Eventual Consistency Part 2: Anti-Entropy
Let's check out what anti-entropy (AE) is as well as explore eventual consistency and look at an example.
Join the DZone community and get the full member experience.
Join For FreeIn this article series, we're going to explore eventual consistency, a term that can be hard to define without having all the right vocabulary. This is the consistency model used by many distributed systems, including InfluxDB Enterprise edition. There are two concepts required to understand eventual consistency: the hinted handoff queue and anti-entropy, both of which deserve special attention.
Note: Part 1 of this series goes into depth on the concept of eventual consistency and why it matters in distributed computing. You can read Part 1 here for a refresher.
Part 2
What is anti-entropy?
If you read up on the Hinted Handoff queue in Part 1 of this series, you already know how the Hinted Handoff queue can save data during a data node outage and help you ensure eventual consistency, but there are a lot of ways for things to go wrong in distributed systems. Despite our best efforts, there are still ways to lose data, and we want to minimize this whenever possible. Enter the second half of maintaining eventual consistency: anti-entropy (AE).
If we're against entropy, we should know a little bit about what it is. According to the internet and my science-minded friends, entropy is defined by the second law of thermodynamics. Basically, ordered systems tend toward a higher state of entropy over time; therefore, the higher the entropy, the greater the disorder. We are against disorder in our time series data, hence anti-entropy.
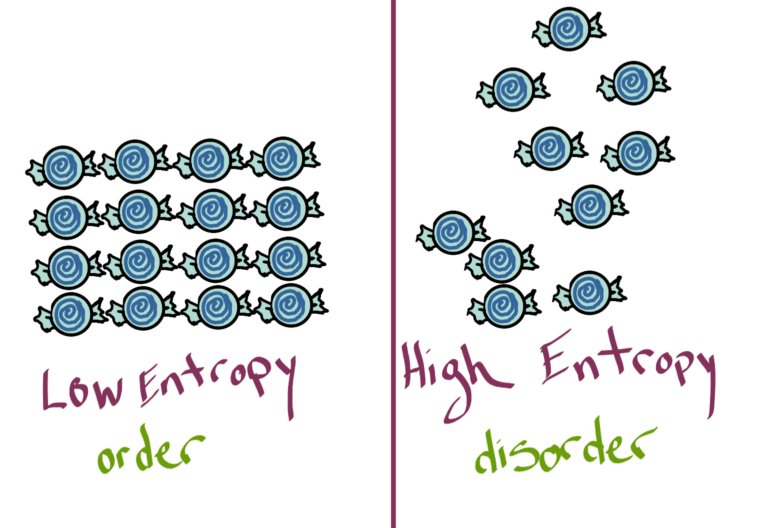
Delicious physics
Forget any intimidation factor the word itself has-anti-entropy is simply a service we can run in InfluxEnterprise to check for inconsistencies. We know that when we ask for information from a distributed system, the answer we receive may not be consistently returned. Because of the wide variety of ways in which "drift" can be introduced, we need a hero that can identify and repair underlying data discrepancies. AE can be that hero.
Example 1
Let's bring back our classic cluster: InfluxDB Enterprise with 2 data nodes and a database with a replication factor = 2.

The system is healthy and happy, sending data along to be stored and replicated. This is the happily ever after for our data, but sometimes we have to work to make that happen. Distributed systems change frequently, and dealing with that change is often what disturbs consistency in the first place.
One of the most common changes in a system is hardware, so let's explore one path where the new and improved AE can make a difference. Let's say Node 2 has some bad hardware. Maybe it's defective or just old, but it gives up the ghost in the middle of the night (because of course, it will be in the middle of the night).

Just a little defective
When Node 2 goes offline, any new writes are sent to the HHQ, where they wait for Node 2 to become available again. Reads get directed to Node 1, which has all of the same data as Node 2 (because of our RF = 2).

This is the origin story of our hero, Anti-Entropy, which was developed as a solution to all of the edge cases we could think of, and hopefully, lots that we haven't.

