The first step toward securing APIs is to have a deeper understanding of foundational elements of APIs such as:
Transport Layer Security
The Transport Layer Security (TLS) protocol is the de-facto transport-level cryptographic protocol to ensure secure communications over a TCP/IP network. An encrypted transport layer is essential for APIs to ensure that attackers are unable to eavesdrop data or tokens “on the wire” as they are transmitted and to ensure that the client can validate the integrity of the server (via certificate checking). Certificate management has traditionally presented challenges to organizations; however, with the emergence of providers such as Let’s Encrypt certificate deployment has become relatively trivial. All new API development should secure a communications network as a first line of defense.
Rate Limiting
Public APIs serve as the gateway to a business and, as such, must be protected from abuse via denial-of-service (DoS) attacks. An adversary can trivially launch automated attacks against APIs, which can either degrade performance for legitimate users or destroy the API due to resource exhaustion on the server. A secondary attack vector is to attempt to brute force either a sign-up endpoint or a password reset endpoint by rapidly guessing passwords or hashes with a dictionary attack.
Both types of attack may be mitigated using rate-limiting technology, which limits repeated and frequent access from a particular IP address to a given endpoint. Rate limiting is typically implemented in an API gateway or dedicated protection product (such as a WAF or API firewall).
Access Control
Access control is a key foundation of API security and encompasses two elements — firstly, authentication determines who is accessing an API, and authorization determines what they are allowed to do within the API.
No Authentication
Public APIs intended for read-only use may not require authentication at all if they are intended for anonymous access. Typically, these endpoints are used for information and status information.
Basic Authentication
Basic authentication is a largely outdated method with origins in early website authentication. The client provides a username and password, which are encoded as a Base64 string, transmitted in the request headers, and verified by the server. Weaknesses of this method included lack of revocation and clear text transmission of credentials. This method is not recommended for new designs.
Session Cookies
Another authentication technique with origins in website authentication is the use of session cookies. Once authenticated via a sign-in page, the client can store a session cookie, which is presented to the server on subsequent authentication requests. This, again, is not a recommended solution since session cookies are vulnerable to leakage (via cross-origin script attacks) and lifetime management challenges (expiration and revocation).
Bearer Authentication
Bearer authentication seeks to eliminate some of the weaknesses in the basic authentication method by using a hashed value of the user credentials rather than transmitting the credential to the server. The protocol consists of two API operations — the first call returns a 401 Unauthorized code and a header called WWW-Authenticate with a hash value and a nonce. The second issues a call to authenticate with the hash values to generate an authorization header which is stored for subsequent access. Although better than basic authentication, this method still has weaknesses such as vulnerability to machine-in-the-middle attacks.
API Keys
API keys are a staple of API authentication due to their simplicity and robustness when managed correctly. The server generates a key (with an optional lifetime) for a given client using a management portal (typically a website allowing account management). The client stores this key and submits it via a header in all API requests, and the server validates this key. Challenges arise with the storage of keys since clients (mobile applications and single-page web applications) typically do not provide secure storage. Additional challenges exist with the lifetime management of keys and subsequent re-issuing of revoked keys. API keys are well suited to service APIs within a microservice architecture and less suited to end-user applications.
OAuth 2.0
OAuth 2.0 has become the de-facto standard for authentication of API clients, and the provision of permissions (authorization) on servers. In essence, OAuth is a flow to allow a user to verify an identity to an authorization server (typically via a login page), to then allow the requested access permissions (roles), and to receive a token which is used in subsequent access. The client acts on behalf of the user and does not have access to the user’s credentials and has only specific access permissions.
OAuth provides several flows (grant types) to allow access tokens from the server, depending on the client type. Certain flows have been deprecated, and the two most common in use now are:
- Authorization Code: This is the recommended flow for back-end clients capable of securely storing tokens. The client initially authenticates with the authorization server (in a web page usually) and receives an authorization code which is then exchanged for an access token, and optionally a refresh token. The access token can be short-lived to mitigate leakage vulnerabilities, requiring clients to re-authenticate or use the refresh token.
- Authorization Code with PKCE: This augments the Authorization Code flow to include a code verifier challenge to ensure that attackers intercepting the code cannot exchange this for a valid token. Typically, this flow is recommended for native applications and single-page applications, which are unable to store client secrets.
OpenID Connect Discovery
OpenID Connect (OIDC) is an identity layer built on top of OAuth and is supported by OAuth providers such as Google and Azure Active Directory. As a final stage of the authentication process, the client can receive information (called claims) specific to the user, such as username, email, etc. This information is typically returned in a JWT token, allowing the client to verify the integrity of such information.
Authorization
Once a client has identified itself, the server will need to assess whether the client has the necessary permission to access the requested resource. Typically, two types of access control may be applied — firstly at the request level (the endpoint URL) and secondly at the object (or data) level. Certain functions may have public access, while others must require authentication that can be handled using the application middleware (i.e., Spring Boot, ASP.NET Core, etc.).
For more fine-grained permissions, such as object level, the business logic should enforce these controls using typical access control models (RBAC, ABAC). Complex authorization requirements are best handled with dedicated libraries or frameworks such as Open Policy Agent, which provide a single point of enforcement for access policy.
Tokens (JWTs)
The final fundamental of APIs is the JSON Web Token (JWT) used to transfer information between client and server in a portable and robust way. JWTs are cryptographically secure, allowing a client to verify the integrity of the message by using public-key cryptography methods to validate the content. Being JSON, they are easily transmitted in APIs as part of the request header or body.
A JWT comprises three parts: the header, the claim, and the signature (or HMAC).
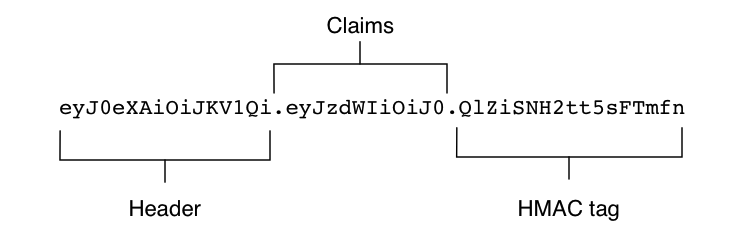 The header provides basic information regarding the JWT and, most importantly, the algorithm type used to produce the JWT.
The header provides basic information regarding the JWT and, most importantly, the algorithm type used to produce the JWT.
The claims section contains server-specific data (the claims) in a key-value pair notation. Registered claims include basics such as issuer, expiration time, subject, audience, etc. Although not mandatory, these are strongly recommended. The public claims section contains specific data such as client roles, permissions, identity, etc.
The signature is a hash of the Base64Url versions of the header and the claims, and a server-side secret. By verifying the signature, a client can verify the message body was not changed in transit. If used with a private/public key combination, it can verify the signatory’s identity. In addition to signature validation, JWT claims should be fully validated to ensure the validity of expiration date, source addresses, usernames, etc.
JWTs (specified by RFC 8725) are ubiquitous and applicable to identity authorization solutions; however, care must be exercised when producing and consuming JWTs to avoid several common pitfalls.

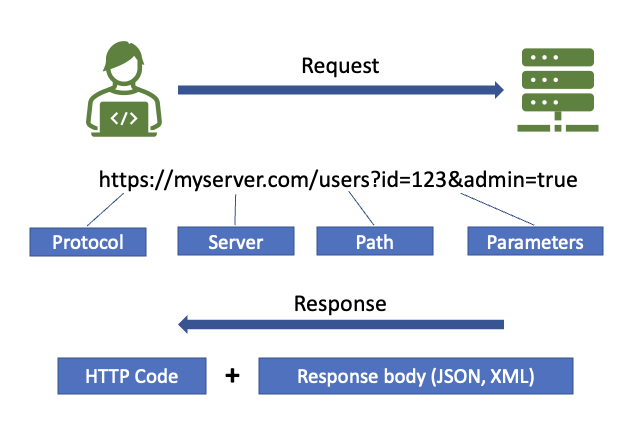 A transaction between client and server comprises a request being made to a given endpoint which consists of a base URL (the domain of the server), a method (the path portion of the URL), and optional parameters. A request specifies the method (often called the verb) to be used; additionally, a body (typically JSON or XML) can be enclosed in the request.
A transaction between client and server comprises a request being made to a given endpoint which consists of a base URL (the domain of the server), a method (the path portion of the URL), and optional parameters. A request specifies the method (often called the verb) to be used; additionally, a body (typically JSON or XML) can be enclosed in the request.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}