Build Pivot Tables in MySQL Using User Variables
Learn how to use MySQL user variables along with the CONCAT and GROUP_CONCAT functions to generate dynamic pivot tables from large data sets.
Join the DZone community and get the full member experience.
Join For Free
One of the most prominent tasks when dealing with databases is to properly filter and extract meaningful data from the underlying database. Due to that, there can be requirements to pivot the data from rows to columns leading to the creation of pivot tables to visualize data better.
Some databases like Microsoft SQL Server or Oracle come with inbuilt functionality to create a pivot table using the inbuilt pivot() function. However, this function is not available in some databases such as MySQL and MariaDB. In this post, we will discuss how to create pivot tables in MySQL without depending on any special functions.
Pivot Table Data
The best way to create a pivot table in MySQL is using a SELECT statement since it allows us to create the structure of a pivot table by mixing and matching the required data. The most important segment within a SELECT statement is the required fields that directly correspond to the pivot table structure.
In the following sections, let's see how to create a pivot table in MySQL using a SELECT statement. All the examples presented in this post are based on the Arctype SQL client in a Windows environment using MySQL database.
First, we need a data set to get started. We will be using the following data set in Arctype that contains historical monthly stock data of a set of organizations. You can download it here.

Using the above data set (pivot_stock_data table), we will create a pivot table to identify the changes in the stock prices on a monthly basis.
Using a CASE Statement to Create a Pivot Table
The simplest way to create a pivot table is using CASE statements within the SELECT statement to get the necessary columns and then group them by companies. Let's assume that we need the pivot table to display data from February 2013 to June 2013. We can achieve this by creating multiple CASE statements to get data for each required month.
SELECT
`name`,
MAX(
CASE
WHEN formatted_date = '2013-02' THEN delta_pct
ELSE NULL
END
) AS '2013-02',
MAX(
CASE
WHEN formatted_date = '2013-03' THEN delta_pct
ELSE NULL
END
) AS '2013-03',
MAX(
CASE
WHEN formatted_date = '2013-04' THEN delta_pct
ELSE NULL
END
) AS '2013-04',
MAX(
CASE
WHEN formatted_date = '2013-05' THEN delta_pct
ELSE NULL
END
) AS '2013-05',
MAX(
CASE
WHEN formatted_date = '2013-06' THEN delta_pct
ELSE NULL
END
) AS '2013-06'
FROM
pivot_stock_data
GROUP BY
`name`
ORDER BY
`name` ASC;In the above SQL statement, we have configured individual CASE statements to get the 'delta_pct' value for the corresponding month using the 'formatted_date' field. The MAX operator is used to obtain the maximum value for the given month. However, it can be any operator such as SUM, AVG, etc., depending on the requirement. Finally, we will group the result set by the 'name' column to obtain an aggregated result.

While this is a straightforward solution for a simple pivot table, it is not scalable for dealing with larger data sets. Moreover, creating individual CASE statements will be a tedious and time-consuming task, and any changes to the underlying data set will require manual modifications to the statement. However, we can create reusable SQL statements by creating CASE statements programmatically.
Using GROUP_CONCAT and SQL Variables to Create a Pivot Table
When it comes to creating CASE statements programmatically, we can use the GROUP_CONCACT function to retrieve a string of concatenated values from a group. Then we can store the result in a SQL user variable to be used when creating the pivot table.
Programmatically Creating the CASE Statement
In the below SQL statement, we are programmatically creating the CASE statement by creating a statement using CONTACT to fill the formatted_date field automatically. There, all the distinct results will again be concatenated using the GROUP CONCAT function and assigned to the '@sql' user variable.
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN formatted_date = '",
formatted_date,
"' THEN `delta_pct` ELSE NULL END) AS '",
formatted_date,
"'"
)
)
FROM
pivot_stock_data
);We need to configure the maximum length for the GROUP_CONCAT function before executing the above query. By default, it is limited to 1024 characters which will cause anything exceeding that limit to be truncated. We can mitigate this issue by setting a custom max length to the GROUP_CONTACT function before executing the query.
