The following represents essential components of a database within the mobile app technology stack:
- Local data storage capabilities
- Flexible data models
- Data synchronization
- Security
- Platform support
- Flexible deployment
Local Data Storage
All mobile apps require some form of data processing and persistence to maintain state and ensure a consistent user experience, but where the data is stored and processed can have a huge impact on speed and availability. Mobile apps that rely solely on a back-end database server in the cloud are subject to network disruption and latency. If the internet connection slows or the cloud data center goes down, so do the apps that rely on them, as illustrated in Figures 1 through 3.
The cloud layer at the top host apps and services powered by a back-end cloud database that is accessed from mobile devices at the edge over the internet. Mobile apps that only use a database in the cloud depend on the internet. When connectivity is available, apps work as intended:
Figure 1
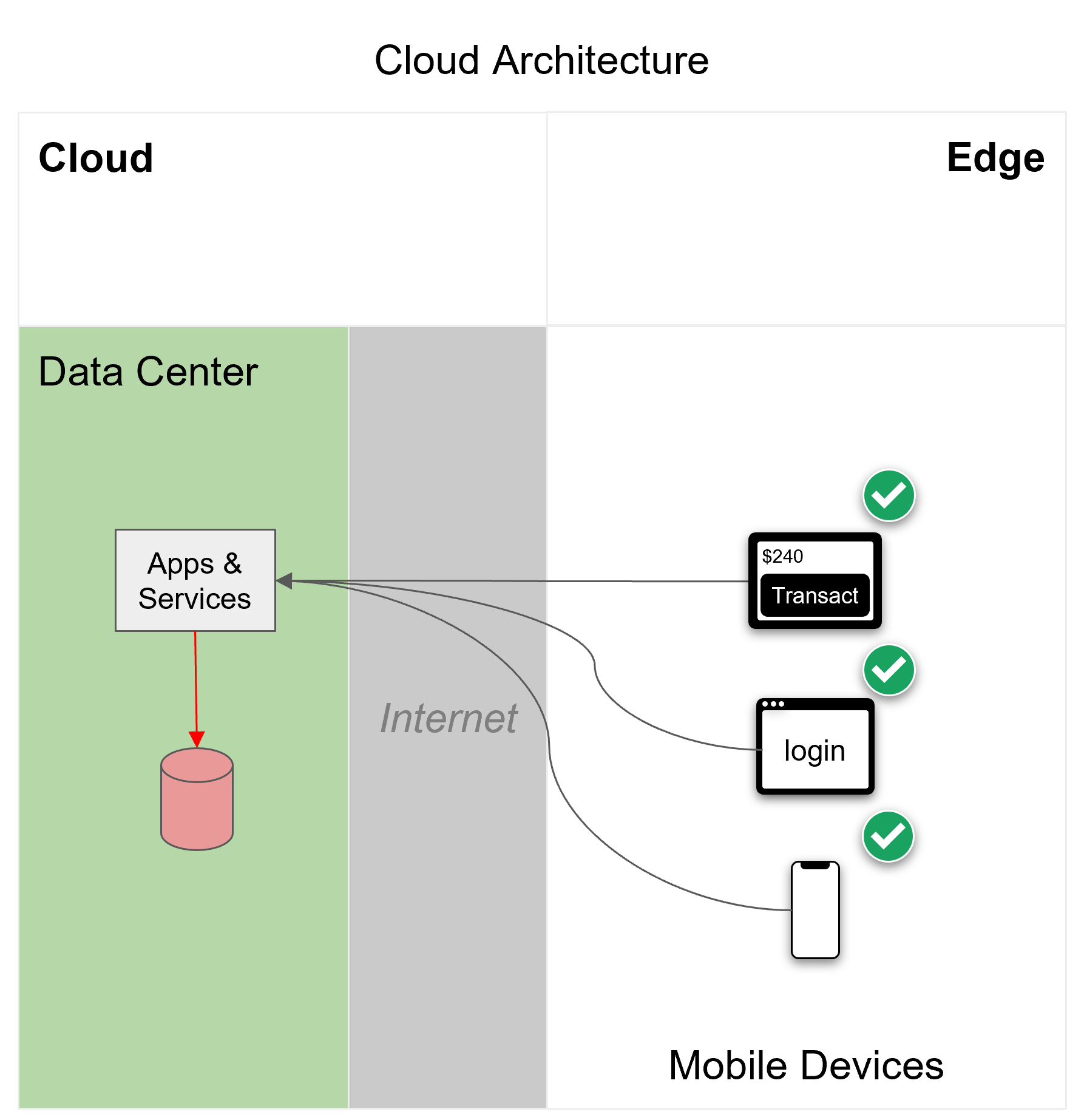
If the internet slows down, so do the apps that rely on it…
Figure 2
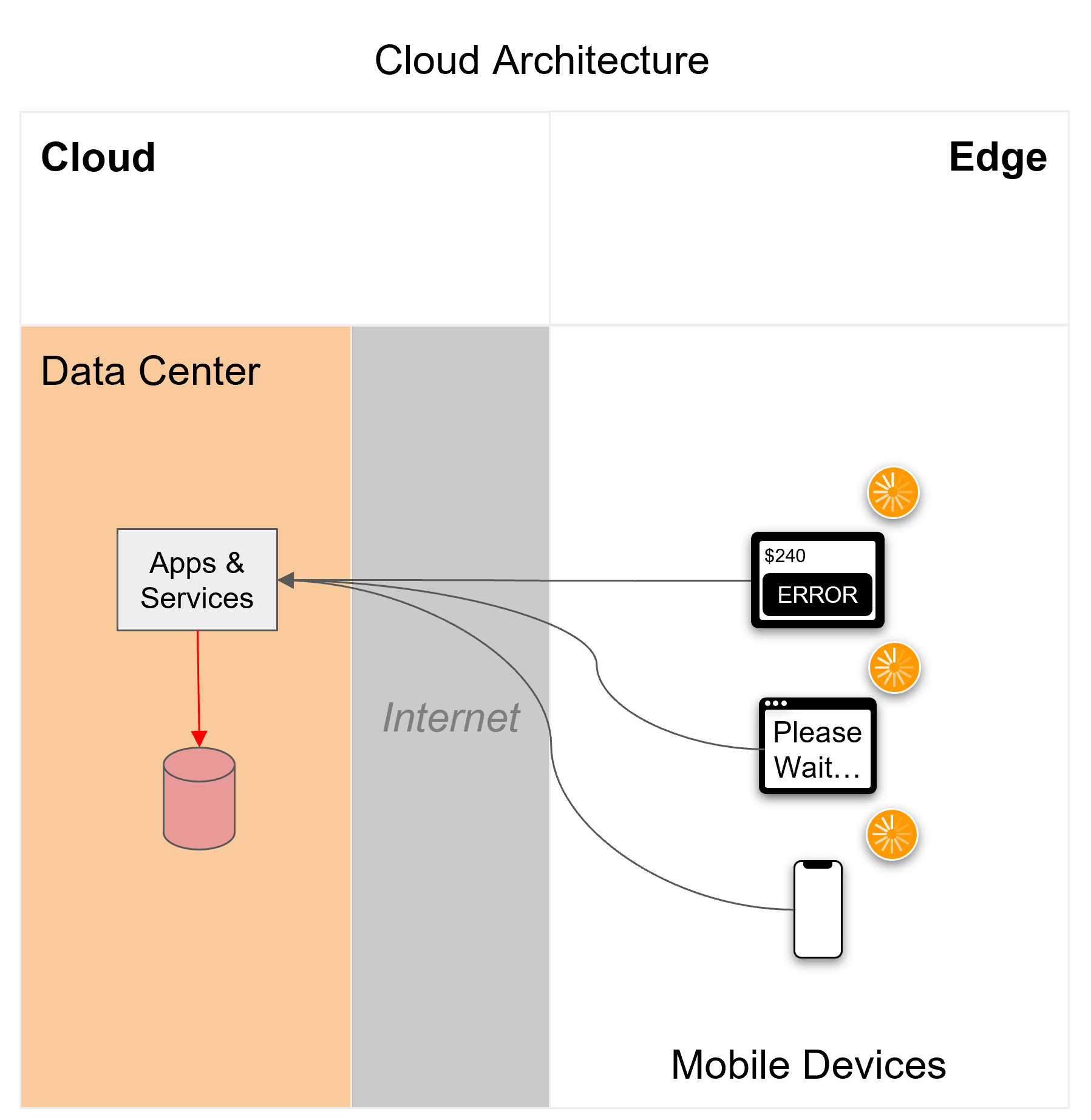
If internet connectivity is disrupted, or the cloud data center goes down, apps that rely on them can’t operate:
Figure 3
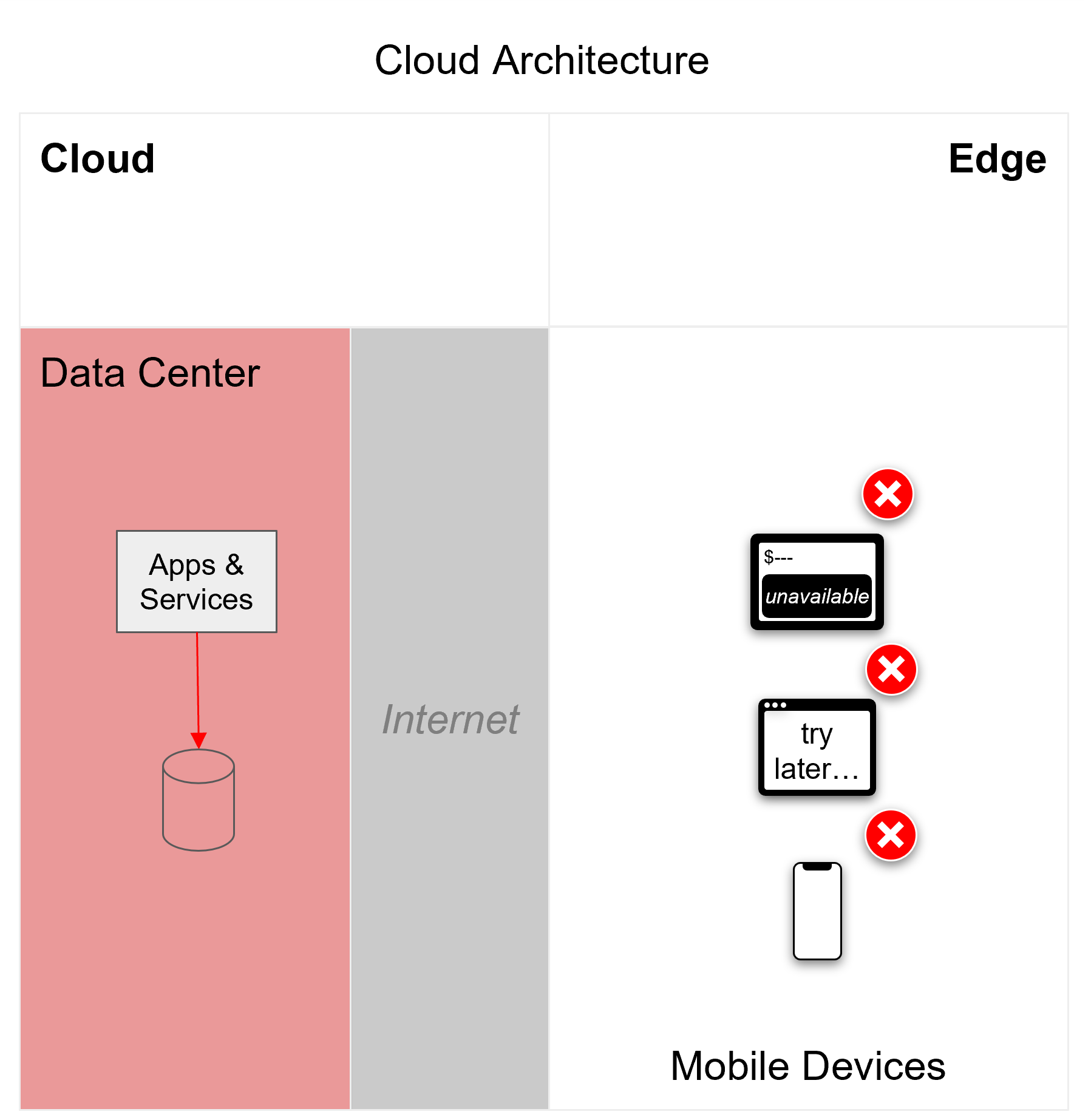
To reduce dependencies on the internet and cloud data centers, mobile app developers should consider storing and processing data locally on the mobile device in addition to a central cloud back-end database. Database providers offer different approaches to enabling and handling data persistence on a mobile device. The method you choose should depend on how your application will be used.
Temporary Offline Data Cache
If your mobile app is intended for use where network connectivity is fairly reliable, such as within a major metropolitan area, you may need to account for users going through tunnels, onto elevators, into subways, or other areas where connectivity can be temporarily interrupted. For handling these disruptions, some cloud databases offer local data caching to maintain app availability when a network is not available.
