Keep Calm and JSON
Here’s a JSON representation of a customer data in JSON. Mind the gap and read on to find out more.
Join the DZone community and get the full member experience.
Join For Free
JSON (JavaScript Object Notation) is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for software to parse and generate. Here’s a JSON representation of a customer data in JSON. This has served well for interchange and integration.
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2542-5847-3949",
"expiry" : "2018-12"
}
],
"addressz":
{
"street" : "9462, Fillmore",
"city" : "San Francisco",
"state" : "California",
"zip" : 94401
}
}
So far, so good.
As long as JSON was used for data interchange between multiple layers of application, everything was good. The moment people started using JSON as the database storage format, all hell broke loose. When I first saw JSON as the data format in database, I was surprised databases would pay the cost of keeping both key names and values for every document and process them for every query. I've heard this question numerous times in my talks and articles.
Here are the common objections:
- JSON is text. It’s inefficient.
- JSON has no enforceable structure. Data quality is gone.
- Key-value pairs for every document (row)? You’re nuts.
Let's discuss these objections one by one.
1. JSON is TEXT. It’s Inefficient.
Online transactions provided by RDBMS was key to life as we know it even with the advent of Web 2.0, RDBMS was running the all the websites in the back. The cost of transaction had come down from $5 when mankind went to the moon down to $0.02 by the time Jim Gray took his last sailing trip. This is because of tremendous effort on RDBMS and hardware vendors to continuously improve to win TPC benchmark wars in the ‘90s. Oracle would publish on SUN hardware. Sybase would beat the numbers on HP. Informix would beat it on SGI. IBM would beat it on IBM. Then, Oracle will come back. Everyone would spend $25,000 to boast in a full page ad on WSJ — yes, people read newspapers on paper in the ‘90s.
For this effort, databases would optimize the physical design, access paths, I/O, data loading, transactions, et cetera. This drove many innovations in hardware such as, microprocessor instruction sets to SMP system design, InfiniBand. Databases squeezed every clock cycle, every IO, took every locking, logging advantage. Every bottleneck was attacked vigorously. Every hardware vendor tried to have the best TPC number.
RDBMS is efficient.
RDBMS is cost conscious — space, time, spacetime, everything.
Compared to RDBMS storage formats, JSON is inefficient.
- All the data is in character form of JSON requires conversion processing.
- Even numerical data is stored in text.
- Each value comes with its key name (key-value) in each document. More stored & processing.
- Allows complex structure to be represented resulting in a runtime overhead.
- Officially supports small set of data types. No decimal, no timestamp, etc.
Having JSON in a database means:
- Database engine has to understand each document’s schema and process them instead of handling regular tuples and attributes (rows & columns).
- The data types for each key-value in JSON has to be interpreted and processed
- JSON may be a skinnier version of XML, but it’s still fat.
With all these inefficiencies, why should any database use JSON as the data model? Or implement a JSON data type?
Yes. JSON was invented as data interchange format and now is the preferred format for public APIs, data integration scenarios. Most devices, most layers of software can consume and product data in the form of JSON. Storing and publishing data in JSON means, APIs and applications can interact with the database in the medium they’re familiar with, in addition to the advantages below. You’ve to think in term of n-tier application efficiency instead of comparing it to tuple insert and update. Most RDBMS have added JSON as a data type now. As the JSON usage grows, the storage and processing efficiency will increase.
2. JSON has no enforceable structure in the database. Data quality is gone.
Since the JSON databases do not enforce any structure. Application, intentionally or unintentionally, can insert data in any format as long as it’s a valid JSON.
JSON based databases prefer a “schema on read” model. This means, reader has responsibility to understand and interpret the schema of each document or result from the query. Query language like N1QL has many feature for introspection of the document itself.
Having said that, there are tools like Ottoman and Mongoose help you to validate a given JSON against a predefined structure.While this isn’t a fool proof method for data loading into JSON database, right controls in the application layer help you enforce consistency.
On the other hand, the flexible, nested structure of JSON helps you map object data into a single JSON document.
Using JSON also avoids the overhead of object-relational mapping. Applications model and modify objects. To store these in relational schema, you need to normalize the data into multiple relations and store them in discrete tables. When you need to reconstruct the object, you need to join data in these tables, and construct the object back. While object-relational mapping layers like Hibernate automate this process, you still pay in performance because you issue multiple queries for each step.
By representing the object in hierarchical nested structure of JSON, you avoid most of the overhead of object-relational mapping.

3. Key-value pairs for every document? You’re nuts!
The answer is, the bottleneck has moved. Bottleneck has moved from database core performance to database flexibility and change management for iterative application development.
