Geospatial Data: Apache Spark vs. PostGIS
We take a look at how the big data tool Apache Spark stacks up against the geospatial tool PostGIS when it comes to handling big data sets.
Join the DZone community and get the full member experience.
Join For FreeIn my company, we've had a heated debate about geospatial data processing between old school conservative SQL fans and progressive big data and NoSQL fans.
Data Querying (MongoDB vs. PostGIS)
This section provides an overview of PostGIS and Mongodb, and their geospatial capabilities.
| Mongodb | Postgis | |
|---|---|---|
| Spark drivers | spark:mongo | spark:jdbc |
| Scalability |
|
|
| Response time |
|
|
| Geospatial index and Geoqueries |
|
|
Spark vs. PostGIS (Performance)
The purpose of this section is to compare the performance Spark and PostGIS with respect to different data analyses (max, avg, geospatial:within, etc.).
For PostGIS tests, the data is already preprocessed and indexed geospatially, while Spark will use directly raw data (parquet, csv, shape, etc.).
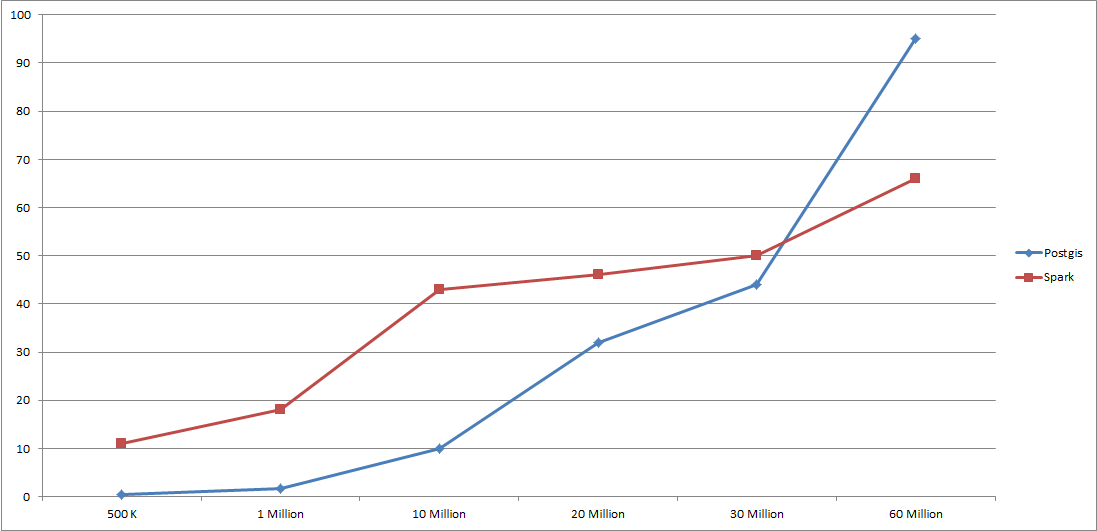
As the data size grows, Spark's response time remains stable while PostGIS's response time grows exponentially.
Max KPI:
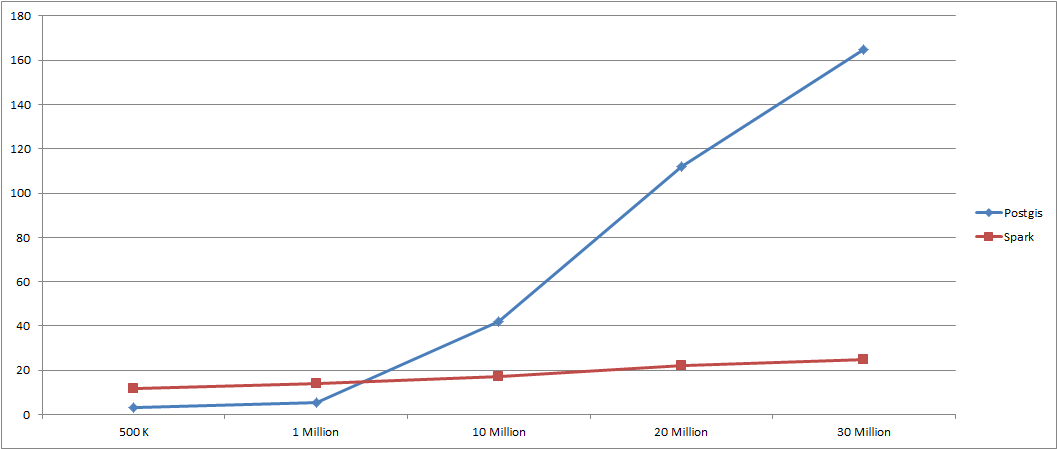
Mean KPI:
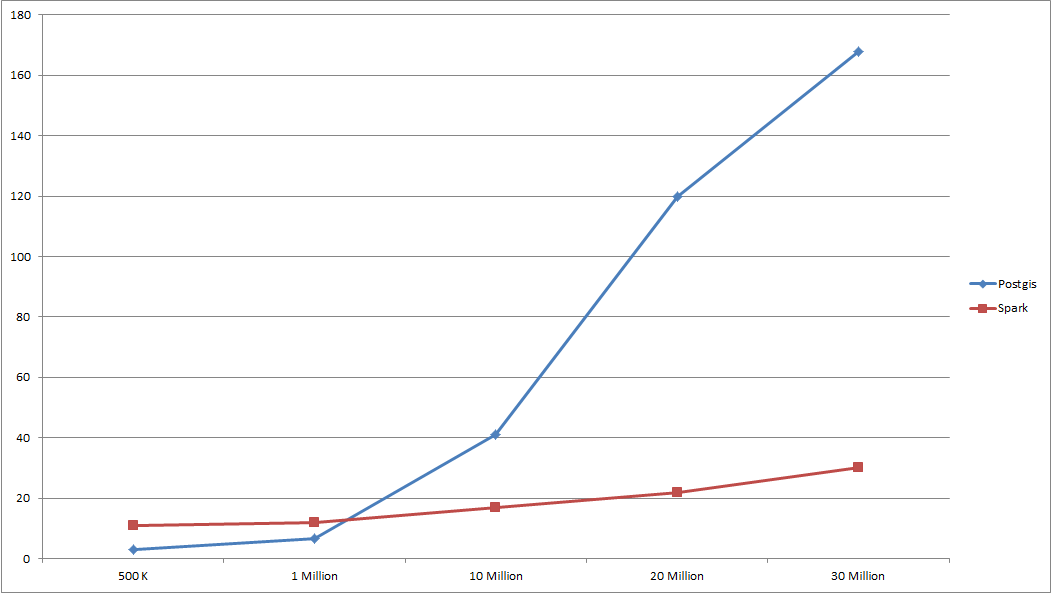
KPIs Within a Bounding Box:
Opinions expressed by DZone contributors are their own.
Comments