Making MongoDB Work Better for Analytics Using AWS Athena
Check out a tutorial that explains how to utilize a technique that will help your own analytics and querying needs.
Join the DZone community and get the full member experience.
Join For FreeAchieving low-latency read and write performance to rapidly query from MongoDB requires some foresight. At issue: row stores write quickly but are slow to read, while column stores can be read quickly but write slowly. But by using AWS Athena, it’s possible to load data from MongoDB into Parquet files and attain desirable querying speeds.
At Scale, we’ve been using this technique to perform fast ad-hoc queries of our high-volume analytics data, with MongoDB supported by WiredTiger as our primary data store. MongoDB provides a NoSQL document store, while WiredTiger stores documents such that the MongoDB instance is a row store. AWS Athena queries files on S3 using the Presto SQL query engine, which is capable of querying high-performance column stores like Parquet.
Want to utilize this technique for your own analytics or querying needs? Here’s how.
Row Stores and Column Stores
Let’s first look to find the sum of a single column over all the rows in a table – or, in other terms, the sum of a single field over all the documents in a collection. Using a row store with no index, finding that field for all documents requires loading the entire table from disk. This is slow and means loading columns that don’t even appear in the query.
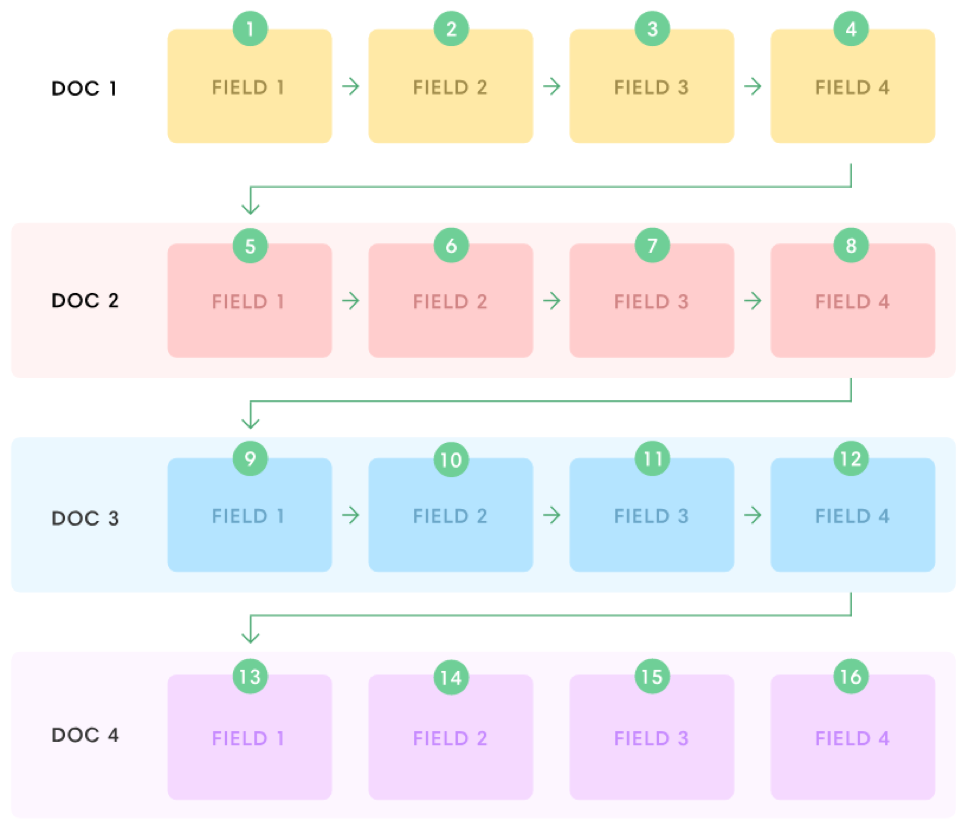
Using covering indices can help complete this query faster, but with each index comes increased disk usage and slower inserts. And with data exploration, foreseeing which indices you might need is a challenge.
A column store makes this query vastly more efficient, with data from the same column accessed altogether. Here, queries only need to retrieve the columns that are necessary, thus enabling high-performance ad-hoc queries — and done without using indices.
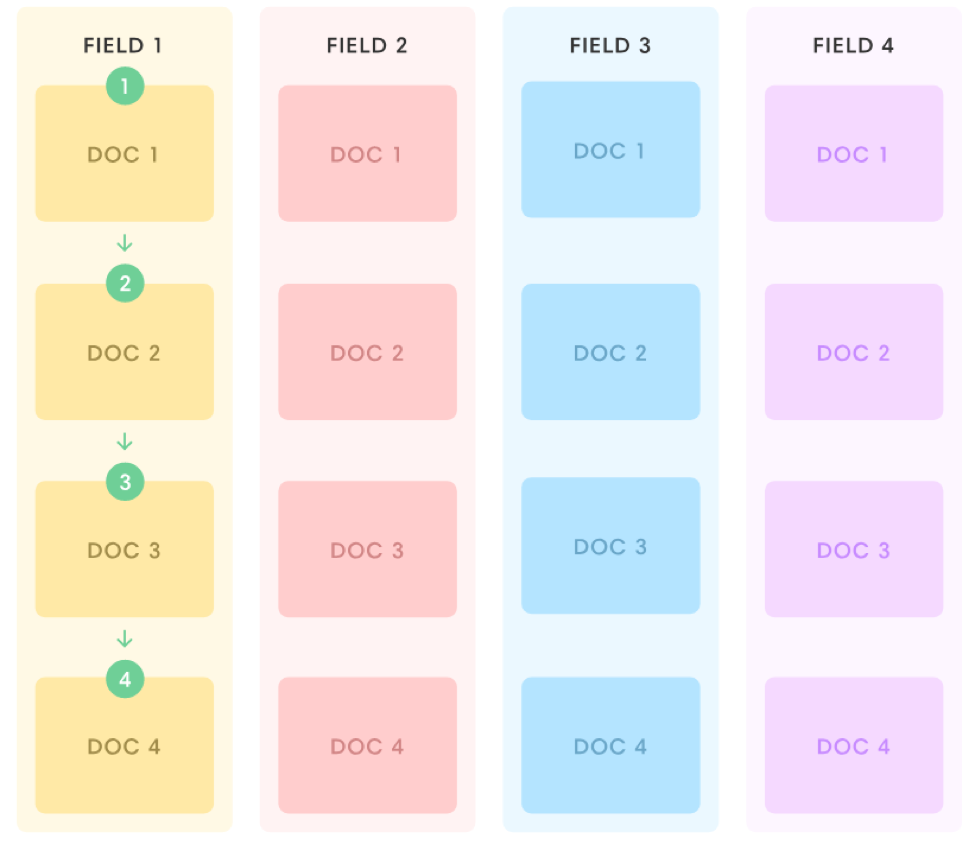
The trade-off is that column stores have a tougher time updating a single record, requiring all data to be moved in order to do so. Column stores also require a commitment to a previously-defined schema.
Balancing Read and Write Performance
Column-store write speed is a function of table size, as the entire table must be rewritten when updating a record. However, if we represent each row-store table as multiple column-store tables, we can then create a column store that reads slower but writes faster.
To do so, we map each MongoDB collection to multiple Parquet files and refresh every document in those files whenever a change occurs. “Files,” in this case, is used as a term of convenience: each Parquet “file” contains multiple row groups that are each column-major. We also purposefully use smaller file sizes that would result in optimized read speeds, because what we actually want here is to write more rapidly and curtail replication lag.
Cache Invalidation
To update the column store by reading the row store, it’s critical to determine which records are stale – and to replace them efficiently.
Recognizing stale records requires reading the identity of each document and its time of modification in the MongoDB oplog. This oplog is a data structure available on MongoDB replica sets that’s intended for internal use in replication from primary to secondary nodes within the cluster. It very handily keeps a history of all inserts, updates, and deletes to the database in chronological order.
Replacing these documents efficiently means making sure they’re stored in as few files as possible, which is accomplished by grouping records by their Mongo ObjectIDs. Young documents tend to be modified more often than older ones, a fact we — and you — will want to take advantage of. Here we maintain an index that records the ObjectID ranges of each file and start a new file whenever that the newest bucket has greater-than-N documents.

