Protobuf Alternative to REST for Microservices
When JSON appears to be inefficient, Protocol Buffers can be a viable option...but how viable, exactly?
Join the DZone community and get the full member experience.
Join For FreeA few months ago a colleague and long-time friend of mine published an intriguing blog on a few of the less discussed costs associated with implementing microservices. The blog post made several important points on performance when designing and consuming microservices. There is an overhead to using a remote service beyond the obvious network latency due to routing and distance. The blog describes how there is a cost attributed to serialization of JSON and therefore a microservice should do meaningful work to overcome the costs of serialization. While this is a generally accepted guideline for microservices, it is often overlooked. A concrete reminder helps illustrate the point. The second point of interest is the costs associated with the bandwidth size of JSON based RESTful API responses. One potential pitfall of having a more substantive endpoint is that the payload of a response can degrade performance and quickly consume thread pools and overload the network.
These two main points made me think about alternatives and I decided to create an experiment to see if there were benefits from using Google Protocol Buffers ("Protobuf" for short) over JSON in RESTful API calls. I set out to show this by first highlighting performance differences between converting JSON using Jackson into POJOs versus Protobuf messages into and out of the a data model. I decided to create a sufficiently complex data model that utilized nested objects, lists, and primitives while trying to keep the model simple to understand. I ended up with a Recipe domain model that I would probably not use in a serious cooking application but that serves the purpose of this experiment.
Test 1: Measure Costs of Serialization and Deserialization
The first challenge I encountered was how to work effectively with Protobuf messages. After spending some time reading through sparse documentation that focused on an elementary demonstration of Protobuf messages, I finally decided on a method for converting messages in and out of my domain model. The preceding statements about using Protobufs is opinionated and someone who uses them often may disagree, but my experience was not smooth and I found messages to be rigid and more difficult than I expected.
The second challenge I encountered came when I wanted to measure the "performance" of both marshaling JSON and Serializing Protobufs. I spent some time learning JMH and designed my plan on how to test both methods. Using JMH, I designed a series of tests that allowed me to populate my POJO model, then construct a method that converted into and out of each of the technologies. I isolated the conversion of the objects in order to capture just the costs associated with conversion.
Results
My results were not surprising as I expected Protobuf to be more efficient. I measured the average time to marshal an object into JSON at 876.754 ns/operation.
(±43.222ns) vs. 148.160 ns/operation.
(±6.922ns) showing that equivalent objects converted into Protobuf was nearly 6 times faster than into JSON.
Reversing a JSON and Protobuf message into a POJO yielded slower results and were closer together, but Protobuf still outperformed JSON unmarshaling. Converting a JSON string into the domain object took on average 2037.075 ns/operation (±121.997) and Protobuf message to object took on average 844.382 ns/operation (±41.852), nearly 2.4 times faster than JSON.


Run the samples yourself using the GitHub project created for this project.
Test 2: Bandwidth Differences
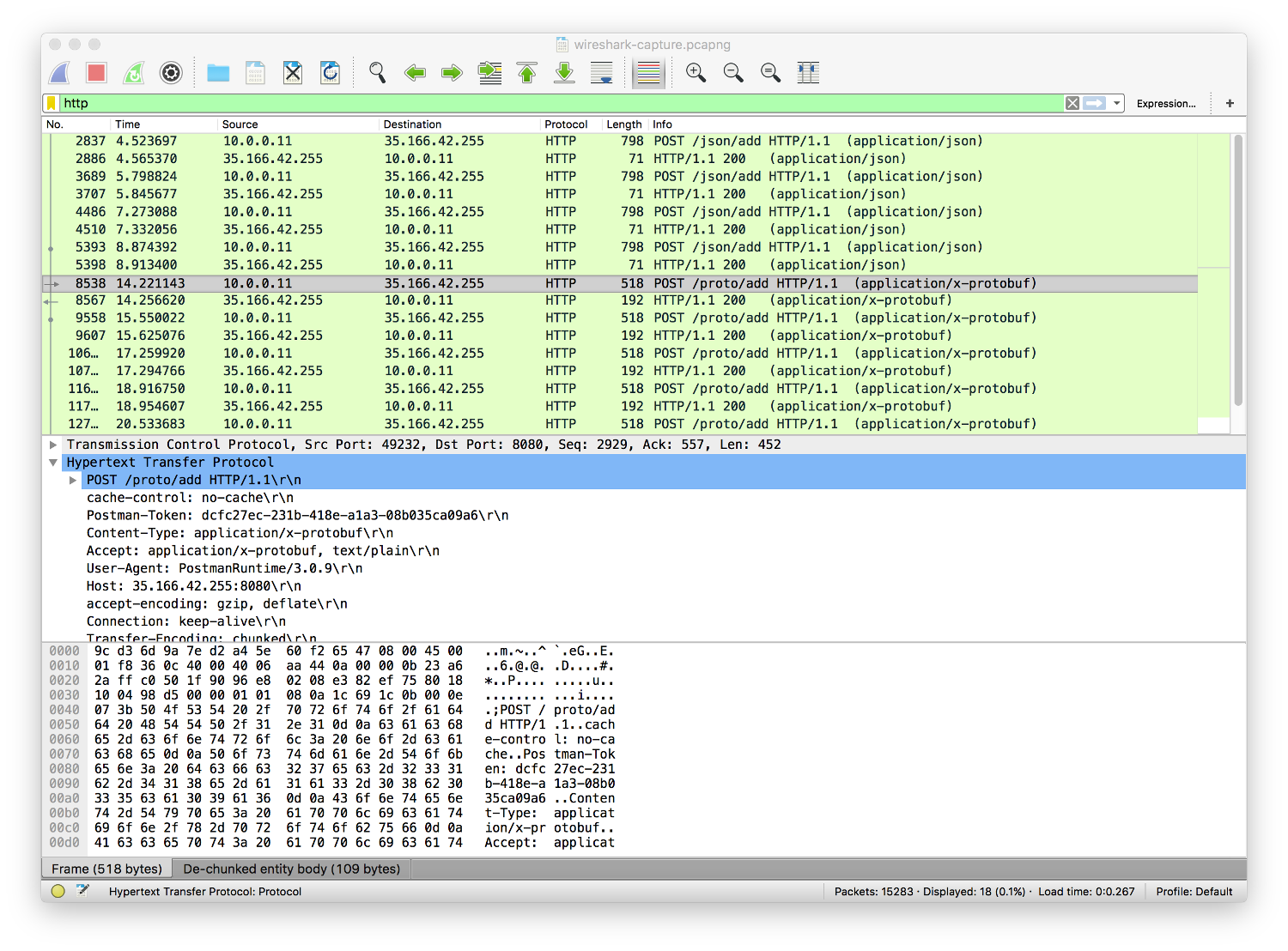
I did not find a straightforward way to capture bandwidth using traditional Java-based tools, so I decided to setup a service on AWS and communicate to the API using JSON and Protobuf requests. I then captured the traffic using Wireshark and calculated the total amount of bytes sent for these requests. I included the headers and payload in the calculation since both JSON and Protobufs require Accepts and Content-Type mime-type headers.
Results
The total size of the request for the JSON request was 789 bytes versus the Protobuf at 518 bytes. While the JSON request was 45% greater in size than the Protobuf, there was no optimization applied to either request. The JSON was minified but not compressed. Using compression can be detrimental to the overall performance of the solution based on the payload size. If the payload is too small, the cost of compressing and decompressing will overcome the benefits of a smaller payload. This is a very similar problem to the costs associated with marshaling JSON with small payloads as found by Jeremy's blog.
Conclusion
After completing a project to help determine the overall benefits of using Protobuf over JSON I have come to a conclusion that unless performance is absolutely critical and the developing team's maturity level is high enough to understand the high costs of using Protobufs, then it is a legitimate option to increase the performance associated with message passing. That being said, the costs of working with Protobufs is very high. Developers lose access to human-readable messages often useful during debugging. Additionally, Protobufs are messages, not objects and therefore come with more structure and rigor, which I found to be complicated due to the inflexibility using only primitives and enums. Also, updating messages requires the developer to mark new fields as "optional" for backward compatibility. Lastly, there is limited documentation on Protocol Buffers beyond the basic "hello world" applications.
Published at DZone with permission of Mike Ensor, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments