Practical Transaction Handling in Microservice Architecture
The challenges that arise in implementing transaction handling in microservice architectures, and possible solutions for handling them.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
It’s challenging to handle the complexities that come with a distributed system when moving away from a monolith to microservice architecture (MSA). Transaction handling is at the front and center of this issue. A typical database transaction done in a web application using local transactions is now a complicated distributed transaction problem. In this article, we will discuss what causes this, the possible solutions, and the best practices in developing safe transactional software systems using MSA.
If you are already familiar with the related concepts behind database transactions and the intricacies of data consistency in a distributed system, you can skip to the section on "Data Modelling in Microservice Architecture" where we explore how to model data with a real-world use case.
Database Transactions: A Primer
In our good old monolith applications, we did database transactions to implement all-or-nothing data operations, while keeping data consistency. We mainly used ACID transactions, which is what you find in relational database systems. Here’s a quick refresher:
Atomicity: All operations are executed successfully or everything fails together.
Consistency: The data in the database is kept in a valid state, as stated by its rules, such as referential integrity.
Isolation: Separated transactions running concurrently cannot interfere with each other. It should be as the transaction is running in its own isolated environment where other transactions cannot see the changes happening in that duration.
Durability: After a transaction is committed, the changes are stored durably, e.g. persisted in a disk, so temporary crashes of the database server will not lose data.
We can imagine using ACID transactions as shown below, where we transfer some funds from one account to another.
BEGIN TRANSACTION
UPDATE ACCOUNT SET BALANCE=BALANCE-AMOUNT WHERE ID=1;
UPDATE ACCOUNT SET BALANCE=BALANCE+AMOUNT WHERE ID=2;
END TRANSACTION
Here, we wrap the individual debit and credit operations in an ACID transaction. This avoids inconsistencies such as money being lost from the system if the funds were taken out from one account but not put into the other account. This is a clear, straightforward solution, and we will keep writing code like this when required.
We are used to having the luxury of ACID transactions whenever we need. For most typical users where the processing requirements are kept in a single database server, this model is fine. But for people who need to scale their system with growing requirements for data access, storage capacity, and read/write scaling, this style of architecture quickly falls apart. For these users there are two ways to scale data stores:
Vertical scaling: More powerful hardware is put to a single server, such as increasing CPU and RAM or moving to a mainframe computer. This is generally more expensive and will hit a limit when the hardware can’t be upgraded anymore.
Horizontal scaling: More server nodes are added and everything is connected through the computer network. This is often the most practical thing to do.
In horizontal scaling, with a data store having multiple nodes in a cluster, things become a bit more complicated. A set of new challenges comes into play because data resides in physically separated servers. This is explained with the CAP theorem, which says that only two of the following properties can be achieved in a distributed data store.
Consistency: This relates to the data consistency between nodes. The data will have replicas to provide redundancy in the case of failures and to improve read performance. This means that when a data update is done in a single place, it should be simultaneously updated in all other replicas without any perceived delay for clients. This is more formally known as having linearizability. As you can see, this is not the same consistency concept in ACID.
Availability: The distributed data store is highly available so a loss of a server instance does not hinder the overall data store’s functionality and the users will still get non-error responses to their requests.
Partition tolerance: The data store can handle network partitions. A network partition is a loss of communication between certain nodes in the network. So some nodes may not be able to talk with other nodes in the data store cluster. This effectively partitions the data store nodes to multiple local networks, in the view of the nodes in the database cluster. An external client may still have access to all the nodes in the database cluster.
According to this, it’s impossible to have consistency, availability, and partition tolerance at the same time. We can understand this behavior intuitively if we think of the possible scenarios that can happen.
To maintain consistency when we write data, we need to simultaneously write to all the servers that act as replicas. However, if there are partitions in the network, we won’t be able to do this because we can only reach some servers at that time. In that case, if we want to tolerate these partitions while keeping the consistency, we can’t let users read this inconsistent data from the data store. That means we need to stop responding to user requests, making the data store no longer available (consistent and partition tolerant). Another scenario would be to let the data store still function, i.e. keep it available, which would make it not consistent anymore (available and partition-tolerant).
