Lambda Architecture: How to Build a Big Data Pipeline, Part 1
We take a look at the basic steps needed to create a big data application for streaming and analyzing data from edge devices.
Join the DZone community and get the full member experience.
Join For FreeThe Internet of Things is the current hype, but what kinds of challenges do we face with the consumption of big amounts of data? With a large number of smart devices generating a huge amount of data, it would be ideal to have a big data system holding the history of that data. However, processing large data sets is too slow to maintain real-time updates of devices. The two requirements for real-time tracking and keeping results accurately up to date can be satisfied by building a lambda architecture.
"Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data."
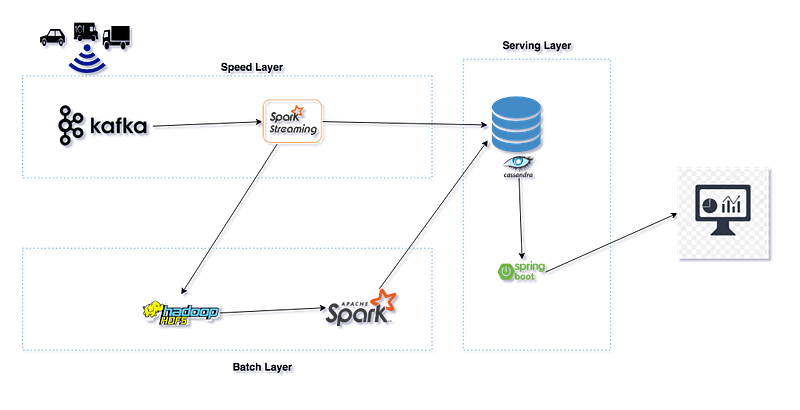
Bootstrapping a Lambda Project
The idea of this project is to provide you with a bootstrap for your next Lambda architecture. We are addressing some of the main challenges that everyone faces when starting with big data. This project will definitely help you get an understanding of the data processing world and save you a lot of time in setting up your initial Lambda architecture.
In this blog post, I will walk through some concepts and technologies that we have placed in our bootstrap Lambda project. I’m not planning on going too deep into the concepts and tools — we have a lot of posts about those out there — the intention here is to present an application example containing the patterns, tools, and technologies used to develop big data processing applications.
In this project, we’ll use a Lambda architecture to analyze and process IoT connected vehicle’s data and send the processed data to a real-time traffic monitoring dashboard.
Some patterns, tools, and technologies that you will see in this system:
Spark, Spark Streaming, Docker, Kafka, Web Sockets, Cassandra, Hadoop File System, Spring Boot, and Spring Data. Everything we talk about was developed using Java 8.
Infrastructure Management
In our project, all component parts are dynamically managed using Docker, which means you don’t need to worry about setting up your local environment — the only thing you need is to have Docker installed.
Having separate components, you will have to manage the infrastructure for each component. Infrastructure as Code (IaC) was born as a solution to this challenge. Everything that our application needs will be described in a file (Dockerfile). Along with the docker-compose file, we orchestrate a multi-container application and the entire service configuration will be versioned, making the process of building and deploying the whole project easier.
Distributed File System
A distributed file system is a client/server-based application that allows clients to access and process data stored on the server as if it were on their own computer. The Hadoop Distributed File System (HDFS) is the primary data storage system used by big data applications. Our project uses HDFS architecture as it provides a reliable way of managing pools of big data sets. Most importantly, with HDFS, we have one centralized location where any Spark worker can access the data.
Data Producing
In our project, we are simulating a system with the connected vehicle providing real-time information. Those connected vehicles generate a huge amount of data which are extremely random and time-sensitive. Obviously, there is no IoT device connected to our project, therefore we are producing fake random data and sending it to Kafka. See the producer subproject.
Stream Processing
Stream processing allows us to process data in real-time as it arrives and quickly detect conditions within a small time frame. From the point of view of performance, the latency of batch processing will be measured in minutes to hours, while the latency of stream processing will be in seconds or milliseconds. In our speed layer, we are processing the streaming data using Kafka with Spark streaming and the two main tasks are performed in this layer: first, the streamed data is appended into HDFS for later batch processing; second, an analysis is performed on the IoT connected vehicle’s data.
Batch Processing?
Batch processing is responsible for creating the batch view from the master data set stored in the Hadoop distributed file system (HDFS). It might take a large amount of time for that file to be processed, so, for this reason, we also have the real-time processing layer. We are processing the batch data using Spark and storing the pre-computed views into Cassandra.
Serving Layer
Once the computed view from batch and speed layers are stored in the Cassandra database, we have created a Spring Boot application which responds to ad-hoc queries by returning pre-computed views in a dashboard that is automatically updated using web socket to push the most updated report to the UI.
Summary
Our Lambda project receives real-time IoT Data Events coming from Connected Vehicles, then ingests that data to Spark through Kafka. Using the Spark Streaming API, we processed and analyzed IoT data events and transformed them into vehicle count for different types of vehicles on different routes, while the data is also simultaneously stored into HDFS for batch processing. We performed a series of stateless and stateful transformations using the Spark Streaming API on streams and persisted them to Cassandra database tables. In order to get accurate views, we also use batch processing to create a batch view in Cassandra. We developed responsive web traffic monitoring dashboard using Spring Boot, SockJs, and Bootstrap which merge two views from the Cassandra database before pushing to the UI using web socket.
Published at DZone with permission of Alexsandro Souza. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments