Graph-Oriented Solutions Enhancing Flexibility Over Mutant Requirements
An Enterprise experience with Neo4j graph-oriented DBMS on a JakartaEE RESTful architecture for satisfying frequent changes in software requirements in Agile approaches.
Join the DZone community and get the full member experience.
Join For FreeRelational DataBase Management Systems (RDBMS) represent the state-of-the-art, thanks in part to their well-established ecosystem of surrounding technologies, tools, and widespread professional skills.
During this era of technological revolution encompassing both Information Technology (IT) and Operational Technology (OT), it is widely recognized that significant challenges arise concerning performance, particularly in specific use cases where NoSQL solutions outperform traditional approaches. Indeed, the market offers many NoSQL DBMS solutions interpreting and exploiting a variety of different data models:
- Key-value store (e.g., the simplest storage where the access to persisted data must be instantaneous and the retrieve is made by keys like a hash-map or a dictionary);
- Documented-oriented (e.g., widely adopted in server-less solutions and lambda functions architectures where clients need a well-structured DTO directly from the database);
- Graph-oriented (e.g., useful for knowledge management, semantic web, or social networks);
- Column-oriented (e.g., providing highly optimized “ready-to-use” data projections in query-driven modeling approaches);
- Time series (e.g., for handling sensors and sample data in the Internet of Things scenarios);
- Multi-model store (e.g., combining different types of data models for mixed functional purposes).
"Errors using inadequate data
are much less
than those using no data at all."
CHARLES BABBAGE
A less-explored concern is the ability of software architectures relying on relational solutions to flexibly adapt to rapid and frequent changes in the software domain and functional requirements. This challenge is exacerbated by Agile-like software development methodologies that aim at satisfying the customer in dealing with continuous emerging demands led by its business market.
In particular, RDBMS, by their very nature, may suffer when software requirements change over time, inducing rapid effects over database tabular schemas by introducing new association tables -also replacing pre-existent foreign keys- and producing new JOIN clauses in SQL queries, thus resulting in more complex and less maintainable solutions.
In our enterprise experience, we have successfully implemented and experimented with a graph-oriented DBMS solution based on the Neo4j Graph Database so as to attenuate architectural consequences of requirements changes within an operational context typical of a digital social community with different users and roles.
In this article, we:
- Exemplify how graph-oriented DBMS is more resilient to functional requirements;
- Discuss the feasibility of adopting graph-oriented DBMSs in a classic N-tier (layered) architecture, proposing some approach for overcoming main difficulties;
- Highlight advantages and disadvantages and threats to their adoption in various contexts and use cases.
The Neo4j Graph Database
The idea behind graph-oriented data models is to adopt a native approach for handling entities (i.e., nodes) and relationships behind them (i.e., edges) so as to query the knowledge base (namely, knowledge graph) by navigating relationships between entities.
The Neo4j Graph Database works on oriented property graphs where both nodes and edges own different kinds of property attributes.
We choose it as DBMS, primarily for:
- Its “native” implementation is concretely modeled through a digital graph meta-model, whose runtime instance is composed of nodes (containing the entities with their attributes of the domain) and edges (representing navigable relationships among the interconnected concepts).
In this way, relationships are traversed in O(1); - The Cypher query language, adopted as a very powerful and intuitive query system of the persisted knowledge within the graph.
Furthermore, the Neo4j Graph Database also offers Java libraries for Object Graph Mapping (OGM), which help developers in the automated process of mapping, persisting, and managing model entities, nodes, and relationships. Practically, OGM interprets, for graph-oriented DBMS, the same role that the pattern Object Relational Mapping (ORM) has for relational persistence layers.
Comparable to the ORM pattern designed for RDBMS, the OGM pattern serves to streamline the implementation of Data Access Objects (DAOs).
Its primary function is to enable semi-automated elaboration in persisting domain model entities that are properly configured and annotated within the source code.
With respect to Java Persistence API (JPA)/Hibernate, widely recognized as a leading ORM technology, Neo4j's OGM library operates in a distinctive manner:
Write Operations
- OGM propagates persistence changes across all relationships of a managed entity (analyzing the whole tree of objects relationships starting from the managed object);
- JPA performs updates table by table, starting from the managed entity and handling relationships based on cascade configurations.
Read Operations
- OGM retrieves an entire "tree of relationships" with a fixed depth by the query, starting from the specified node, acting as the "root of the tree";
- JPA allows the configuration of relationships between an EAGER and a LAZY loading approach.
Solution Benefits of an Exemplary Case Study
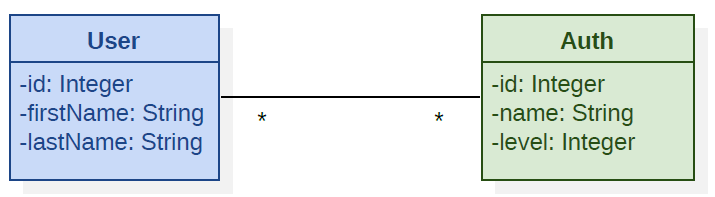
To exemplify the meaning of our analysis, we introduce a simple operative scenario: the UML Class Diagram of Fig. 1.1 depicts an entity User which has a 1-to-N relationship with the entity Auth (abbr. of Authorization), which defines permissions and grants inside the application.
This Domain Model may be supported in RDBMS by a schema like that of Tab. 1.1 and Tab. 1.2 or, in graph-oriented DBMS, as in the knowledge graph of Fig. 1.2.
| users table | ||
|---|---|---|
| id | firstName | lastName |
| ... | ... | ... |
Tab. 1.1: Table mapped within RDBMS schema for User entity.
|
AUTHS table
|
|||
|---|---|---|---|
| id | name | level | user_fk |
| ... | ... | ... | ... |

This Domain Model may be supported in RDBMS by a schema like that of Tab. 2.1 or, in graph-oriented DBMS, as in the knowledge graph of Fig. 2.2.

|
users table
|
||
|---|---|---|
| id | firstName | lastName |
| ... | ... | ... |
Tab. 2.1: Table mapped within RDBMS schema for User entity.
|
users_AUTHS table
|
|||
|---|---|---|---|
| user_fk | auth_fk | from | until |
| ... | ... | ... | ... |
Tab. 2.2: Table mapped within RDBMS schema for storing associations between User and Auth. entities.
|
AUTHS table
|
||
|---|---|---|
| id | name | level |
| ... | ... | ... |

The advantage is already clear at a schema level: indeed, the graph-oriented approach did not change the schema but only prescribes the definition of two new properties on the edge (modeling the relationship), while the RDBMS approach has created the new association table users_auths substituting the external foreign key in auths table referencing the user's table.
Proceeding further with a deeper analysis, we can try to analyze a SQL query wrt a query written in the Cypher query language syntax under the two approaches: we’d like to identify users with the first name “Paul” having an Auth named “admin” with the level greater than or equal to 3.
On the one hand, in SQL, the required queries (respectively the first one for retrieving data from Tab. 1.1 and Tab. 1.2, while the second one for Tab. 2.1, Tab. 2.2, and Tab. 2.3) are:
SELECT users.*
FROM users
INNER JOIN auths ON users.id = auths.user_fk
WHERE users.firstName = 'Paul' AND auths.name = 'admin' AND auths.level >= 3SELECT users.*
FROM users
INNER JOIN users_auths ON users.id = users_auths.user_fk
INNER JOIN auths ON auths.id = users_auths.auth_fk
WHERE users.firstName = 'Paul' AND auths.name = 'admin' AND auths.level >= 3On the other hand, in Cypher query language, the required query (for both cases) is:
MATCH (u:User)-[:HAS_AUTH]->(auth:Auth)
WHERE u.firstName = 'Paul' AND auth.name = 'admin' AND auth.level >= 3
RETURN uWhile the SQL query needs one more JOIN clause, it can be noted that, in this specific case, not only the query written in Cypher query language does not present an additional clause or a variation on the MATCH path, but it also remains identical. No changes were necessary on the "query system" of the backend!
Conclusions
Wedge Engineering contributed as the technological partner within an international Project where a collaborative social platform has been designed as a decoupled Web Application in a 3-tier architecture composed of:
- A backend module, a layered RESTful architecture, leveraging on the JakartaEE framework;
- A knowledge graph, the NoSQL provided by the Neo4j Graph Database;
- A frontend module, a single-page app based on HTML, CSS, and JavaScript, exploiting the Angular framework.
The most challenging design choice we had to face was about using a driver that exploits natively the Cypher query language or leveraging on the OGM library to simplify DAO implementations: we discovered that building an entire application with custom queries written in Cypher query language is neither feasible nor scalable at all, while OGM may be not efficient enough when dealing with large data hierarchies that involve a significant number of relationships involving referenced external entities.
We finally opted for a custom approach exploiting OGM as the reference solutions for mapping nodes and edges in an ORM-like perspective and supporting the implementation of ad hoc DAOs, therefore optimizing punctually with custom query methods that were incapable of performing well.
In conclusion, we can claim that the adopted software architecture well responded to changes in the knowledge graph schema and completely fulfilled customer needs while easing efforts made by the Wedge Engineering developers team.
Nevertheless, some threats have to be considered before adopting this architecture:
- SQL is far more common expertise than Cypher query language → so it’s much easier to find -and thus to include within a development team- experts able to maintain code for RDBMS rather than for theNeo4j Graph Database;
- Neo4j system requirements for on-premise production are relevant (i.e., for server-based environments, at least 8 GB are recommended) → this solution may not be the best fit for limited resources scenarios and for low-cost implementations;
- At the best of our efforts, we didn’t find any open source editor “ready and easy to use” for navigating through the Neo4j Graph Database data structure (the official data browser of Neo4j does not allow data modifications through the GUI without custom MERGE/CREATE query) as there are many for RDBMS → this may be intrinsically caused by the characteristic data model which hardens the realization of tabular views of data.
Opinions expressed by DZone contributors are their own.
Comments