The final scenario is where the system doesn’t tolerate partitions allowing it to be both consistent and available. In this case, to have strong consistency (linearizability), we will still have to use a transaction protocol such as two-phase commit (2PC) to execute the data operations between replicated database server nodes. In 2PC, the participating databases’ operations are executed by a transaction coordinator in the following two phases:

Prepare: The participant is asked to check if its data operation can be performed and provide a promise to the transaction coordinator that later on if required, it can commit the operation or rollback. This is done for all the participants.
Commit: If all the participants said okay in the prepare phase, each participant is given a commit operation to commit the earlier mentioned operation. At this point, the participant cannot deny the operation, due to the promise given to the transaction coordinator earlier. If any of the participants earlier denied their local data operation due to any reason, the coordinate will send rollback commands to all the participants.
Other than the above database replication scenario for scalability, 2PC is also used when executing transactions between different types of systems such as database servers and message brokers. However, we generally avoid 2PC because of increased lock contention in distributed participants, which leads to poor performance, and hinders scalability.
Practically, computer networks are not reliable, and we should expect them to have network partitions at one time or another. So we generally see database systems that prioritize availability or consistency, i.e. AP or CP. Some systems allow the user to tune these parameters to either make it highly available or to select the consistency level. This is provided in database systems such as Amazon’s DynamoDB and Apache Cassandra. However, they are generally classified as AP systems since they don’t have strict CAP level consistency. Cassandra’s lightweight transaction support uses the Paxos consensus protocol to implement linearizable consistency, but this is rarely used since its mechanism entails very low performance, which is expected.
Effects on Data Consistency With Scalability
As we examined the tradeoffs in CAP theorem, if we value high-availability along with high performance and scalability, we have to make compromises in data consistency. This data consistency property in CAP affects the isolation property of ACID. If the data is not consistent between nodes in a distributed system, this means, there is a transaction isolation issue and we can see dirty data. So in this situation, we have to accept reality and find a way to live without ACID transactions and full CAP-consistency.
This transaction consistency model of embracing eventual consistency is also called BASE (Basically Available, Soft State, and Eventually Consistent), which promotes being available with eventual consistency. Soft state means that the data may change later due to the eventual consistency. Most NoSQL databases follow this approach, where they do not provide any ACID transaction functionality, but rather focus on scalability.
There are many use cases where eventual consistency is okay as strict data consistency is not required. For example, Domain Name System (DNS) is based on an eventual consistency model. Multiple intermediate caches contain the DNS entries. If someone updates a DNS entry, these are not immediately updated, but rather, the DNS queries are done after a cache timeout is done on the local entries. Since an update on DNS entry is not frequent, doing a new DNS query for every name resolve is just overkill and will be a major network performance bottleneck. So having an outdated entry in DNS for a user is tolerable. In the same way, there are many other real-world situations where we would do this. We will implement other workarounds to detect this type of outdated data or inconsistencies and take appropriate action at that point, rather than being pessimistic and making all the operations fully consistent and incurring a considerable performance hit.
In our distributed data store scenario, the level of consistency depends on the use case we are implementing. Let’s take a more detailed look at various consistency levels that are there, from the most to least strong consistency level.
Strict Serializability
In strict serializability, multiple object operations should happen atomically throughout all the replicas, while maintaining real-time ordering. Real-time ordering means it's the same order as operations were executed by clients in regard to a global clock that everyone is sharing. These grouped object operations represent individual transactions.
This is required to implement the isolation aspect of ACID transactions. Thus, if we require typical behavior we find in ACID transactions for the workload, strict serializability is required in our distributed data store.
Linearizability
In this consistency model, a single object’s operations throughout the replicas should be atomic. When a single client sees an operation done on an object in a replica, any other client connected to any other replica should also see the same operation. Also, the order in which the operations happen to the object should be the same as seen by all the clients and resemble the same real-time ordering.
When is this required? Let’s say we have three clients/processes. Process A writes an object value to the data store. Process B receives some external event that prompts it to read the aforementioned object value. After reading the value, it sends a message to Process C to also read in the object value and make a decision. The understanding of Process B is that the object value it reads will be at least the latest value that it has and not an older value. To make sure of this behavior, the distributed data store must provide linearizability consistency guarantees to make sure the updates done by Process A are immediately seen by all other replicas at the same time.
Even if we configure the Cassandra database to have strong consistency using an approach such as quorum-based read/writes, it wouldn’t provide linearizability guarantees, since the updates are not happening atomically in the replicas. To have linearizability, we have to use lightweight transactions support in Cassandra.
Sequential Consistency
In sequential consistency, a process doing operations on a data store will appear in the same order for other processes. Also, this ordering of all operations will be consistent with the relative order of each process’s operations. Basically, it preserves the process level ordering in the overall order of operations.
Causal Consistency
In causal consistency, any potential causally-related operations should be visible in the same order for all processes. Simply put, if you do an operation based on an earlier observed separate operation, the order of these operations must be the same for other processes as well.
To satisfy causal consistency, the following behaviors should be supported:
Read Your Writes: A process should be able to immediately read in the changes it did with earlier write operations.
Monotonic Reads: A process doing a read operation on an object should always see the same or a more recent value. Basically, the read operation cannot go back and see an older value.
Monotonic Writes: A process doing write operations should make sure that other processes should see these write operations in their relative order.
Writes Follow Reads: A process writes a new value v2 to an object by reading in an earlier value v1 based on an earlier write operation. In this case, everyone should always see the object's values v1 before v2.
This is an especially useful consistency model with many practical real-life applications. For example, let’s take a social media website backed by a distributed data store. We have concurrent users interacting with the website whether it be updating their profile statuses or commenting on someone’s profile status. The user Anne, who just had a small accident, puts the status “Had a small accident, waiting for the X-ray results!”. Just after she put this status, she gets her results and there’s no fracture. So she updates her status to “Good news: no fracture!”. Bob sees this last message from Anne and replies to her status saying “Glad to hear! :)”.
In the scenario above, if our data store provides at least causal consistency, all other users will see messages from Anne and Bob in the correct order. But if the data store does not provide causal consistency, there is a chance that other users will see Anne's first message then Bob’s message without seeing Anne’s second update. That situation becomes a bit strange as it looks like Bob expressed his happiness for Anne’s misfortune, which wasn’t the case. So we need causal consistency in a situation like this.
So provided that we have a causal consistent data store, in the same situation, let’s say Tom updates his status to say “I just got my first car!” just before Anne puts her first update. Some users of the website see his status after Anne’s first message. This situation is fine since it doesn’t matter if Tom's update happened before or after Anne’s update in real-life. There is no connection between them, i.e. Tom’s actions weren’t caused by Anne’s actions. Other operations that don't have a causal relationship operate in an eventually consistent manner.
A distributed data store that specifically supports causal consistency is MongoDB. It has implemented this based on the Lamport logical clock.
Eventual Consistency
In plain eventual consistency, if there aren’t any more writes to a data store, all the replicas in the data store converge and eventually agree on a final value. It won’t provide any other guarantees, such as causal consistency before it stabilizes on the final value.
Practically, this consistency model is fine for use cases where they are only concurrent value updates and there are no connections between the values when they are updated; users don’t care about the intermediate values, just the final stable value it ends up with. For example, let’s take a website that posts the current temperature for each city. These values change from time to time. At some point, some users may see the latest temperature value, while others have still not been updated. However eventually, the data update will be caught up with all the users of the website. So this possible propagation delay of a distributed database that stores these values is not a big issue as long as in the end, all users will eventually see the same temperature values.
For more in-depth information on transaction consistency models, please check the resources section at the end of the article.
We now have a general understanding of aspects related to transaction processing and consistency models. This knowledge is useful when you are working in any distributed processing environment, such as MSA. The same concepts we talked about will apply there as well. Now let’s look at how to model data in MSA.
Data Modelling in Microservice Architecture
A fundamental requirement of a microservice is to be highly cohesive and loosely coupled. This is required naturally as the organization structure of a development team will also be built around this concept. There will be separate teams responsible for microservices, and they require the flexibility and freedom to be independent of others. This means they avoid any unwanted synchronization with other teams on the design and the internal details of implementations.
With these requirements, microservices should strictly not share databases. If each microservice can’t have its own database, then it’s a good indicator that those microservices need to be merged.
The following shows a possible microservices design of an e-commerce backend.
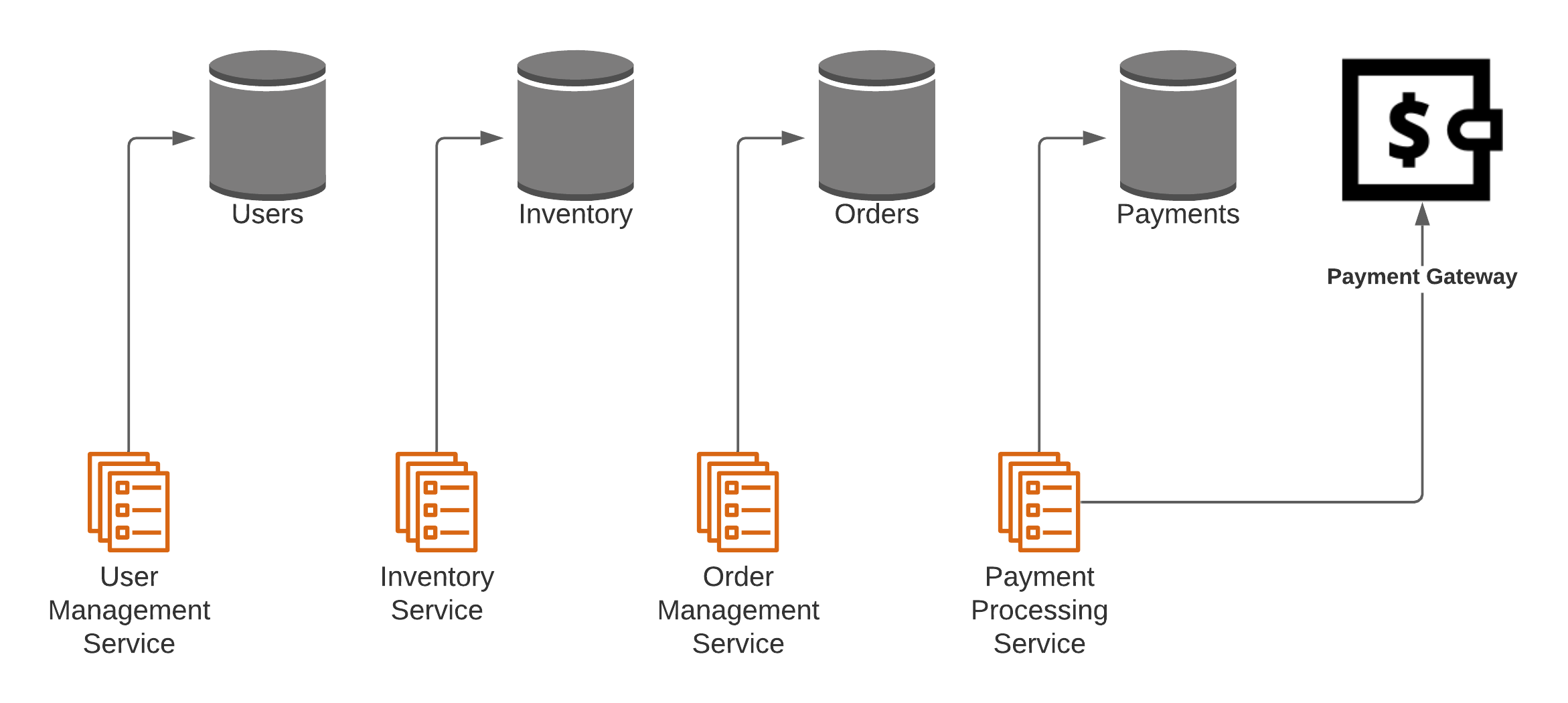
Here, we manage each aspect of the system with its own microservice. This looks good until we come to handling transactions. A typical operation would include creating a user order with a set of products. These products’ availability is checked using the inventory service, and after the order is finalized, the inventory is updated to decrement the available stock of those products. In a typical monolithic application, you can perform the following operations in a single ACID transaction.
xxxxxxxxxx
BEGIN TRANSACTION
CHECK INVENTORY OF PRODUCT 1 FOR 5 ITEMS
CHECK INVENTORY OF PRODUCT 2 FOR 10 ITEMS
CREATE ORDER
ADD 5 ITEMS OF PRODUCT 1 TO ORDER
ADD 10 ITEMS OF PRODUCT 2 TO ORDER
DECREMENT INVENTORY OF PRODUCT 1 BY 5 ITEMS
DECREMENT INVENTORY OF PRODUCT 2 BY 10 ITEMS
INSERT PAYMENT
END TRANSACTION
In this approach, we are confident that the data store ends up in a consistent state after the data operations. Now, how do we model the above operations using our microservices? One possible solution that may come to mind is the approach below.

Here, a coordinator service “Admin” creates a service orchestration by calling each service’s operation. This would work if all the operations execute without any issue. But there is a definite chance that some step in the flow can fail, such as if an application error occurs when a user doesn’t have enough credit or network communication fails. For example, if the flow fails due to the user management service being unavailable for the payment processing service, step 4 will fail. But at this point, we have already created an order and updated the inventory as well. So now we have an inconsistent state in our system, where our inventory is reporting lower numbers of goods without anyone buying them! The clear issue here is that we were not doing these operations in a single transaction where if one step fails, all the operations would be rolled back, leaving us with a consistent system.
What are the possible solutions to our problem? The simplest solution would be to go back to a monolithic solution by putting all these operations together to a single service and a single database and doing all the operations in a local transaction. But in this situation, let’s assume that we have made the decision that the large monolithic application does not scale, and we do have to break it up into individual microservices. In that case, for our transaction problem, we are left with a 2PC based solution. We can use a solution such as WS-TX or Ballerina’s distributed transaction functionality to execute a 2PC based global transaction between network services. Similar approaches to these are the only option if you need to have ACID guarantees in your transaction. However, this should be used with caution, since the typical 2PC drawbacks such as increased locking times in backend databases are still there. This nature only increases in a microservices environment due to extra network communication hops.
However, most real-life workflows don’t need ACID guarantees because incorrect actions can be reversed using the opposite of the action. So in our order processing workflow, if something goes wrong, we can execute compensation operations for the operations that were already done and rollback the full transaction. These actions will be things like crediting a payment back to the user’s credit card, updating the product inventory by adding back the count of the products in the order, and updating the order record as canceled.
Our e-commerce backend scenario actually cannot be modeled solely as a single database transaction because the action of processing payments is done using an external payment gateway, which cannot be part of a local or a global (2PC) database transaction. However, there is an exception to this situation in the case of a 2PC based global transaction. In the 2PC scenario, the very last participant of the global transaction does not have to implement both prepare and commit phases, but rather a single prepare operation is enough to execute its operation. This is called the last resource commit optimization. Again, this is only possible with this specific scenario, where this type of participant in any other place in the workflow will not make it possible to have a global transaction.
So now, we have decided that we don’t need the strict consistency of data that we get with 2PC, and we are fine with correcting any issues later. Let’s see a possible execution of this workflow.

Here, the workflow fails at step 4. From there onwards, the admin service should execute a set of compensation operations in reverse order of the earlier called services. But there’s a potential problem here. What if the admin service encounters an error such as a temporary network issue while reverting operations? We again have a data inconsistency issue where the total rollback is not done, and we have no way of knowing the last operations we did and how to fix it later.
One way of handling this issue would be to keep a log of operations done by the admin service. This could be similar to the following:
- TX1: CHECK INVENTORY
- TX1: CREATE ORDER
- TX1: UPDATE INVENTORY
- TX1: PROCESS PAYMENT - FAILED
- TX1: MARK ORDER AS CANCELLED
- TX1: UPDATE INVENTORY - INCREMENT STOCK COUNTS
So the admin service can track the operations that have already been executed, and what hasn’t. But again, we have to be thoughtful of possible edge cases that can happen even when processing an event log like this. The admin service and its log is separate from the other remote service operations, thus those interactions themselves do not work transactionally. There are changes like the following:
- Admin service executes inventory service to revert inventory counts (by incrementing)
- Admin service updates its log with “TX1: UPDATE INVENTORY - INCREMENT STOCK COUNTS”
What if the first operation above executes, then the service crashes before the second operation? When the admin service continues its operations again, it will think that it didn’t do the inventory revert operation and will execute the first operation again. This will leave the inventory data with invalid values because it has done stock number increments twice, which isn’t good! This is a situation of having at-least-once delivery as we would often see in a distributed system. A common approach to handle this would be to model our operations to be idempotent. That is, even if the same operation is done multiple times, it will not cause any harm, and the target system’s state would be the same.
But our inventory rollback operation is not idempotent because, it’s not setting a specific value, but rather it’s incrementing an already existing value in the target system. So you cannot duplicate these operations. We can make it an idempotent operation by directly setting the inventory stock count that was there before we made our order. But then again, due to the way our transaction is modeled in the microservice architecture, it does not provide any type of isolation properties as you would find in ACID transactions, i.e. strict serialization consistency level. That is, when our transaction is executed, another user may also be creating another order which involves the same products, which will modify the same inventory records. Due to this, these two transactions’ actions may overlap and lead to inconsistent scenarios.