8 Important Details of Our Implementation
The workflow of our implementation can be visualized as:

Here are the eight most critical details to understand in your own implementation:
1) The scripts used to read MongoDB data and create Parquet files are written in Python, and write the Parquet files using the pyarrow library. A word of warning here: we initially used a filter-and-append strategy to update Parquet files more quickly than with a full overwrite. However, pyarrow (8.9.0) support for reading is less mature than for writing, resulting in occasional data loss. We now avoid reading from Parquet files.
2) Parquet files are made of row groups, each of which faces a size limit. To solve this, we batch documents by size:

3) With pymongo, you’ll want to defer parsing by using RawBSONDocument — especially if you have multiple processes writing different Parquet files, as this keeps parsing from occurring in the serial part of your program. Bson.BSON allows you to selectively parse sub-documents, as so:

4) To make writing a new Parquet file all-or-nothing, use atomicwrites:

5) Be sure to extract explicitly enumerated fields, and follow through by putting the entire JSON in its own column in order to query fields not in the schema.
6) Apache Drill offers a convenient method for reading Parquet files locally using SQL (simply untar and run drill-embedded to get started).
7) Updated Parquet files need to be copied to S3, (using sync and not cp). EC2 must be used to avoid expensive bandwidth costs due to the constant copying of files from the server to S3. AWS offers cost-free traffic between EC2 and S3 in the same region. Once a file is copied to S3, use AWS Glue to discover schema from the files. Do so only when the schema changes; calling Glue does incur costs.
8) All the information needed to update Parquet files is in the oplog. In our implementation, we run a MongoDB instance on the same machine, and use the applyOps command on oplog entries read from the main cluster to maintain a one-node slave. If using this technique, do be sure to keep an eye on the possibility of MongoDB developers removing the docs for applyOps.
By utilizing the techniques described here, in your own implementation, you can strike a healthy balance between read and write performance in your database and really leverage a best-of-both-worlds solution.
Chiao-Lun Chen is a Machine Learning Engineer at Scale, a company that accelerates the development of AI by democratizing access to intelligent data.
Opinions expressed by DZone contributors are their own.
Comments