Lucene's near-real-time search is fast!
By
 ·
·
News
·
·
News
Join the DZone community and get the full member experience.
Join For FreeLucene's near-real-time (NRT) search feature, available since 2.9,
enables an application to make index changes visible to a new searcher
with fast turnaround time. In some cases, such as modern social/news
sites (e.g., LinkedIn, Twitter, Facebook, Stack Overflow, Hacker News, DZone, etc.), fast turnaround time is a hard requirement.
Fortunately, it's trivial to use. Just open your initial NRT reader, like this:
// w is your IndexWriter
IndexReader r = IndexReader.open(w, true);
(That's the 3.1+ API; prior to that use w.getReader() instead).
The returned reader behaves just like one opened with IndexReader.open: it exposes the point-in-time snapshot of the index as of when it was opened. Wrap it in an IndexSearcher and search away!
Once you've made changes to the index, call r.reopen() and you'll get another NRT reader; just be sure to close the old one.
What's special about the NRT reader is that it searches uncommitted changes from IndexWriter, enabling your application to decouple fast turnaround time from index durability on crash (i.e., how often commit is called), something not previously possible.
Under the hood, when an NRT reader is opened, Lucene flushes indexed documents as a new segment, applies any buffered deletions to in-memory bit-sets, and then opens a new reader showing the changes. The reopen time is in proportion to how many changes you made since last reopening that reader.
Lucene's approach is a nice compromise between immediate consistency, where changes are visible after each index change, and eventual consistency, where changes are visible "later" but you don't usually know exactly when.
With NRT, your application has controlled consistency: you decide exactly when changes must become visible.
Recently there have been some good improvements related to NRT:
How fast is NRT search?
I created a simple performance test to answer this. I first built a starting index by indexing all of Wikipedia's content (25 GB plain text), broken into 1 KB sized documents.
Using this index, the test then reindexes all the documents again, this time at a fixed rate of 1 MB/second plain text. This is a very fast rate compared to the typical NRT application; for example, it's almost twice as fast as Twitter's recent peak during this year's superbowl (4,064 tweets/second), assuming every tweet is 140 bytes, and assuming Twitter indexed all tweets on a single shard.
The test uses updateDocument, replacing documents by randomly selected ID, so that Lucene is forced to apply deletes across all segments. In addition, 8 search threads run a fixed TermQuery at the same time.
Finally, the NRT reader is reopened once per second.
I ran the test on modern hardware, a 24 core machine (dual x5680 Xeon CPUs) with an OCZ Vertex 3 240 GB SSD, using Oracle's 64 bit Java 1.6.0_21 and Linux Fedora 13. I gave Java a 2 GB max heap, and used MMapDirectory.
The test ran for 6 hours 25 minutes, since that's how long it takes to re-index all of Wikipedia at a limited rate of 1 MB/sec; here's the resulting QPS and NRT reopen delay (milliseconds) over that time:
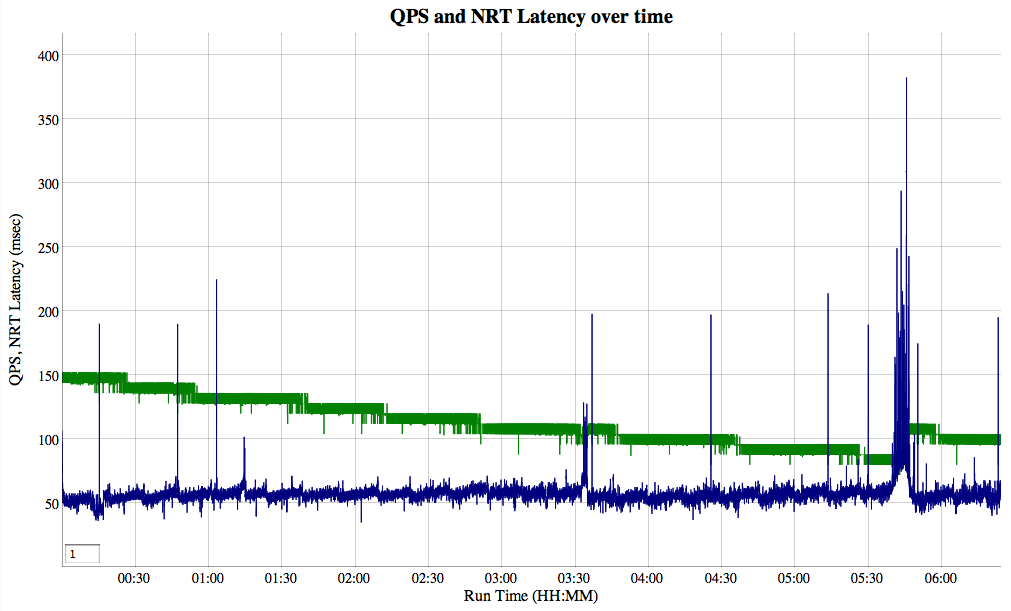
The search QPS is green and the time to reopen each reader (NRT reopen delay in milliseconds) is blue; the graph is an interactive Dygraph, so if you click through above, you can then zoom in to any interesting region by clicking and dragging. You can also apply smoothing by entering the size of the window into the text box in the bottom left part of the graph.
Search QPS dropped substantially with time. While annoying, this is expected, because of how deletions work in Lucene: documents are merely marked as deleted and thus are still visited but then filtered out, during searching. They are only truly deleted when the segments are merged. TermQuery is a worst-case query; harder queries, such as BooleanQuery, should see less slowdown from deleted, but not reclaimed, documents.
Since the starting index had no deletions, and then picked up deletions over time, the QPS dropped. It looks like TieredMergePolicy should perhaps be even more aggressive in targeting segments with deletions; however, finally around 5:40 a very large merge (reclaiming many deletions) was kicked off. Once it finished the QPS recovered somewhat.
Note that a real NRT application with deletions would see a more stable QPS since the index in "steady state" would always have some number of deletions in it; starting from a fresh index with no deletions is not typical.
Reopen delay during merging
The reopen delay is mostly around 55-60 milliseconds (mean is 57.0), which is very fast (i.e., only 5.7% "duty cycle" of the every 1.0 second reopen rate). There are random single spikes, which is caused by Java running a full GC cycle. However, large merges can slow down the reopen delay (once around 1:14, again at 3:34, and then the very large merge starting at 5:40). Many small merges (up to a few 100s of MB) were done but don't seem to impact reopen delay. Large merges have been a challenge in Lucene for some time, also causing trouble for ongoing searching.
I'm not yet sure why large merges so adversely impact reopen time; there are several possibilities. It could be simple IO contention: a merge keeps the IO system very busy reading and writing many bytes, thus interfering with any IO required during reopen. However, if that were the case, NRTCachingDirectory (used by the test) should have prevented it, but didn't. It's also possible that the OS is [poorly] choosing to evict important process pages, such as the terms index, in favor of IO caching, causing the term lookups required when applying deletes to hit page faults; however, this also shouldn't be happening in my test since I've set Linux's swappiness to 0.
Yet another possibility is Linux's write cache becomes temporarily too full, thus stalling all IO in the process until it clears; in this case perhaps tuning some of Linux's pdflush tunables could help, although I'd much rather find a Lucene-only solution so this problem can be fixed without users having to tweak such advanced OS tunables, even swappiness.
Fortunately, we have an active Google Summer of Code student, Varun Thacker, working on enabling Directory implementations to pass appropriate flags to the OS when opening files for merging (LUCENE-2793 and LUCENE-2795). From past testing I know that passing O_DIRECT can prevent merges from evicting hot pages, so it's possible this will fix our slow reopen time as well since it bypasses the write cache.
Finally, it's always possible other OSs do a better job managing the buffer cache, and wouldn't see such reopen delays during large merges.
This issue is still a mystery, as there are many possibilities, but we'll eventually get to the bottom of it. It could be we should simply add our own IO throttling, so we can control net MB/sec read and written by merging activity. This would make a nice addition to Lucene!
Except for the slowdown during merging, the performance of NRT is impressive. Most applications will have a required indexing rate far below 1 MB/sec per shard, and for most applications reopening once per second is fast enough.
While there are exciting ideas to bring true real-time search to Lucene, by directly searching IndexWriter's RAM buffer as Michael Busch has implemented at Twitter with some cool custom extensions to Lucene, I doubt even the most demanding social apps actually truly need better performance than we see today with NRT.