So actually, not only in the scenario of a transaction rollbacking, even in two concurrent successful transactions, due to the lack of isolation, an idempotent operation can have the effect of data losing update. Let’s check the timeline below of two transaction operations.

Here we have two transactions TX1 and TX2. They are both making orders for product “P1”, which has a starting inventory of 100. TX1 is going to create an order with 10 items, and then TX2 is going to create an order with 20 items. As we can see from the sequence diagram above, checking the inventory and updating the inventory is not happening atomically in the two transactions, but rather, they get interleaved, and final TX2’s inventory update overshadows the inventory update of TX1. So the final P1’s product count is 80 whereas it should have been 70 due to 30 products being bought by two transactions. So now the inventory database data is incorrectly signaling the actual available inventory.
So we have got a race condition due to two concurrent processes not being properly isolated. The approach to fix this situation is by making the inventory update operation a value decrement operation, i.e. decrementInventoryStockCount(product, offset), relative to the existing value in the database. So this operation can be made an atomic operation in the target service using a single SQL operation, or a single local transaction being executed.
So with this update, the interaction above can be re-written in the following manner.

As we can see now, with the new operations to decrement the counts in the inventory, our final counts are going to be consistent and correct.
Note: We would still have a different error situation, where after checking the initial inventory counts, at the time of the checkout, the product inventory may be empty where other transactions have already brought full the stock. This simply would be handled as a business process error where we can rollback the operations, and the data will still be consistent.
Sometimes it’s not feasible to make data operations idempotent due to transaction isolation issues we get in a microservices communication. This means we can’t blindly retry operations in a transaction if we are not sure whether an operation was executed in a remote microservice. This can be solved by having a unique identifier such as a transaction ID for the operation of the microservice call, so the target microservice will create a history of transactions executed against it. In this manner, for each microservice operation call, it can do a local transaction to check the history and see if this transaction has already been executed. If not, it will execute the database operation, and still in the local transaction, update the transaction history table as well. The code below shows a possible implementation for the decrementInventoryStockCount operation in the inventory service using the above strategy.
xxxxxxxxxx
function decrementInventoryStockCount(txid, pid, offset) {
transaction {
tx_executed = check transaction table record where id=txid
if not tx_executed {
prod_count = select count from inventory where product=pid
prod_count += offset
set count=prod_count in inventory where product=pid
insert to transaction table with id=txid
}
}
}
Microservices and Messaging
So now, we have figured out a consistent way to execute our transactions throughout a set of microservices, with eventual all-or-nothing guarantees. In this flow, we still have to maintain our event log and update it in reliable persistent storage. If the coordination service that runs the orchestration goes down, another entity would have to trigger it again to check the event log and do any recovery actions. It would be good if we already have some middleware that could be used to provide reliable communication between services to help with this task.
This is where an event-driven architecture (EDA) is useful. This can be created using a message broker for communication between microservices. Using this pattern, we can make sure if we emit a message successfully to a message broker that is meant to target some service, it will at some point be successfully sent to the intended recipient. This guarantee makes our other processes much easier to model. Also, the message broker’s asynchronous communication model, where it allows simultaneous reading and writing, provides much better performance due to lower overheads and wait times for roundtrip calls. Error handling is also simpler because even if the target service is down, the message broker will hold the messages and deliver them when the target endpoint is available. Additionally, it can do other operations such as failure retries and load balancing requests with multiple service instances. This pattern also encourages loose coupling between services. The communication happens via queue/topics, and producers and consumers do not need to know about each other explicitly. The Saga pattern follows these general guidelines when implementing transactions in microservices, based on compensation operations.
There are two coordination strategies for implementing this pattern: choreography and orchestration.
Choreography
In this approach, the services themselves are aware of the flow of the operations. After an initial message is sent to a service operation, it generates the next message to be sent to the following service operation. The service needs to have explicit knowledge of the flow of the transaction leading to more coupling between services. The diagram below shows the typical interactions between the services and queues when implementing a transactional workflow as a choreography.

Here, we can see that the flow starts from the client that sends the initial message to the first service through its input message queue. In its business logic, it can carry out its data-related operations in a local transaction defined within the service. After the operations are done, the overall workflow adds a message to the request queue of the next service in the choreography. In this manner, the overall transaction context will be propagated through these messages to each of the services until completion.
In the case of failure in a service in the workflow, we need to rollback the overall transaction. For this, starting from the service which incurred the failure, it will clean up its resources, and send a message through a compensation queue to the service that was executed right before. This moves the execution of the previous step, does any compensation actions to rollback the changes done by its local transaction, and repeats the operation of contacting its previous service for compensation operations. In this, the error handling chain will reach the first service that will then ultimately send a message to the response queue. This is connected to the client to notify that an error has occurred and the total transaction has been rolled back successfully using compensation actions.
As seen in the synchronous service invocation approach, when executing the local transactions in their respective services, we should maintain a transaction history table to ensure we don’t repeat the local operations in case the service receives duplicate messages. Also, in order to not lose the continuity of the workflow, a service should acknowledge the message from its request queue only after the database transaction is done and the next message is added to the request queue of the following service. This flow makes sure we don’t lose any messages and the overall transaction will finish executing either by succeeding or rolling back all the operations.
Orchestration
In this coordination approach, we have a dedicated coordinator service that calls other services in succession. The communication between the coordinator services and other services will be done via request and response queues. This pattern is similar to the “Admin” service in our e-commerce scenario. The only change is to use messaging for communication.
The asynchronous communication between the coordinator service and the other services allows it to model the transactional process as a state machine, wherein each of the steps completed with the services can update the state machine. The state machine should be persisted in a database to recover from any failures of the coordination service. The diagram below shows how the orchestration coordination approach is designed using a message-driven strategy.

Compared to choreography, orchestration has lesser coupling between the services. This is because the workflow is driven by the coordination service, and the full state at a given moment is retained in that service itself. But still, the services here are not totally independent since their requests and responses are bound to specific queues, where a fixed producer and a fixed consumer are using those queues. So it’s now harder to use these services as generic services.
Choreography based coordination probably is feasible when we have a fewer number of operations. For complicated operations, the orchestration based approach will have more flexibility when modeling the operations.
When implementing this strategy, it is important to abstract out the finer details of communication, state machine’s persistence, and so on in a developer framework. Or else, a developer will end up writing more code for implementing the transaction handling rather than the core business logic. Also, it would be much more error-prone if a typical developer always implemented this pattern from scratch.
Selecting a Transaction Model for Microservices
In any technology we use when implementing transactions, we need to be explicit on the data consistency guarantees that each approach will give. Then we have to cross-check with our business needs to see what is most suitable for us. The following can be used as a general guideline.
2PC: In the case where the microservices are created using different programming languages/frameworks/databases, and probably development teams from different companies, it is not possible to combine all operations to a single service. Also, it would require strict data consistency, where any data isolation issues, such as dirty reads cannot be tolerated in relation to the business needs.
Compensation-based transactions: This is using a transaction coordination mechanism to track the individual steps in a transaction, and in the case of a failure, to execute compensation operations to roll back the actions. This should generally involve the usage of idempotent data operations or commutative updates in order to handle message duplicate scenarios. Your business requirements should be able to handle eventual consistency behavior such as dirty reads.
Consolidating services: Use this in case 2PC is not tolerated due to performance issues and scalability, but strict data consistency is required for business needs. In this case, we should group related functionality to their own single services and use local transactions.
Summary
In this article we have looked at the basics of transaction handling from ACID guarantees to loosening data consistency guarantees with BASE, and how the CAP theorem defines data store tradeoffs in a distributed system. We then analyzed the different data consistency levels that can be supported in distributed data stores and in general distributed processes. These data consistency concerns are directly applicable to modeling transactions in an MSA, where we need to bring together individual independent services to carry out a global transaction.
We looked at the benefits and tradeoffs of each approach and checked the general guidelines when selecting an option in relation to the business requirements.
Resources
- https://queue.acm.org/detail.cfm?id=1394128
- http://jepsen.io/consistency
- https://www.allthingsdistributed.com/2008/12/eventually_consistent.html
- https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html
- https://www.enterpriseintegrationpatterns.com/docs/IEEE_Software_Design_2PC.pdf
- https://ballerina.io/learn/by-example/transactions-distributed.html
Opinions expressed by DZone contributors are their own.
Comments