Using the Scientific Method To Debug Containerized Applications
Let's look at a sample app that works locally, but fails when deployed, and how you might use the scientific method to debug the failures in containerized apps.
Join the DZone community and get the full member experience.
Join For FreeAh yes—“It works fine on my machine!” Perhaps the most famous saying in our industry. Even with the advent of containers that provide consistent environments across the SDLC, we still hear developers fall back to this claim when a defect is found. But in the end, if the code doesn't work in test or production, it doesn't work—even if it works locally. So as a developer, being able to deep dive into your containerized application to fix the problem—regardless of the environment—is a critical skill we must all learn.
Let's look at a sample app that works locally, but fails when deployed, and how you might use the scientific method (you remember that from school, right?) to debug these failures in containerized apps.
Our Example
For our example, we'll use a simple Flask application—deployed in a Kubernetes container—that displays the famous people that have used our app. It works flawlessly on our local system!

Now let's deploy this to our Heroku service and see if it’ll behave the same (hint: it won't).
heroku container:push worker -a heroku-troubleshooting
heroku container:release worker -a heroku-troubleshooting

Drats! Foiled by the production environment powers that be. Now we can start digging into what happened and see what tools we have at our disposal.
Our Approach
When your app fails, it's helpful to take an unbiased and objective approach to triage the issue and understand the faults. One such classical approach is the Scientific Method. Harnessed through hundreds of years of rigorous repetition and review, I've found that this method works great for modern debugging.
Too often developers and DevOps engineers take a "let's see what this does" scattered approach to debugging. We grab the first thing that comes to mind that might be wrong, change our code/config around, deploy, and see if that worked. And if that doesn't work, we just keep trying, sometimes forgetting what we've already tried, sometimes spending hours or even days going down a path that if we just stopped and thought about it for a minute, clearly is the wrong path.
But if we use a more reasoned, structured approach - like the scientific method - our debugging process could be more productive, faster, and in the end, better.
The scientific method, at its most basic, involves forming a hypothesis, conducting experiments, observing the results, and then refining your hypothesis. The scientific method as I apply it to debugging containerized apps looks like this:
- Ask "What should be happening?"
- Determine reasons that might explain why it's not happening
- Design a test to validate/invalidate those claims by tuning a config or using a tool
- Observe the outcome
- Draw a conclusion
- Repeat until the outcome is what should be happening
The Scientific Method in Action
Now let's see that approach in action.
1. Ask "What should be happening?"
First, we need to understand what our application is trying to do. To start investigating, we need to understand the details of the page rendering. Let’s see how the Dockerfile describes our service:
FROM python:3 WORKDIR /usr/src/app COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt RUN echo "healthy" >> /tmp/healthy && \cat /tmp/healthy ENV FLASK_ENV=development ENV FLASK_APP=myapp.py COPY myapp.py . CMD [ "python3", "myapp.py" ]
Pretty simple. We have a Python3 application, it installs some requirements, and then starts myapp.py. Let’s take a quick look at what our Python application is doing and then we can decide how to best proceed.
from flask import Flask, Response import os import psycopg2 app = Flask(__name__) query = ("select * from actor order by random() limit 5;") host = os.getenv("host") password = os.getenv("PSQL_PASSWORD") user = os.getenv("PSQL_USERNAME") dbname = os.getenv("PSQL_DBNAME") print(host) print(user) print(dbname) def callpsql():conn = psycopg2.connect(dbname=dbname, user=user, password=password, host=host, port="5432")cur = conn.cursor()cur.execute(query)results = cur.fetchall()cur.close()conn.close()return results @app.route('/') def index():response = callpsql()print("Getting some juicy logs")results = "I've sold to these famous people from server "+os.getenv("DYNO")+": <br>\n"for row in response:results = results+"<br>\n"+str(row[1])+"\t"+str(row[2])return results @app.route('/health') def health():f = open("/tmp/healthy", "r")print(f)health = f.readline().rstrip()resp = Response(health)if health != "healthy":resp.status=500resp.headers['health-check'] = healthreturn resp if __name__ == "__main__":port = 5000app.run(debug=True, host='0.0.0.0', port=port)
Another pretty simple application. This takes a few environment variables for authentication and executes a SQL query against a Postgres database when the root page is called.
2. Determine reasons that might explain why it's not happening
Now that we know what the application is trying to do, we move to the next step—explain why it's not happening in our new environment.
Here we can look at the Heroku logs --tail command that’s suggested on the error page. This should give us a good idea of what our service is doing at any point in time and also help us form a hypothesis as to what might be the problem.
$ heroku logs --tail -a heroku-troubleshooting
...
2020-08-22T22:45:34.805282+00:00 heroku[router]: at=error code=H14 desc="No web processes running" method=GET path="/" host=heroku-troubleshooting.herokuapp.com request_id=09292b76-b372-49e9-858b-e8611c020fd5 fwd="xx.xx.xx.xx" dyno= connect= service= status=503 bytes= protocol=https
…We see the error “No web processes running” appear every time we load the page. It seems as though Heroku doesn’t know that we’ve started Flask. Great! We have our hypothesis - "Flask probably isn't running in Heroku's environment."
3. Design a test to validate/invalidate those claims by tuning a config or using a tool
Now let's move to the next steps: create a test to validate what we think is happening, observe the outcome, and draw a conclusion.
So let's test our hypothesis - we'll hop onto our dyno and validate that the Flask service is (or is not) actually running. Our Dockerfile specifies python should be a running, listening service.
$ heroku ps:exec -a heroku-troubleshooting Establishing credentials... error▸ Could not connect to dyno!▸ Check if the dyno is running with `heroku ps'
4. Observe the outcome
We released our container, so it should be running. However, the logs from out test have shown us that we couldn’t connect to the dyno that should be running the code. Executing the suggested command may give us another clue.
$ heroku ps -a heroku-troubleshooting
No dynos on ⬢ heroku-troubleshooting
5. Draw a conclusion
Well, this is embarrassing. The scientific method conclusion? We were wrong in our initial assertion that our released code left us with a running dyno to serve the code. We definitely pushed and released our image but we didn’t add any dynos to our application. It appears we have validated that the application is not running and that our hypothesis was incorrect.
6. Repeat until the outcome is what should be happening
So we move to the next step, which is repeat the process—and we'll continue to repeat this process throughout this article until our problem is solved.
So let's form a new hypothesis and test it. Our new hypothesis, based on the last test, is that with the dyno running, we should be able to reach our Flask application from the outside world. We'll scale a dyno up to start the application and check the logs again to test that assertion.
$ heroku dyno:scale -a heroku-troubleshooting worker=1
Scaling dynos... done, now running worker at 1:Standard-1X
$ heroku logs --tail -a heroku-troubleshooting
2020-08-22T23:29:05.207217+00:00 app[api]: Scaled to worker@1:Standard-1X by user
2020-08-22T23:29:18.202160+00:00 heroku[worker.1]: Starting process with command `python3 myapp.py`
2020-08-22T23:29:18.760500+00:00 heroku[worker.1]: State changed from starting to up
2020-08-22T23:29:21.559386+00:00 app[worker.1]: None
2020-08-22T23:29:21.559547+00:00 app[worker.1]: None
2020-08-22T23:29:21.559548+00:00 app[worker.1]: None
2020-08-22T23:29:21.559549+00:00 app[worker.1]: * Serving Flask app "myapp" (lazy loading)
2020-08-22T23:29:21.559556+00:00 app[worker.1]: * Environment: development
2020-08-22T23:29:21.559556+00:00 app[worker.1]: * Debug mode: on
2020-08-22T23:29:21.636027+00:00 app[worker.1]: * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
2020-08-22T23:29:21.637965+00:00 app[worker.1]: * Restarting with stat
2020-08-22T23:29:21.897821+00:00 app[worker.1]: * Debugger is active!
2020-08-22T23:29:21.929543+00:00 app[worker.1]: * Debugger PIN: 485-744-571There we go. Now the application has started! It's time to test the site again to observe if it’s working.
Our conclusion now, is it’s definitely not. We should go over our commands again and see if the status has changed at all so that we can create a new hypothesis.
$ heroku logs -a heroku-troubleshooting2020-08-22T23:32:12.098568+00:00 heroku[router]: at=error code=H14 desc="No web processes running" method=GET path="/" host=heroku-troubleshooting.herokuapp.com request_id=4d3cbafa-cb31-4452-bfc6-7ee18ce72eb0 fwd="xx.xx.xx.xx" dyno= connect= service= status=503 bytes= protocol=https
$ heroku ps -a heroku-troubleshooting=== worker (Standard-1X): python3 myapp.py (1)worker.1: up 2020/08/22 16:31:59 -0700 (~ 3m ago)
It looks like we’re running a service but we can’t get any more data using only the logs. Hypothetically we can get into the service and make sure it’s working.
$ heroku ps:exec -d worker.1 -a heroku-troubleshooting Establishing credentials... error▸ Could not connect to dyno!▸ Check if the dyno is running with `heroku ps'
Here we can observe that even with the dyno running, we can't connect to it. Looking back at our Dockerfile and some documentation, we can conclude that there are a few requisites needed for the Heroku environment to support exec into the deployed containers. We should add a few utility commands we might need while we’re in here to test future hypotheses while we test if this new configuration will allow us to connect.
... RUN apt-get update && \apt-get install -y \curl \openssh-server \net-tools \dnsutils \iproute2 RUN mkdir -p /app/.profile.d && \touch /app/.profile.d/heroku-exec.sh && \echo '[ -z "$SSH_CLIENT" ] && source <(curl --fail --retry 3 -sSL "$HEROKU_EXEC_URL")' >> /app/.profile.d/heroku-exec.sh && \chmod +x /app/.profile.d/heroku-exec.sh ...
One more push and release later and we've validated our conclusion was correct and we can finally connect:
$ heroku ps:exec -d worker.1 -a heroku-troubleshooting
Establishing credentials... done
Connecting to worker.1 on ⬢ heroku-troubleshooting...
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
~ $Now that we’re in the application, we can check our hypothesis that the port is listening as it should be and that our application is responsive from within the container itself. We can utilize “net-tools” netstat command as a test to show us a list of ports that are open on our container and listening for calls to open a socket.
~ $ netstat -apn | grep 5000 | grep LIST
(Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:5000 0.0.0.0:* LISTEN 3/python3Our analysis shows that the port is open as expected and our hypothesis is correct.
Because nothing has changed, we must design a new test. “Curl” can act as our command-line internet browser to show us a simplified view into the port we now verified is open and listening properly.
~ $ curl -I localhost:5000 HTTP/1.0 500 INTERNAL SERVER ERROR Content-Type: text/html; charset=utf-8 X-XSS-Protection: 0 Server: Werkzeug/1.0.1 Python/3.8.5 Date: Sun, 23 Aug 2020 00:27:14 GMT ~ $ curl localhost:5000 ... psycopg2.OperationalError: could not connect to server: No such file or directoryIs the server running locally and acceptingconnections on Unix domain socket "/var/run/postgresql/.s.PGSQL.5432"? ...
Ah-ha! Our analysis of this error proves that the calls are failing because we’re getting a 500 error in our application. Our new hypothesis is that this is surely at least one reason why Heroku won’t send traffic to our application. If we look back at our Python code, we can see that it requires some environment variables. In our local host, we have them exported as part of a development virtual environment. We can now conclude these need to be added to our application in Heroku as well.
Our new hypothesis becomes "The service should work as expected in both the local and production environments."
To test this hypothesis and pick up the new change, we'll need to restart our worker which should let the application pick up the new environment variables.
$ heroku ps:restart worker.1 -a heroku-troubleshooting
Restarting worker.1 dyno on ⬢ heroku-troubleshooting... done
$ heroku ps:exec -d worker.1 -a heroku-troubleshooting
Establishing credentials... done
Connecting to worker.1 on ⬢ heroku-troubleshooting...
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
~ $ curl -I localhost:5000
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 148
Server: Werkzeug/1.0.1 Python/3.8.5
Date: Sun, 23 Aug 2020 00:50:35 GMT
~ $ curl localhost:5000
I've sold to these famous people from server worker.1: <br>
<br>
Julianne Dench<br>
Sylvester Dern<br>
Greta Keitel<br>
Dustin Tautou<br>
Penelope MonroeWe’ve now validated that the local container is working as we expect after re-running our previous tests. Still, our logs and browser conclude that the app is still not functioning as expected.
Logs from our internal curls
2020-08-23T00:50:35.931678+00:00 app[worker.1]: 127.0.0.1 - - [23/Aug/2020 00:50:35] "[37mHEAD / HTTP/1.1[0m" 200 -
2020-08-23T00:50:41.807629+00:00 app[worker.1]: 127.0.0.1 - - [23/Aug/2020 00:50:41] "[37mGET / HTTP/1.1[0m" 200 -
Logs from our external browser
2020-08-23T00:50:47.151656+00:00 heroku[router]: at=error code=H14 desc="No web processes running" method=GET path="/" host=heroku-troubleshooting.herokuapp.com request_id=a9421f09-94f2-4822-9608-f2f63ffe5123 fwd="68.251.62.251" dyno= connect= service= status=503 bytes= protocol=https
With the application working in the container, it seems that everything should be working fine, hypothetically. Utilizing our prior re-run of tests and taking a closer analysis of the error “No web processes running” gives us another hint. There are two types of dynos, and we’ve deployed this as a “worker” dyno. Looking at the documentation, we can conclude that perhaps we’ve deployed to the wrong resource type that does not get an ingress. Hypothetically Heroku should provide a dynamic external port if we configure the dyno as "web" instead of "worker". Time to test redeploying as a “web” dyno.
heroku ps:scale worker=0 -a heroku-troubleshooting
heroku container:push web -a heroku-troubleshooting
heroku container:release web -a heroku-troubleshooting
heroku ps:scale web=1 -a heroku-troubleshootingBrowsing to the site still gives the same conclusion as our initial tests, but now our observed logs are giving us our next thread to investigate.
2020-08-23T01:03:12.890612+00:00 app[web.1]: * Serving Flask app "myapp" (lazy loading)
2020-08-23T01:03:12.890619+00:00 app[web.1]: * Environment: development
2020-08-23T01:03:12.890620+00:00 app[web.1]: * Debug mode: on
2020-08-23T01:03:12.905580+00:00 app[web.1]: * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
2020-08-23T01:03:12.906860+00:00 app[web.1]: * Restarting with stat
2020-08-23T01:03:13.661451+00:00 app[web.1]: * Debugger is active!
2020-08-23T01:03:13.662395+00:00 app[web.1]: * Debugger PIN: 196-723-097
2020-08-23T01:04:07.990856+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch
2020-08-23T01:04:08.016515+00:00 heroku[web.1]: Stopping process with SIGKILL
2020-08-23T01:04:08.224860+00:00 heroku[web.1]: Process exited with status 137
2020-08-23T01:04:08.290383+00:00 heroku[web.1]: State changed from starting to crashed
2020-08-23T01:04:08.293139+00:00 heroku[web.1]: State changed from crashed to starting
“Web process failed to bind to $PORT” We can conclude that we need to bind our process to a variable rather than our default Flask port. This is simple enough to fix in our Python application. If we have the correct variable mapped in our production environment, and our application is utilizing that as its port configuration, then we should have a fully functioning site. To test this we can pass in the environment variable from the host and use it in our app.run argument.
myapp.py if __name__ == "__main__":port = int(os.getenv("PORT", 5000))app.run(debug=True, host='0.0.0.0', port=port)
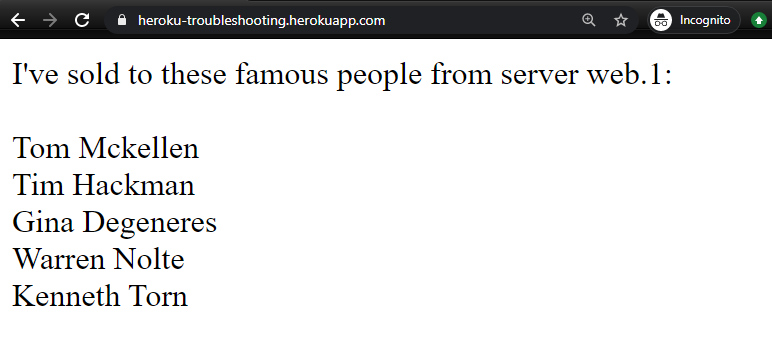
And there you have it! Our analysis of the test shows that the app works on both locally and when deployed. One final validation to ensure that our changes continue to work in our development environment as well.
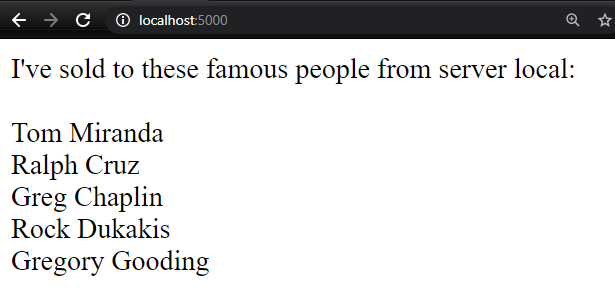
Putting It Together
In this workflow, we used the scientific method to investigate an application that was failing to render in production. Debugging a managed infrastructure is a daunting task, but only because of the sum of its parts. By breaking down each layer of the product, reviewing how it behaves with standardized tooling, taking clues from the outputs of the logs and application outputs, and reviewing various product documentation, we can break down these complex structures to meaningful and simple conclusions that will resurrect any service.
If you want to further analyze the app that we deployed, you can see it here. Next time you find yourself investigating a difficult problem, remember to take each component one layer at a time and apply methodical, scientific, approaches to the process. By doing this you can remove much of the personal bias that would otherwise potentially derail you into a wild goose chase of StackOverflow articles and random community forums.
Opinions expressed by DZone contributors are their own.
Comments