SET
SESSION group_concat_max_len = 100000;
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN formatted_date = '",
formatted_date,
"' THEN `delta_pct` ELSE NULL END) AS '",
formatted_date,
"'"
)
)
FROM
pivot_stock_data
);
SELECT
@sql;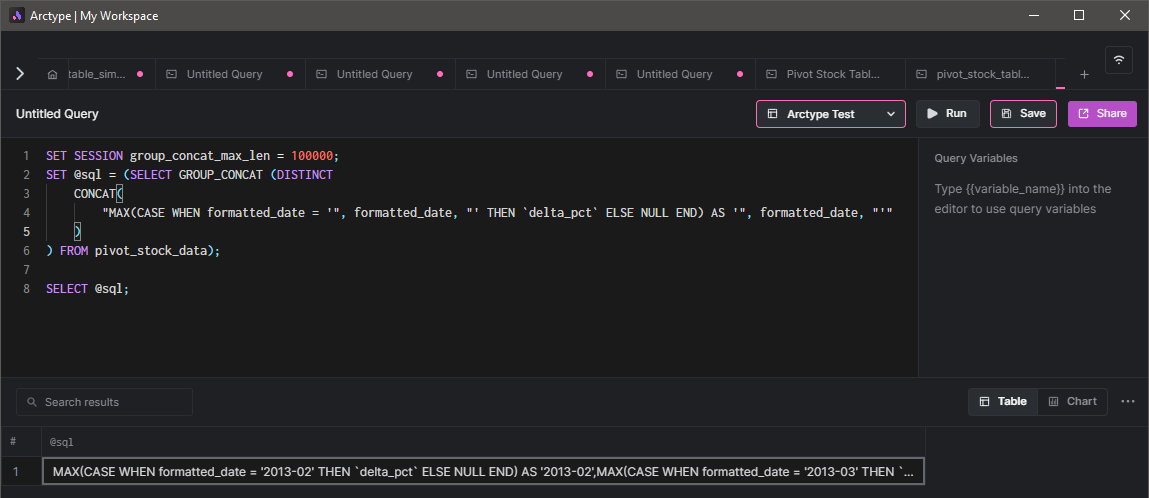
In the above code block, we have set the group_concat_max_len value to 100000 for the current session so that nothing will be truncated. Furthermore, we can obtain the output of the variable using a SELECT statement. We can verify whether the CASE statements have been successfully created by looking at the result string.

Creating the Complete SQL Statement
Now we have created the CASE statement, yet we need to add it to the SELECT query to execute successfully. For that, we will again use the CONCAT function to include the '@sql' variable in a select statement.
SET
@pivot_statement = CONCAT(
"SELECT name,",
@sql,
" FROM pivot_stock_data GROUP BY name ORDER BY name ASC"
);In the above statement, we assign the concatenated SELECT statement that includes the '@sql' variable to a new variable called '@pivot_statement.' We can verify the final statement using a SELECT statement as shown below.
SET
SESSION group_concat_max_len = 100000;
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN formatted_date = '",
formatted_date,
"' THEN `delta_pct` ELSE NULL END) AS '",
formatted_date,
"'"
)
)
FROM
pivot_stock_data
);
SET
@pivot_statement = CONCAT(
"SELECT name,",
@sql,
" FROM pivot_stock_data GROUP BY name ORDER BY name ASC"
);
SELECT
@pivot_statement;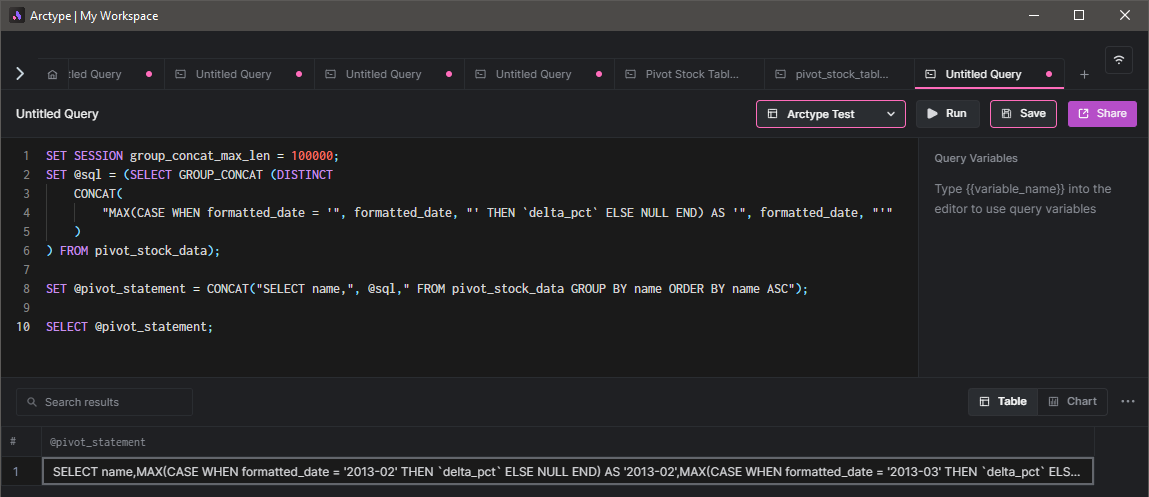
This will result in a complete SQL statement, as shown below.

Executing the SQL Statement
Now we have a complete SQL statement in the '@pivot_statement' variable, and we need to execute this statement to create the resulting pivot table. To create an executable SQL statement, we will be using the PREPARE function, which will prepare a SQL statement and assign it a name.
PREPARE complete_pivot_statment
FROM
@pivot_statement;We have assigned the complete_pivot_statment as the name of the prepared statement. Then we can execute this by referring to the assigned name using the EXECUTE function.
EXECUTE complete_pivot_statment;That's it, and now we have a reusable SQL statement to build pivot tables. The complete code block will be as follows;
-- Set GROUP_CONTACT Max Length
SET
SESSION group_concat_max_len = 100000;
-- Create GROUP_CONTACT Statement
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN formatted_date = '",
formatted_date,
"' THEN `delta_pct` ELSE NULL END) AS '",
formatted_date,
"'"
)
)
FROM
pivot_stock_data
);
-- Create the Complete SQL Statement
SET
@pivot_statement = CONCAT(
"SELECT name,",
@sql,
" FROM pivot_stock_data GROUP BY name ORDER BY name ASC"
);
-- Prepare and Execute
PREPARE complete_pivot_statment
FROM
@pivot_statement;
EXECUTE complete_pivot_statment;
Filtering Pivot Table Data
We can further filter the resulting data set by modifying the GROUP_CONCAT statement. The way you filter will depend on the data set, fields, and the data types of the targeted table. For example, we can add a WHERE statement to filter data within the year 2013 and retrieve data between '2013-01-01' to '2013-12-31'.
-- Set GROUP_CONTACT Max Length
SET
SESSION group_concat_max_len = 100000;
-- Create GROUP_CONTACT Statement
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN formatted_date = '",
formatted_date,
"' THEN `delta_pct` ELSE NULL END) AS '",
formatted_date,
"'"
)
)
FROM
pivot_stock_data
WHERE