In our example, our first priority is getting Node 2 back online so that it can resume its rightful place in the system reading and writing data. We can use the "replace-node" command in InfluxEnterprise to rejoin Node 2 with its new hardware.
In this case, AE checks the combination of the replication factor and shard distribution to see if all the shards that should exist are appropriately replicated. In this case, since Node 2 has a new, fast, empty, and defect-free SSD, all the shards that exist on Node 1 are copied to Node 2 and any data waiting in the HHQ is quickly drained. Our AE hero has ensured both nodes will return the same information and the appropriate number of replicas exist. Huzzah!
Example 2
But the HHQ can't keep holding data forever-it has some practical limits. In InfluxEnterprise, it defaults to 10GB, meaning that if the size exceeds 10GB, the oldest points will get dropped to make room for newer data. Alternately, if data sits in the HHQ for too long, (default in InfluxEnterprise is 168hrs), it will be dropped. The HHQ is meant for temporary outages and fixes that can be quickly addressed, so it shouldn't fill indefinitely. It addresses the most common scenarios, but the HHQ can only bear so much of the burden.

In scenarios that have longer "failures," there is more room for data drift between the two nodes that we want to be identical. If a node is down and goes undetected for an extended period of time, the HHQ could exceed storage, time limit, concurrency, or rate limits, in which case the data it was meant to forward on vanishes into oblivion. Not ideal. Of course, there are a large number of potential edge cases that could happen: the goal of the HHQ and AE service is to provide a way to ensure eventual consistency with minimal effort from humans.
In other systems, once Node 2 disappears, it becomes the user's responsibility to make sure that node is repaired and brought back into a consistent state, probably by manually identifying and copying data. Let's be real: who has time for that? We have jobs to do and waffles to eat.

Or both!
Starting in InfluxEnterprise 1.5, AE examines each node in the cluster to see if it has all the shards the meta store says it should have — the difference is that if any shards are missing, AE copies existing shards from another node that has the data. Any missing shards get copied automatically by the service. Starting with InfluxEnterprise 1.6, the AE service can be instructed to review the consistency of data contained within shards across the nodes. If any inconsistencies are found, AE can then repair those inconsistencies.
In our second example, the AE service would compare Nodes 1 and 2 against a digest built from the shards on the data nodes. It would then report that Node 2 was missing information, and then use that same digest to find out which information it was supposed to have. Then it will copy information from the good shard, Node 1, to fill it in on Node 2. Bam! Eventual consistency.
In more basic terms, the AE service now identifies missing or inconsistent shards and repairs them. This is self-healing at its best. Instead of worrying about the current state of our cluster, we can investigate what caused the failure (in this case, we might have been sleeping or eating waffles, although it's not always so straightforward).
There are some important things to know about AE. AE can only perform its heroism when there is at least one copy of the shard still available. In our example, we have an RF of 2, so we can rely on Node 1 for a healthy shard to copy. If Node 2 has a partial copy of that shard, those shards are compared and any missing data is then exchanged between the nodes to ensure that a consistent answer is returned. If a user chooses to have an RF of 1, they are choosing to save on storage, but missing out on high availability and subject to a more limited query volume. It also means that AE won't be able to make repairs because there's no source of truth left once the data is inconsistent. Another caveat is that AE will not compare or repair hot shards, meaning that the shard can't have active writes. Hot shards are more prone to change, and at any given moment, the arrival of new data affects AE's digest comparison. When a shard becomes cold or inactive, the data isn't changing, and the AE service can more accurately compare the digest.
Summary
Eventual consistency is a model that promises high availability, and if our data is available all of the time, it needs to be accurate all of the time. Like any good superhero duo, the HHQ and AE are better together, fighting crimes of data inconsistency in the background so that we can trust our data and get on with the things that matter to us (i.e., waffles).

Waffles are very important to me.
Published at DZone with permission of Katy Farmer, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments