Working Principles of Generative Adversarial Networks (GANs)
Take a look at working principles of Generative Adversarial Networks (GANs) and explore the principles of GAN as well as a video of what they are and how they work.
Join the DZone community and get the full member experience.
Join For FreeThe following is an excerpt from Packt’s upcoming book, Advanced Deep Learning with Keras by Rowel Atienza.
EDITOR'S NOTE: Some of the formulas included within the body text of this article didn't copy over perfectly from the original book. We did our best to carry over the formulas as closely as possible.
In this article, the working principles of Generative Adversarial Networks (GANs) are discussed.
GANs [Goodfellow, 2016] belong to the family of generative models. Unlike autoencoders, generative models can create new meaningful outputs given arbitrary encodings. For example, GANs can generate new celebrity faces that are not of real people by performing latent space interpolations (Progressive Growing of GANs, Karras and others, 2018). This is something that cannot be accomplished easily by autoencoders.
Take a closer look at what Generative Adversarial Networks (GANs) are and how they work.
GANs learn to model the input distribution by training two competing (and cooperating) networks called generator and discriminator (aka critic). The role of the generator is to keep on figuring out how to generate fake data or signals (that is, audio, image, and more) that can fool the discriminator. On the other hand, the discriminator is trained to distinguish between fake and real signals. As the training progresses, the discriminator can no longer see the difference between synthetically generated data from real ones. The discriminator can be discarded, and the generator can be used to create new realistic signals that have never been observed before.
The underlying concept of GANs is straightforward. The most challenging aspect is how to achieve stable training of the generator-discriminator network. There must exist a healthy competition between the generator and discriminator for both networks to learn simultaneously. Since the loss function is computed from the output of the discriminator, its parameters update is fast. When the discriminator converges faster, the generator no longer receives sufficient gradient updates for its parameters. The generator fails to converge. Other than being hard to train, GANs suffer from partial or total modal collapse, a situation wherein the generator is producing almost similar outputs for different latent encodings.
Principles of GAN

Figure 1: The generator and discriminator of GANs are analogous to the counterfeiter and the police. The goal of the counterfeiter is to fool the police into believing that the dollar bill is real.
As shown in Figure 1, GAN is analogous to counterfeiter (generator) — police (discriminator) setup. At the academy, the police are taught how to determine if a dollar bill is genuine or fake. Samples of real dollar bills from the bank and fake money from the counterfeiter are used to train the police. However, from time to time, the counterfeiter will attempt to pretend that he printed real dollar bills. Initially, the police are not fooled and will tell the counterfeiter why the money is fake. Taking into consideration this feedback, the counterfeiter hones his skills and attempts to produce new fake dollar bills. As expected the police can spot the money as fake and justifies why the dollar bills are fake. When this scenario continues indefinitely, time will come when the counterfeiter has mastered his skills in making fake dollar bills that are indistinguishable from real ones. The counterfeiter can then infinitely print dollar bills without getting caught.