yearmonth BETWEEN '2013-01-01 00:00:00' AND '2013-12-31 00:00:00'
);
-- Create the Complete SQL Statement
SET
@pivot_statement = CONCAT(
"SELECT name,",
@sql,
" FROM pivot_stock_data GROUP BY name ORDER BY name ASC"
);
-- Prepare and Execute
PREPARE complete_pivot_statment
FROM
@pivot_statement;
EXECUTE complete_pivot_statment;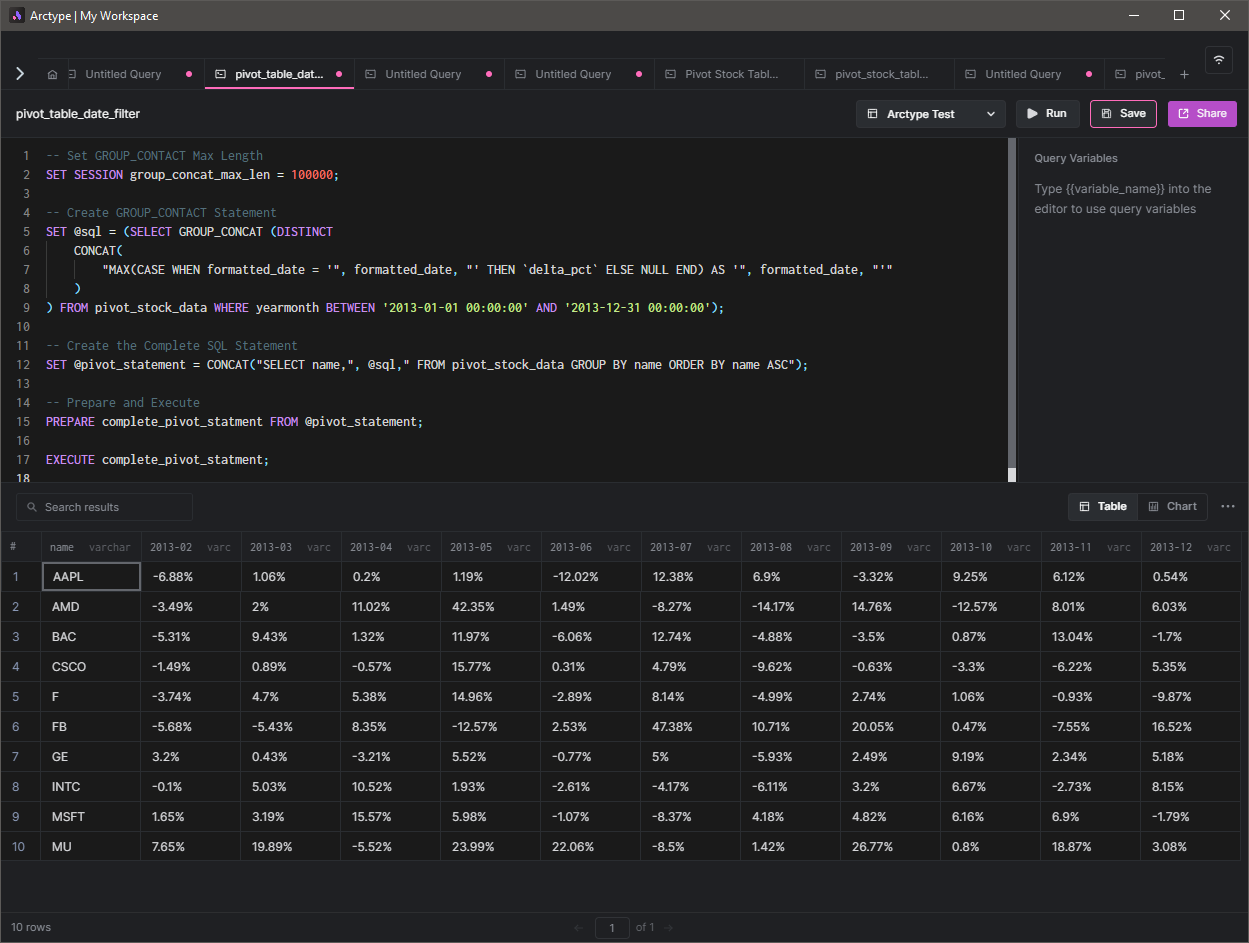
Let's look at another example. Assume that you want to change the way data is presented with the months as rows and stocks as the columns. Since it will change both the columns and rows, we need to change both the GROUP_CONCAT statement to include the stocks (name) and the CONTACT statement for the '@pivot_statement' variable to reflect the dates (formatted_date) as rows.
-- Set GROUP_CONTACT Max Length
SET
SESSION group_concat_max_len = 100000;
-- Create GROUP_CONTACT Statement
SET
@sql = (
SELECT
GROUP_CONCAT (
DISTINCT CONCAT(
"MAX(CASE WHEN name = '",
name,
"' THEN `delta_pct` ELSE NULL END) AS '",
name,
"'"
)
)
FROM
pivot_stock_data
);
-- Create the Complete SQL Statement
SET
@pivot_statement = CONCAT(
"SELECT formatted_date,",
@sql,
" FROM pivot_stock_data GROUP BY formatted_date ORDER BY formatted_date ASC"
);
-- Prepare and Execute
PREPARE complete_pivot_statment
FROM
@pivot_statement;
EXECUTE complete_pivot_statment;
Conclusion
In this article, we covered how to pivot data in MySQL using the GROUP_CONCAT function with user variables. We can follow this approach to build a custom SQL statement that will create a pivot table as the output. As with any SQL statement, the resulting pivot table depends on the underlying data set and the structure of the created statement. With careful consideration, we can create any kind of pivot table programmatically using the methods mentioned above.
Published at DZone with permission of Shanika WIckramasinghe. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments