Kafka Stream (KStream) vs Apache Flink
Join the DZone community and get the full member experience.
Join For FreeOverview
Two of the most popular and fast-growing frameworks for stream processing are Flink (since 2015) and Kafka’s Stream API (since 2016 in Kafka v0.10). Both are open-sourced from Apache and quickly replacing Spark Streaming — the traditional leader in this space.
In this article, I will share key differences between these two methods of stream processing with code examples. There are few articles on this topic that cover high-level differences, such as [1], [2], and [3] but not much information through code examples.
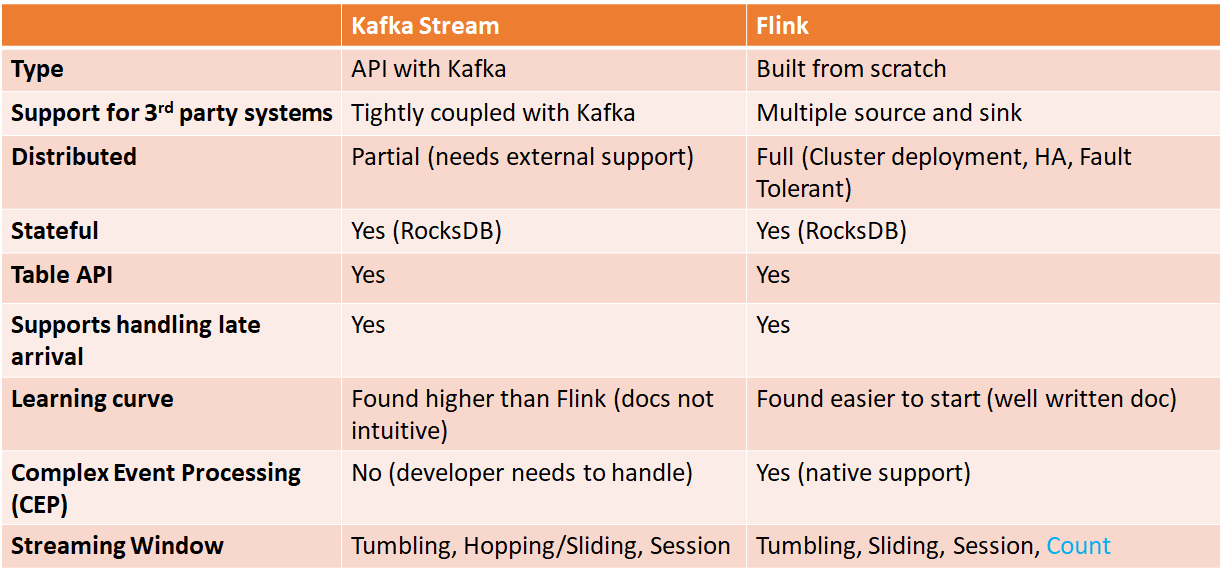
In this post, I will take a simple problem and try to provide code in both frameworks and compare them. Before we start with code, the following are my observations when I started learning KStream.
Example 1
The following are the steps in this example:
- Read stream of numbers from Kafka topic. These numbers are produced as string surrounded by "[" and "]". All records are produced with the same key.
- Define Tumbling Window of five seconds.
- Reduce (append the numbers as they arrive).
- Print to console.
Kafka Stream Code
xxxxxxxxxx
static String TOPIC_IN = "Topic-IN";
final StreamsBuilder builder = new StreamsBuilder();
builder
.stream(TOPIC_IN, Consumed.with(Serdes.String(), Serdes.String()))
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(5)))
.reduce((value1, value2) -> value1 + value2)
.toStream()
.print(Printed.toSysOut());
Topology topology = builder.build();
System.out.println(topology.describe());
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
Apache Flink Code
xxxxxxxxxx
static String TOPIC_IN = "Topic-IN";
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<KafkaRecord> kafkaConsumer = new FlinkKafkaConsumer<>(TOPIC_IN, new MySchema(), props);
kafkaConsumer.setStartFromLatest();
DataStream<KafkaRecord> stream = env.addSource(kafkaConsumer);
stream
.timeWindowAll(Time.seconds(5))
.reduce(new ReduceFunction<KafkaRecord>()
{
KafkaRecord result = new KafkaRecord();
public KafkaRecord reduce(KafkaRecord record1, KafkaRecord record2) throws Exception
{
result.key = record1.key;
result.value = record1.value + record2.value;
return result;
}
})
.print();
System.out.println( env.getExecutionPlan() );
env.execute();
Differences Observed After Running Both
- Can't use
window()withoutgroupByKey()in Kafka Stream; whereas Flink provides thetimeWindowAll()method to process all records in a stream without a key. - Kafka Stream by default reads a record and its key, but Flink needs a custom implementation of
KafkaDeserializationSchema<T>to read both key and value. If you are not interested in the key, then you can usenew SimpleStringSchema()as the second parameter to theFlinkKafkaConsumer<>constructor. The implementation ofMySchemais available on Github. - You can print the pipeline topology from both. This helps in optimizing your code. However, Flink provides, in addition to JSON dump, a web app to visually see the topology https://flink.apache.org/visualizer/.
- In Kafka Stream, I can print results to console only after calling
toStream()whereas Flink can directly print it. - Finally, Kafka Stream took 15+ seconds to print the results to console, while Flink is immediate. This looks a bit odd to me since it adds an extra delay for developers.
Example 2
The following are the steps in this example
- Read stream of numbers from Kafka topic. These numbers are produced as a string surrounded by "[" and "]". All records are produced with the same key.
- Define a Tumbling Window of five seconds.
- Define a grace period of 500ms to allow late arrivals.
- Reduce (append the numbers as they arrive).
- Send the result to another Kafka topic.
Kafka Stream Code
xxxxxxxxxx
static String TOPIC_IN = "Topic-IN";
static String TOPIC_OUT = "Topic-OUT";
final StreamsBuilder builder = new StreamsBuilder();
builder
.stream(TOPIC_IN, Consumed.with(Serdes.String(), Serdes.String()))
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(5))).grace(Duration.ofMillis(500)))
.reduce((value1, value2) -> value1 + value2)
.toStream()
.to(TOPIC_OUT);
Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
Flink Code
xxxxxxxxxx
static String TOPIC_IN = "Topic-IN";
static String TOPIC_OUT = "Topic-OUT";
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
FlinkKafkaConsumer<KafkaRecord> kafkaConsumer = new FlinkKafkaConsumer<>(TOPIC_IN, new MySchema(), props);
kafkaConsumer.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<KafkaRecord>()
{
public long extractAscendingTimestamp(KafkaRecord record)
{
return record.timestamp;
}
});
// define kafka producer using Flink API.
KafkaSerializationSchema<String> serializationSchema = (value, timestamp) -> new ProducerRecord<byte[], byte[]>(TOPIC_OUT, value.getBytes());
FlinkKafkaProducer<String> kafkaProducer =
new FlinkKafkaProducer<String>(TOPIC_OUT,
serializationSchema,
prodProps,
Semantic.EXACTLY_ONCE);
DataStream<KafkaRecord> stream = env.addSource(kafkaConsumer);
stream
.keyBy(record -> record.key)
.timeWindow(Time.seconds(5))
.allowedLateness(Time.milliseconds(500))
.reduce(new ReduceFunction<String>()
{
public String reduce(String value1, String value2) throws Exception
{
return value1+value2;
}
})
.addSink(kafkaProducer);
env.execute();
Differences Observed After Running Both
1. Due to native integration with Kafka, it was very easy to define this pipeline in KStream as opposed to Flink
2. In Flink, I had to define both Consumer and Producer, which adds extra code.
3. KStream automatically uses the timestamp present in the record (when they were inserted in Kafka) whereas Flink needs this information from the developer. I think Flink's Kafka connector can be improved in the future so that developers can write less code.
4. Handling late arrivals is easier in KStream as compared to Flink, but please note that Flink also provides a side-output stream for late arrival which is not available in Kafka stream.
5. Finally, after running both, I observed that Kafka Stream was taking some extra seconds to write to output topic, while Flink was pretty quick in sending data to output topic the moment results of a time window were computed.
Conclusion
- If your project is tightly coupled with Kafka for both source and sink, then KStream API is a better choice. However, you need to manage and operate the elasticity of KStream apps.
- Flink is a complete streaming computation system that supports HA, Fault-tolerance, self-monitoring, and a variety of deployment modes.
- Due to in-built support for multiple third-party sources and sink Flink is more useful for such projects. It can be easily customized to support custom data sources.
- Flink has a richer API when compared to Kafka Stream and supports batch processing, complex event processing (CEP), FlinkML, and Gelly (for graph processing).
Opinions expressed by DZone contributors are their own.
Comments