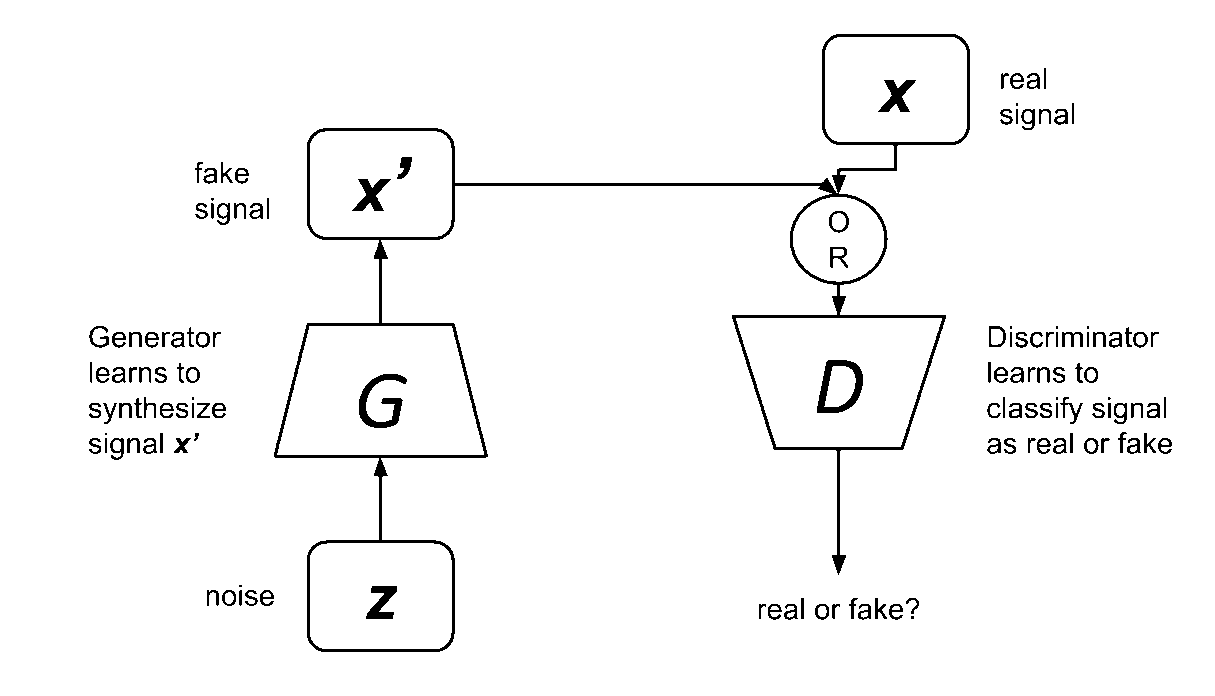
Figure 2: A GAN is made up of two networks: a generator and discriminator. The discriminator is trained to distinguish between real and fake signals or data. The generator learns to generate fake signals or data that can eventually fool the discriminator.
As shown in Figure 2, a generative adversarial network is made up of two networks, a generator, and a discriminator. The input to the generator is noise, and the output is a synthesized signal. Meanwhile, the discriminator’s input is either a real or a synthesized signal. Genuine signals come from true sampled data while fake signals come from the generator. All valid signals are labeled 1.0 (that is, 100% probability being real) while all synthesized signals are labeled 0.0 (that is, 0% probability being real). Since the labeling process is automated, GAN is still considered part of unsupervised learning approach in deep learning.
The objective of the discriminator is to learn from this supplied dataset how to distinguish real from fake signals. During this part of GAN training, only the discriminator parameters are updated. Like a typical binary classifier, the discriminator is trained to predict 0.0 to 1.0 confidence values on how close a given input signal to the true one. However, this is only half of the story. On regular intervals, the generator will pretend that its output is a genuine signal and will ask GAN to label it as 1.0. When the fake signal is presented to the discriminator, naturally it will be classified as fake with a label close to 0.0. The optimizer computes generator parameter updates based on the presented label (that is, 1.0) and its own prediction to take into account this new training data. In other words, the discriminator has some level of doubts about its prediction and GAN takes that into consideration. This time, GAN will let the gradients back propagate from the last layer of the discriminator down to the first layer of the generator. However, in most practices, during this phase of training, the discriminator parameters are temporarily frozen. The generator uses the gradients to update its parameters and improve its ability to synthesize fake signals.
Overall, the whole process is like two networks competing with one another while cooperating at the same time. When the GAN training converges, the end result is a generator that can synthesize signals. The discriminator thinks these synthesized signals are real or with label near 1.0. The discriminator can then be discarded. The generator part will be useful in producing meaningful outputs from arbitrary noise inputs.
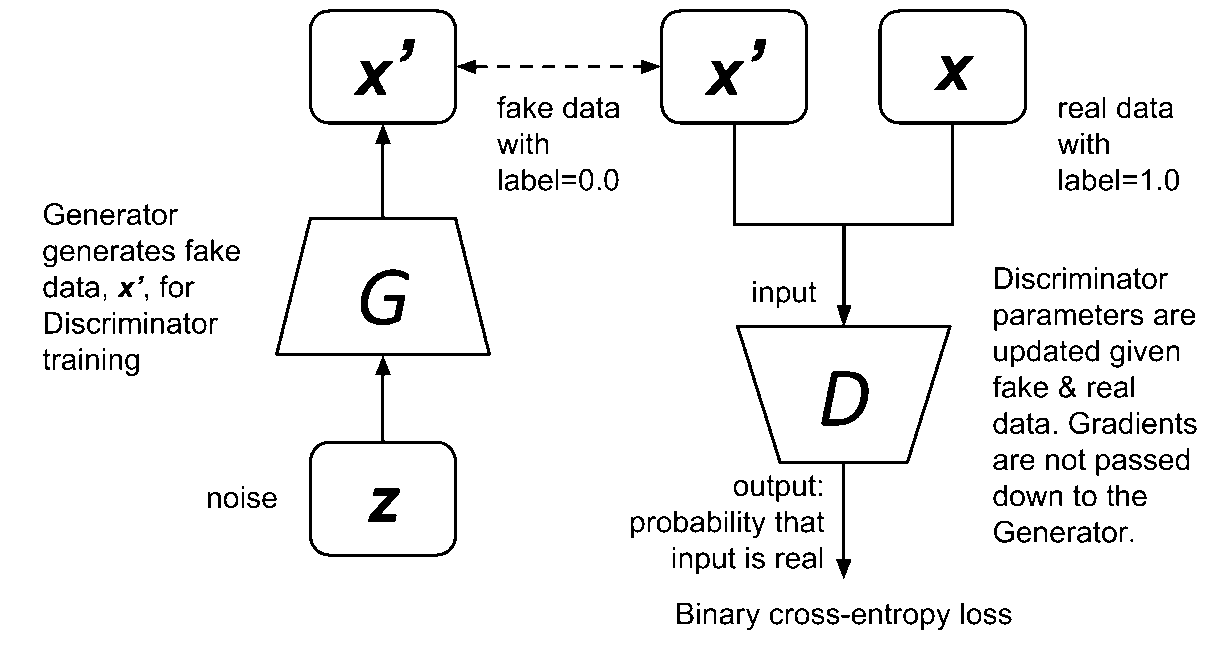
Figure 3: Training the discriminator is similar to training a binary classifier network using binary cross-entropy loss. Fake data is supplied by the generator while real data is from true samples.
As shown in Figure 3, the discriminator can be trained by minimizing the loss function in the following equation:
 Eq. 1
Eq. 1
This is just the standard binary cross-entropy cost function. The loss is the negative sum of the expectation of correctly identifying real data, o, and the expectation of 1.0 minus correctly identifying synthetic data, 1-D(G(z)) . The log does not change the location of the local minima. Two mini-batches of data are supplied to the discriminator during training:
1) x , real from sampled data (that is, x~p_data) with label 1.0 and 2) x^'=G(z) , fake data from the generator with label 0.0. In order to minimize the loss function, the discriminator parameters, θ^((D)) , are updated through back propagation by correctly identifying genuine data, D(x) , and synthetic data, 1-D(G(z)) . Correctly identifying real data is equivalent to D(x)→1.0 while correctly classifying fake data is the same as D(G(z))→0.0 or (1-D(G(z)))→1.0 . z is the arbitrary encoding or noise vector that is used by the generator to synthesize new signals. Both contribute to minimizing the loss function.
To train the generator, GAN considers the total of the discriminator and generator losses as a zero-sum game. The generator loss function is simply the negative of the discriminator loss function: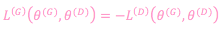
Eq. 2
This can be rewritten more aptly as a value function:
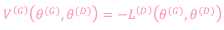
Eq. 3
From the perspective of the generator, Equation 3 should be minimized. From the point of view of the discriminator, the value function should be maximized. Therefore, the generator training criterion can be written as a minimax problem:
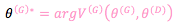
Eq. 4
Occasionally, we try to fool the discriminator by pretending that the synthetic data is real with label 1.0. By maximizing with respect to θ^((D)) , the optimizer sends gradient updates to the discriminator parameters to consider this synthetic data as real. At the same time, by minimizing with respect to θ^((G)) , the optimizer trains the generator parameters on how to trick the discriminator. However, in practice, the discriminator is confident of its prediction in classifying synthetic data as fake and will not update its parameters. Furthermore, the gradient updates are small and have diminished significantly as they propagate to the generator layers. The generator fails to converge.
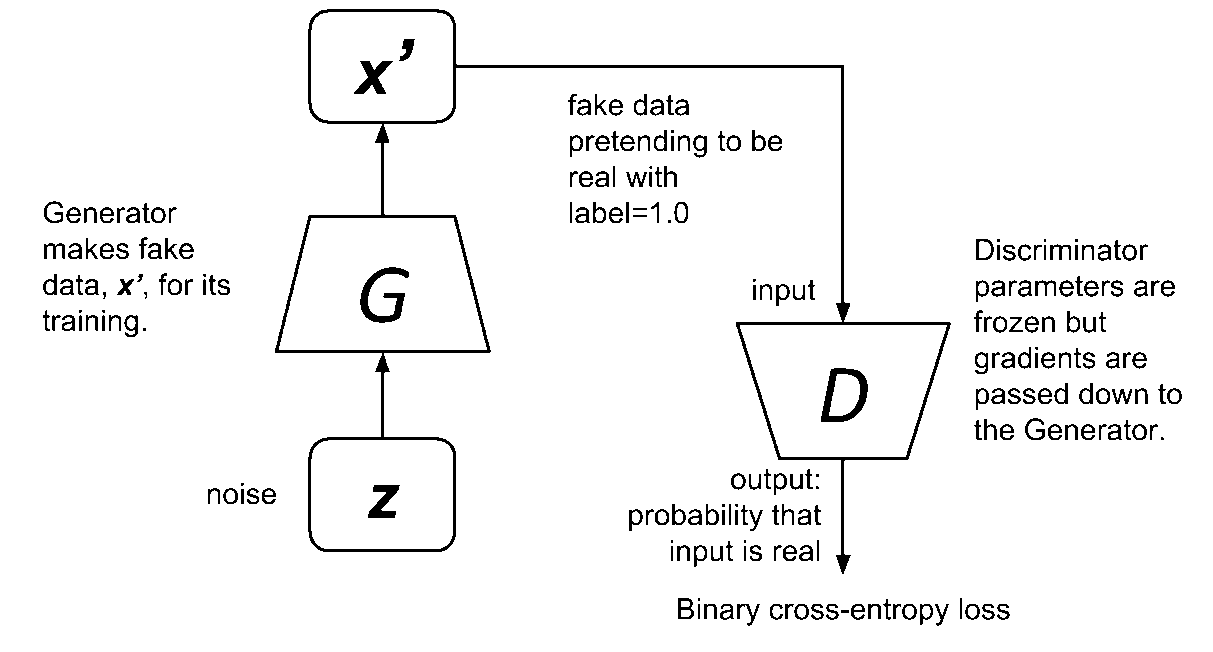
Figure 4: Training the generator is like training a network using binary cross-entropy loss function. The fake data from the generator is presented as genuine.
The solution is to reformulate the loss function of the generator in the form: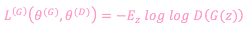
Eq. 5
The loss function simply maximizes the chance of the discriminator in believing that the synthetic data is real by training the generator. The new formulation is no longer zero-sum and is purely heuristics-driven. Figure 4 shows the generator during training. In this figure, the generator parameters are updated only when the whole adversarial network is trained since the gradients are pass down from the discriminator to the generator. However, in practice, the discriminator weights are temporarily frozen during adversarial training.
In deep learning, both the generator and discriminator can be implemented using a suitable neural network architecture. If the data or signal is an image, both the generator and discriminator networks use Convolutional Neural Networks (CNN). For single-dimensional sequences like in Natural Language Processing (NLP), both networks are usually recurrent.
This article discussed the general principles behind GAN. GAN is made up of two networks called generator and discriminator. The role of the discriminator is to discriminate real from fake signals. The aim of the generator is to fool the discriminator. The generator is normally combined with the discriminator to form an adversarial network. It is through training the adversarial network that the generator learns how to produce fake signals that can trick the discriminator.
You just read an excerpt from the upcoming book Advanced Deep Learning with Keras written by Rowel Atienza and published by Packt.

Opinions expressed by DZone contributors are their own.
Comments