NIOFSDirectory vs MMapDirectory
Out of curiosity, I ran the exact same test as above, but this time with NIOFSDirectory instead of MMapDirectory:
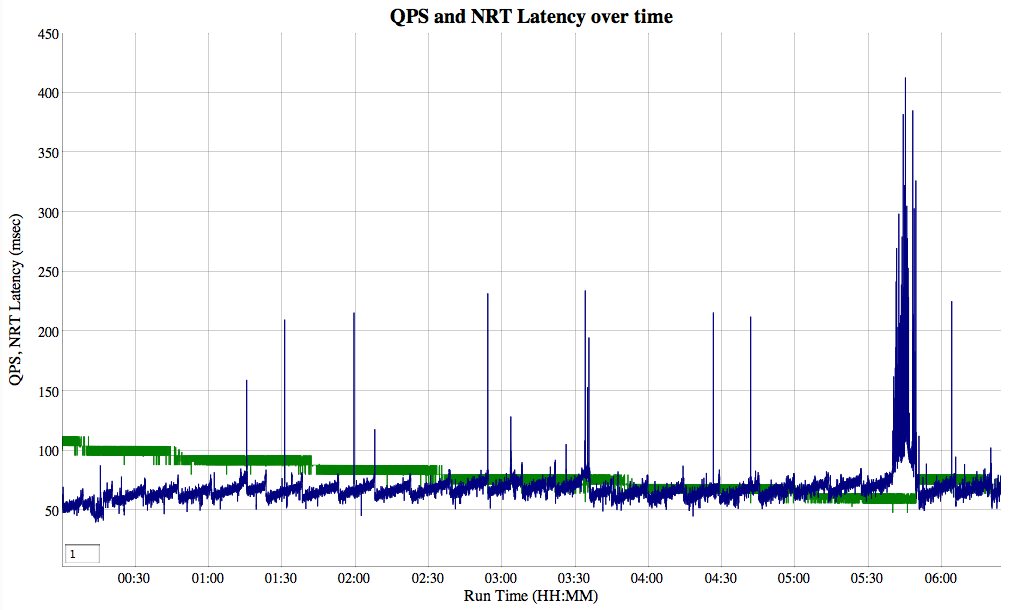
There are some interesting differences. The search QPS is substantially slower -- starting at 107 QPS vs 151, though part of this could easily be from getting different compilation out of hotspot. For some reason TermQuery, in particular, has high variance from one JVM instance to another.
The mean reopen time is slower: 67.7 milliseconds vs 57.0, and the reopen time seems more affected by the number of segments in the index (this is the saw-tooth pattern in the graph, matching when minor merges occur). The takeaway message seems clear: on Linux, use MMapDirectory not NIOFSDirectory!
Optimizing your NRT turnaround time
My test was just one datapoint, at a fixed fast reopen period (once per second) and at a high indexing rate (1 MB/sec plain text). You should test specifically for your use-case what reopen rate works best. Generally, the more frequently you reopen the faster the turnaround time will be, since fewer changes need to be applied; however, frequent reopening will reduce the maximum indexing rate.
Most apps have relatively low required indexing rates compared to what Lucene can handle and can thus pick a reopen rate to suit the application's turnaround time requirements.
There are also some simple steps you can take to reduce the turnaround time:
Happy near-real-time searching!
Fortunately, it's trivial to use. Just open your initial NRT reader, like this:
// w is your IndexWriter
IndexReader r = IndexReader.open(w, true);
(That's the 3.1+ API; prior to that use w.getReader() instead).
The returned reader behaves just like one opened with IndexReader.open: it exposes the point-in-time snapshot of the index as of when it was opened. Wrap it in an IndexSearcher and search away!
Once you've made changes to the index, call r.reopen() and you'll get another NRT reader; just be sure to close the old one.
What's special about the NRT reader is that it searches uncommitted changes from IndexWriter, enabling your application to decouple fast turnaround time from index durability on crash (i.e., how often commit is called), something not previously possible.
Under the hood, when an NRT reader is opened, Lucene flushes indexed documents as a new segment, applies any buffered deletions to in-memory bit-sets, and then opens a new reader showing the changes. The reopen time is in proportion to how many changes you made since last reopening that reader.
Lucene's approach is a nice compromise between immediate consistency, where changes are visible after each index change, and eventual consistency, where changes are visible "later" but you don't usually know exactly when.
With NRT, your application has controlled consistency: you decide exactly when changes must become visible.
Recently there have been some good improvements related to NRT:
- New default merge policy, TieredMergePolicy, which is able to select more efficient non-contiguous merges, and favors segments with more deletions.
- NRTCachingDirectory takes load off the IO system by caching small segments in RAM (LUCENE-3092).
-
When you open an NRT reader you can now optionally specify that
deletions do not need to be applied, making reopen faster for those
cases that can tolerate temporarily seeing deleted documents returned,
or have some other means of filtering them out (LUCENE-2900).
- Segments that are 100% deleted are now dropped instead of inefficiently merged (LUCENE-2010).
How fast is NRT search?
I created a simple performance test to answer this. I first built a starting index by indexing all of Wikipedia's content (25 GB plain text), broken into 1 KB sized documents.
Using this index, the test then reindexes all the documents again, this time at a fixed rate of 1 MB/second plain text. This is a very fast rate compared to the typical NRT application; for example, it's almost twice as fast as Twitter's recent peak during this year's superbowl (4,064 tweets/second), assuming every tweet is 140 bytes, and assuming Twitter indexed all tweets on a single shard.
The test uses updateDocument, replacing documents by randomly selected ID, so that Lucene is forced to apply deletes across all segments. In addition, 8 search threads run a fixed TermQuery at the same time.
Finally, the NRT reader is reopened once per second.
I ran the test on modern hardware, a 24 core machine (dual x5680 Xeon CPUs) with an OCZ Vertex 3 240 GB SSD, using Oracle's 64 bit Java 1.6.0_21 and Linux Fedora 13. I gave Java a 2 GB max heap, and used MMapDirectory.
The test ran for 6 hours 25 minutes, since that's how long it takes to re-index all of Wikipedia at a limited rate of 1 MB/sec; here's the resulting QPS and NRT reopen delay (milliseconds) over that time:
The search QPS is green and the time to reopen each reader (NRT reopen delay in milliseconds) is blue; the graph is an interactive Dygraph, so if you click through above, you can then zoom in to any interesting region by clicking and dragging. You can also apply smoothing by entering the size of the window into the text box in the bottom left part of the graph.
Search QPS dropped substantially with time. While annoying, this is expected, because of how deletions work in Lucene: documents are merely marked as deleted and thus are still visited but then filtered out, during searching. They are only truly deleted when the segments are merged. TermQuery is a worst-case query; harder queries, such as BooleanQuery, should see less slowdown from deleted, but not reclaimed, documents.
Since the starting index had no deletions, and then picked up deletions over time, the QPS dropped. It looks like TieredMergePolicy should perhaps be even more aggressive in targeting segments with deletions; however, finally around 5:40 a very large merge (reclaiming many deletions) was kicked off. Once it finished the QPS recovered somewhat.
Note that a real NRT application with deletions would see a more stable QPS since the index in "steady state" would always have some number of deletions in it; starting from a fresh index with no deletions is not typical.
Reopen delay during merging
The reopen delay is mostly around 55-60 milliseconds (mean is 57.0), which is very fast (i.e., only 5.7% "duty cycle" of the every 1.0 second reopen rate). There are random single spikes, which is caused by Java running a full GC cycle. However, large merges can slow down the reopen delay (once around 1:14, again at 3:34, and then the very large merge starting at 5:40). Many small merges (up to a few 100s of MB) were done but don't seem to impact reopen delay. Large merges have been a challenge in Lucene for some time, also causing trouble for ongoing searching.
I'm not yet sure why large merges so adversely impact reopen time; there are several possibilities. It could be simple IO contention: a merge keeps the IO system very busy reading and writing many bytes, thus interfering with any IO required during reopen. However, if that were the case, NRTCachingDirectory (used by the test) should have prevented it, but didn't. It's also possible that the OS is [poorly] choosing to evict important process pages, such as the terms index, in favor of IO caching, causing the term lookups required when applying deletes to hit page faults; however, this also shouldn't be happening in my test since I've set Linux's swappiness to 0.
Yet another possibility is Linux's write cache becomes temporarily too full, thus stalling all IO in the process until it clears; in this case perhaps tuning some of Linux's pdflush tunables could help, although I'd much rather find a Lucene-only solution so this problem can be fixed without users having to tweak such advanced OS tunables, even swappiness.
Fortunately, we have an active Google Summer of Code student, Varun Thacker, working on enabling Directory implementations to pass appropriate flags to the OS when opening files for merging (LUCENE-2793 and LUCENE-2795). From past testing I know that passing O_DIRECT can prevent merges from evicting hot pages, so it's possible this will fix our slow reopen time as well since it bypasses the write cache.
Finally, it's always possible other OSs do a better job managing the buffer cache, and wouldn't see such reopen delays during large merges.
This issue is still a mystery, as there are many possibilities, but we'll eventually get to the bottom of it. It could be we should simply add our own IO throttling, so we can control net MB/sec read and written by merging activity. This would make a nice addition to Lucene!
Except for the slowdown during merging, the performance of NRT is impressive. Most applications will have a required indexing rate far below 1 MB/sec per shard, and for most applications reopening once per second is fast enough.
While there are exciting ideas to bring true real-time search to Lucene, by directly searching IndexWriter's RAM buffer as Michael Busch has implemented at Twitter with some cool custom extensions to Lucene, I doubt even the most demanding social apps actually truly need better performance than we see today with NRT.
NIOFSDirectory vs MMapDirectory
Out of curiosity, I ran the exact same test as above, but this time with NIOFSDirectory instead of MMapDirectory:
There are some interesting differences. The search QPS is substantially slower -- starting at 107 QPS vs 151, though part of this could easily be from getting different compilation out of hotspot. For some reason TermQuery, in particular, has high variance from one JVM instance to another.
The mean reopen time is slower: 67.7 milliseconds vs 57.0, and the reopen time seems more affected by the number of segments in the index (this is the saw-tooth pattern in the graph, matching when minor merges occur). The takeaway message seems clear: on Linux, use MMapDirectory not NIOFSDirectory!
Optimizing your NRT turnaround time
My test was just one datapoint, at a fixed fast reopen period (once per second) and at a high indexing rate (1 MB/sec plain text). You should test specifically for your use-case what reopen rate works best. Generally, the more frequently you reopen the faster the turnaround time will be, since fewer changes need to be applied; however, frequent reopening will reduce the maximum indexing rate.
Most apps have relatively low required indexing rates compared to what Lucene can handle and can thus pick a reopen rate to suit the application's turnaround time requirements.
There are also some simple steps you can take to reduce the turnaround time:
- Store the index on a fast IO system, ideally a modern SSD.
- Install a merged segment warmer (see IndexWriter.setMergedSegmentWarmer). This warmer is invoked by IndexWriter to warm up a newly merged segment without blocking the reopen of a new NRT reader. If your application uses Lucene's FieldCache or has its own caches, this is important as otherwise that warming cost will be spent on the first query to hit the new reader.
-
Use only as many indexing threads as needed to achieve your required
indexing rate; often 1 thread suffices. The fewer threads used for
indexing, the faster the flushing, and the less merging (on trunk).
- If you are using Lucene's trunk, and your changes include deleting or updating prior documents, then use the Pulsing codec for your id field since this gives faster lookup performance which will make your reopen faster.
- Use the new NRTCachingDirectory, which buffers small segments in RAM to take load off the IO system (LUCENE-3092).
- Pass false for applyDeletes when opening an NRT reader, if your application can tolerate seeing deleted doccs from the returned reader.
- While it's not clear that thread priorities actually work correctly (see this Google Tech Talk), you should still set your thread priorities properly: the thread reopening your readers should be highest; next should be your indexing threads; and finally lowest should be all searching threads. If the machine becomes saturated, ideally only the search threads should take the hit.
Happy near-real-time searching!
Lucene
application
Merge (version control)
Testing
Database
Document
Queries per second
Published at DZone with permission of Michael Mccandless, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments