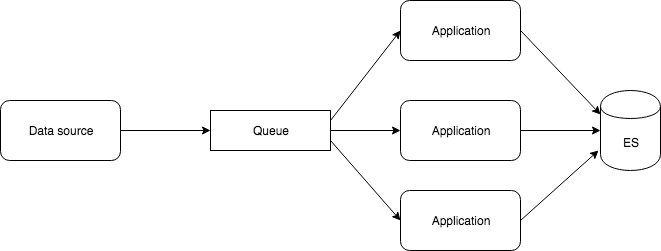
If the application is down, messages can be queued up until the system is ready to process them and push them into Elasticsearch for storing and indexing.
Use Bulk Requests
While dealing with huge volumes of data, a bulk request is preferred. Start by pushing a batch of roughly 5MB and keep increasing the size until there is no more performance gain. If Elasticsearch sends a TOO_MANY_REQUESTS (429) response code or EsRejectedExecutionException with the Java client, that's an indication that the indexing rate is higher than what the cluster can handle. When this situation arises, pause indexing for a bit and try with exponential backoff.
Use Multiple Workers/Threads to Send Data to Elasticsearch
In every application, use multiple threads to push bulk messages concurrently.
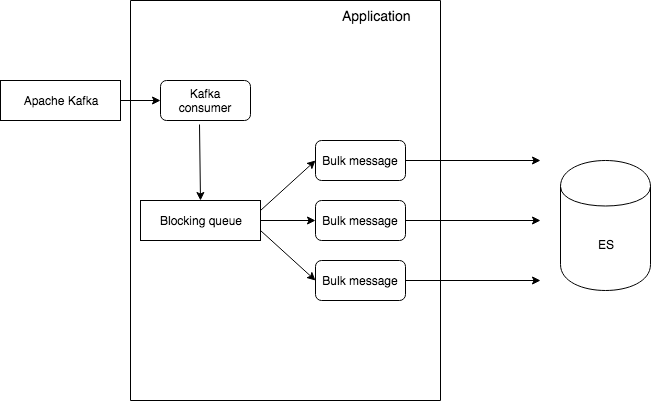
For example, if you want to push 20 parallel bulk requests containing 5,000 messages each, 20 * 5,000 = 100,000 messages in total. The worker threads will automatically pick up messages from their respective queues and start pushing them to Elasticsearch.
Use blocking queues. If the queue is empty, queue consumer threads to wait until data is pushed into the queue. If the queue is full, the queue producer threads wait until there is space to push new messages into the queue.
Opinions expressed by DZone contributors are their own.
Comments