In the ‘80s and ‘90s, as RDBMS was used for many more applications and use cases, it was important for RDBMS to keep up with the scale and all the hardware innovations. Higher clock speed, new instructions, more cores, larger memory, all were exploited. As business grew, demand for more automation, applications, processes increased. As the apps got more popular and valuable, businesses want to do more with this. Business applications went from back office automation to real business change drivers.
RDBMS is great at many things. But, not CHANGE themselves. Issues are both organizational and technical.
RDBMS use a “schema on write” approach. Schema is determined at CREATE TABLE time, checked for at every INSERT, UPDATE, MERGE. Changing the table structure typically involves multiple stakeholders, multiple applications, testing all the dependent modules.
Typical ALTER table to add columns, change data types requires exclusive lock on the table resulting in application and business scheduled downtime. If you need a column to store distinct types of data or structure, you’re out of luck. this trend, there have been attempts alleviate small subset of the issues by allowing users to add columns ONLINE.
All these takes time, slowing the pace of development and delivery. You can see further requirements of schema evolution on JSON hands it in this presentation [starting slide 17].
Using self-describing JSON model via {“key”:value} pairs to store the data makes each document self-describing. So, you can avoid enforcing the schema on write. When the documents is read by the query processing engine or the application, they’ll have to read and interpret the document. Applications typically version the documents so they know how what to expect as the schema of the document itself evolves. Query languages like N1QL, SQL++ have extended query languages to introspect and process flexible schema.
Summary
Here's the comparison of modeling data in relational model vs. JSON.
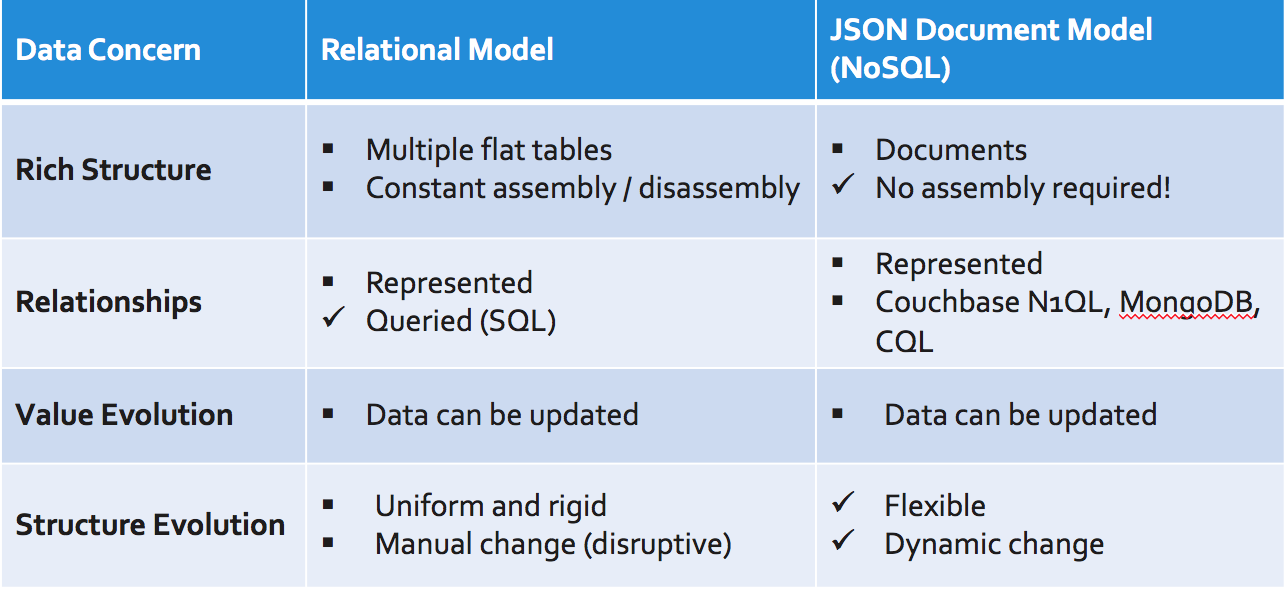
Yes. JSON is text, makes schema enforcement challenging and takes more space. But, you get easier application development, schema evolution, and object-relational mapping.
References
- Keep Calm and Query JSON: https://dzone.com/articles/keep-calm-and-query-json
Couchbase: http://www.couchbase.com
Couchbase Documentation: https://docs.couchbase.com/
Opinions expressed by DZone contributors are their own.
Comments