This approach is useful for occasional lapses in connectivity but can introduce inefficiencies if the app is offline for too long. This is because writes are collected and held in queue until they can be committed to the back-end cloud database, and as the queue grows, it can begin to impact app performance. Additionally, local data caches typically have a limitation on the amount of data allowed to collect, and if the limit is exceeded, the risk of data loss increases. As such, a local data caching strategy should only be considered for apps that will run in areas with reliable network connectivity.
Embedded Database
Some applications need the ability to operate without network connectivity for extended periods of time, such as when at sea, in mines, on airliners, or in remote wilderness. For these types of apps, a local database running on the mobile device can allow an app to operate "offline-first" in complete isolation without requiring a central cloud control point.
Unlike a temporary cache, a local embedded database brings far better resilience, more stringent security, and more efficient processing because it's designed for high velocity and long-term secure data storage. When evaluating embedded databases, look for:
- Support for on-device backups to provide failover and minimize risk of data loss
- The ability to deploy pre-built databases for faster app startup
- Asynchronous database change notifications to enable reactive workflows
- An intuitive, easy-to-use SDK for your preferred programing languages and platforms
- Built-in data synchronization between devices and the back-end cloud database to ensure data consistency
Sync considerations are covered in more detail in the "Synchronization and conflict resolution" section of this Refcard.
Query Capabilities
Regardless of which local storage method is used, how you query the data is an important consideration. To ensure easy development and fast time to market, look for an intuitive query API and SQL support over learning a new query language or paradigm. The query API should support complex SQL queries with joins, aggregations, and transactions in order to power enterprise-class commercial applications, and it should execute queries as fast as possible to ensure a reliable user experience.
Search
All applications need search; it is an expected feature that should not be added as an afterthought, and it requires a database that can index natural language text fields and provide search results based on free form user input.
There are dedicated search engines designed to provide full text search for applications, but you will have to integrate this third-party technology with your mobile database, adding complexity to your technology stack. When evaluating mobile databases, look for built-in full text search features, which will reduce the complexity of your stack and save you development time.
Asynchronous Events
If your apps are reactive in nature, you should not have to poll the underlying database for data changes that affect the app experience — you want your app to be notified of those data change events proactively. Look for a database that provides asynchronous event notifications at the database as well as individual field or document level, including replication events where sync is used.
Additionally, for objects in your app that rely on the results of a query for UI display, your database should support the ability to attach an observer to the query, so your app will be notified any time the underlying result of the query set is affected by changes to the database.
Flexible Data Models
Data model flexibility will dictate whether you can articulate the model requirements for your apps in an efficient and appropriate way. Today’s mobile apps evolve at a very fast pace, and the flexibility of your model will play a huge role in how easy, or difficult, it is to quickly adapt as your requirements evolve over time.
A new release of a mobile app with an updated data schema can require expensive database schema migrations to be performed on app launch, adding to app start-up costs and degrading the user experience. Further, as a mobile developer, you don’t have control over when a new version of your app gets adopted. As a result, users might be migrating from a very old version of the schema to the latest version, exacerbating potential data migration issues.
These are important points to consider when evaluating a mobile database for data model flexibility. The predominant models are relational and NoSQL.
Relational Data Model
Relational databases natively support SQL and excel at storing highly structured data and providing strong consistency. But these characteristics bring rigidity because the data model is fixed and defined by a static schema. So in order to change the data model, developers have to modify the schema, slowing down development.
For example, adding a new user profile attribute to a relational database requires schema changes that can affect the entire relational model — in essence, you have to update the whole database to ensure consistency is maintained.
The explicit RDBMS schema prevents the addition of new attributes on demand:
Figure 4
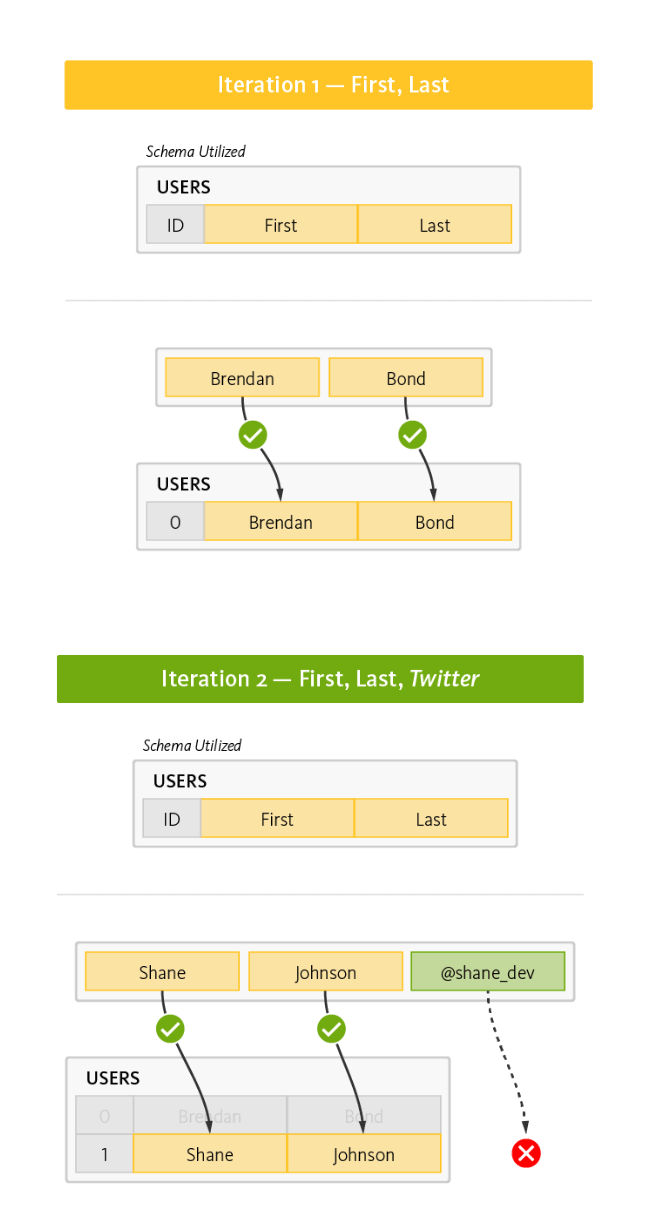
An updated schema also means the entire database must then be pushed to apps running on mobile devices, adding to start-up costs and degrading the user experience.
Adopting a relational database can offer a familiar environment for development and strong consistency, and is good for applications with highly relational data, but keep in mind the tradeoffs and impact on future iterations of your application due to relational schema rigidity.
NoSQL JSON Document Data Model
NoSQL databases are schemaless and document-oriented, storing data as JSON documents instead of tables of rows and columns. Beneficially, JSON is also the de facto standard for consuming and producing data for web, mobile, and IoT applications, making the JSON document data model ideal for nimble development without relational rigidity.
The JSON model simplifies application development because objects are read and written as a single document rather than across multiple tables in a relational model. As such, NoSQL defers to the applications and services — and thus to the developers — as to how data should be modeled. With NoSQL, the data model is defined by the application model. Applications and services model data as objects.
Taking the same user profile object example used in the relational model, adding a new attribute to a user document is easy; it's just a new nested key-value and requires no reworking of any schema.
The JSON document data model evolves as new attributes are added on demand:
Figure 5
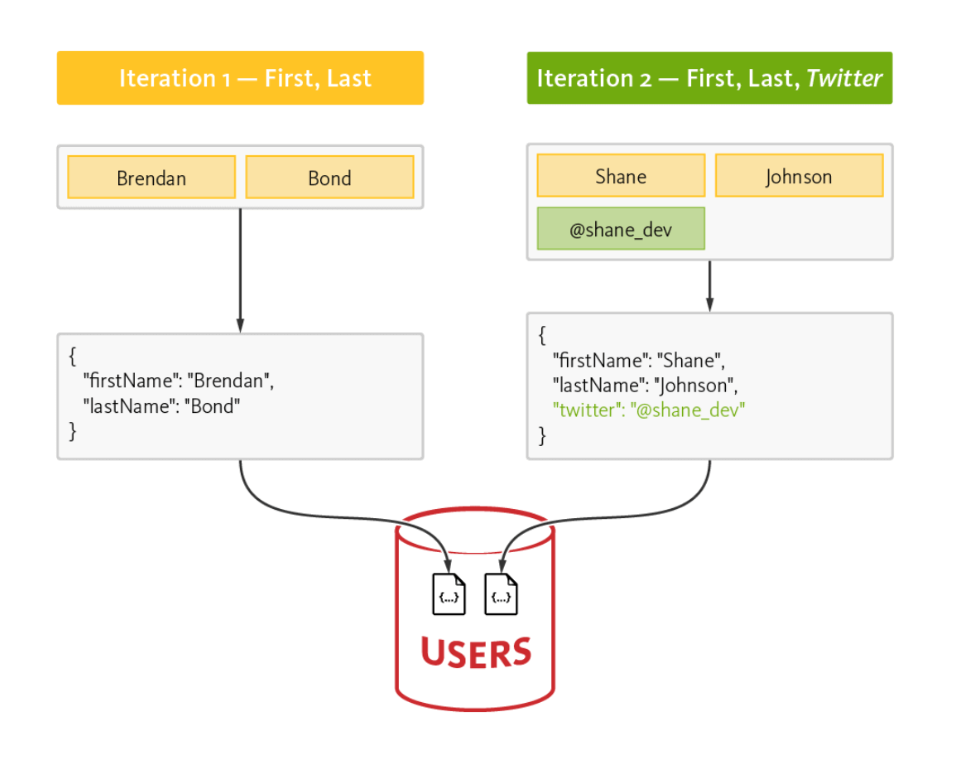
By removing the need for time-consuming schema updates to support new app features, a JSON document data model helps accelerate development and makes app updates much easier than with a relational data model — both for users and developers.
If your app development follows the domain model, and you want the flexibility to evolve apps without the overhead of relational rigidity, a NoSQL JSON document database is a great mobile database option to consider.
Data Synchronization
To build resilient mobile apps, you need comprehensive data synchronization for integrity, accuracy, security, and a positive user experience. But you can't rely on users to sync data proactively; you need to ensure that it is automatic. Additionally, a properly applied data sync functionality can make app updates easier and more foolproof — even if an update installation goes bad for some reason, the next data sync will correct any inconsistencies.
Synchronizing data for mobile apps is inherently complex and gets increasingly more so as the number of clients increases. Sync is more than just replicating data; it’s making sure that it's done securely, accurately, and instantly every time. To do sync right, you must:
- Contend with sync conflicts and how to resolve them
- Ensure secure access so no one sees the wrong data
- Make sure sync goes both directions
- Monitor network status and handle connectivity disruptions
- Sync only data that has changed rather than syncing everything
- Provide filters and data partitioning to route data sync with precision
Without these critical sync capabilities, apps risk using and displaying old or incorrect data, or worse, losing data altogether. When choosing a mobile database, make sure you understand its sync capabilities. Taking full measure of the above noted criteria will help you build secure, flexible, and manageable mobile apps that always work — with or without an internet connection.
Data Sync Management
Regardless of how you implement synchronization, it is important to have the ability to control how the system syncs, which includes handling replication events, conditional replication, and replication filtering. Be sure you have support for streaming, polling, one time, continuous, and push.
The granularity of sync has a direct impact on network bandwidth usage, so having a solution that is smart about identifying what subset of data has changed and only syncing the deltas is an important consideration in mobile deployments where data plans come at a premium and network bandwidth is limited.
You should also have the ability to use a combination of these strategies. For replication events, you should be able to know the overall replication status as well as the replication status of individual fields or documents. In some cases, you may need conditional replication to replicate data only under specific conditions, such as when the mobile device is connected to Wi-Fi or when it has sufficient battery power.
For replication filtering, look for the ability to selectively replicate some data but not other data. Filtering should be fine-grained and based on the content of the data itself. For example, to lower latency and reduce bandwidth and egress costs for apps used in a multi-location retail chain, you could sync from the cloud only the data needed for each individual store by filtering on storeID.
Partition Tolerance
Configurable sync topology support is needed to allow you to meet your partition requirements. Your database and sync solution should allow you to configure the system to allow certain parts to operate offline.
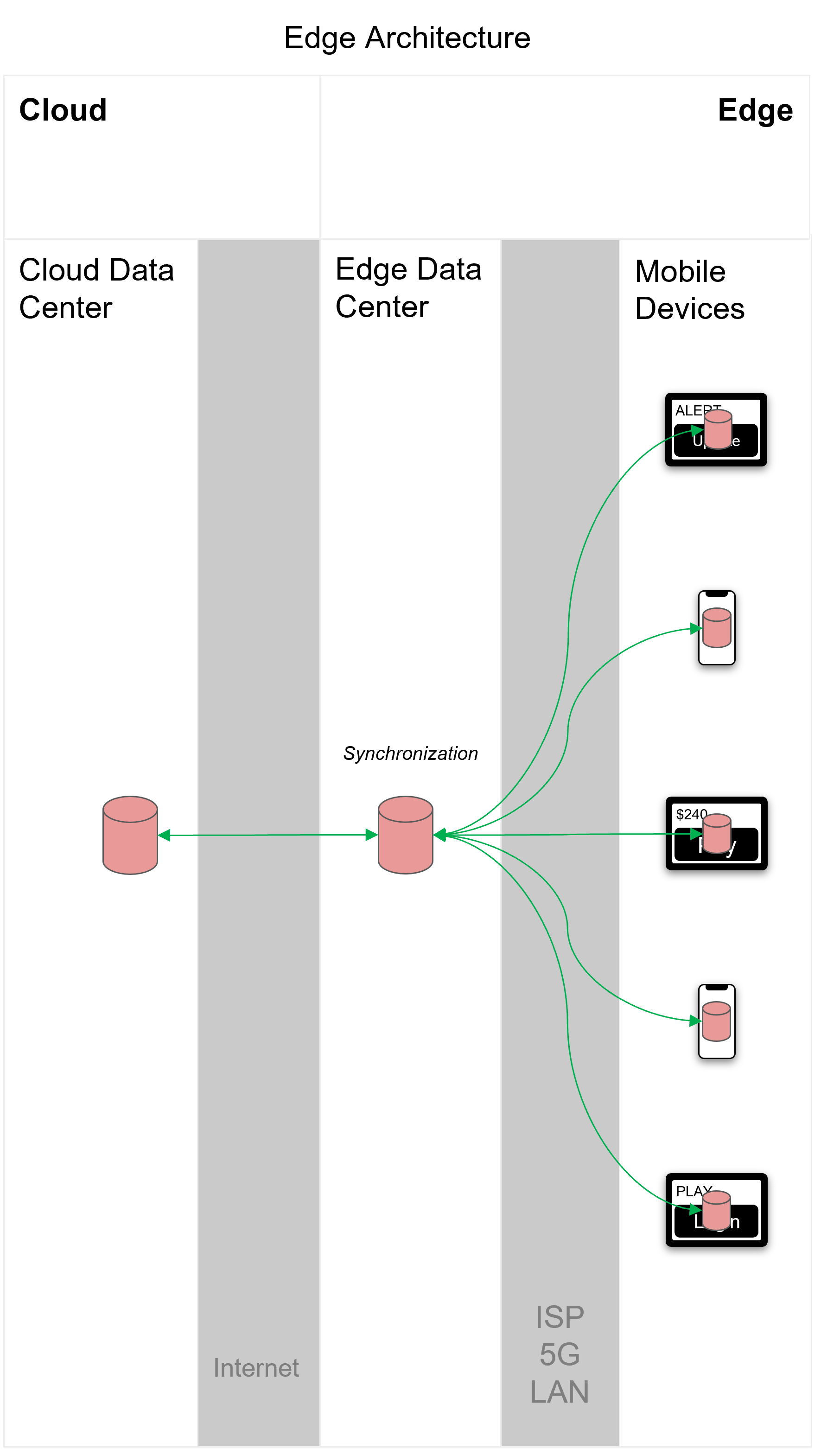
The ability to sync across more complex distributed edge architectures can allow different parts of the system (in addition to the devices) to operate while completely offline. For example, in Figure 6, we show an edge architecture, where we introduce an edge data center between the cloud data center and mobile devices. The edge data center is typically on-premises or located in a local proximity data center. By syncing data between the layers of the architecture, you can achieve partition tolerance where downstream layers can operate in complete isolation from the upstream layers if connectivity is lost.
Edge architectures require the ability to sync data between the cloud, edge, and mobile devices:
Figure 6
You may also want support for cloudless topologies that allow devices to communicate peer to peer and directly sync data among themselves. Peer-to-peer synchronization is a powerful addition or alternative to client/server synchronization. It allows apps to connect and exchange data directly over personal area networks without going through a central server in the cloud. As a result, apps can continue to work and share data regardless of internet availability.
In Figure 7, we complete the simple edge architecture by adding peer-to-peer sync between local devices using a personal area network (PAN) such as Bluetooth. This allows devices in near proximity of one another to continue to operate and sync even in the event of internet or data center failure.
Syncing between peer devices as well as between the edge and the cloud is how to achieve complete partition tolerance for applications:
Figure 7
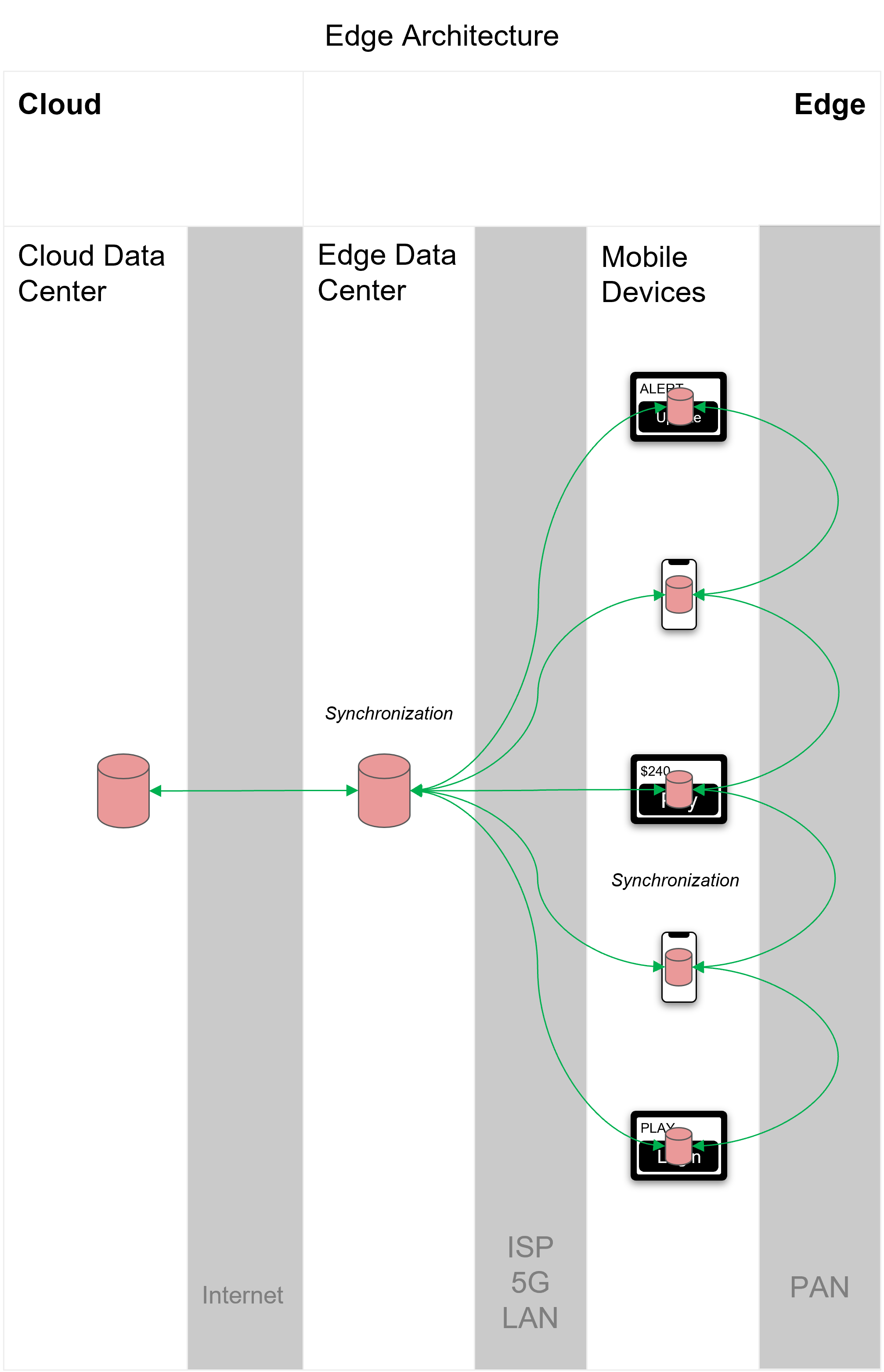
A retail point-of-sale (POS) system is a good example of a distributed edge topology. POS systems require that a brick-and-mortar store continue to operate if it becomes disconnected from the rest of the system. With an edge architecture, POS devices would sync with a store-level database, which would then sync with a global system. As such, stores can continue to operate and sync data with their POS devices — regardless of connectivity to the global system.
Data Sync Conflict Resolution
For mobile platforms that utilize decentralized data writes, the same data can be simultaneously modified on multiple devices, creating a conflict. The system needs to support a mechanism for resolving those conflicts. Conflict handling will differ for each system. You should look for a data sync solution that uses revision trees and a default resolution rule of "most active branch wins." This way, conflicts are resolved logically based on activity instead of using a system clock-based conflict resolution strategy that takes a "most-recent-change-wins" approach. Clock-based resolution systems are problematic due to the issues around clock differences across devices.
Your sync solution should also allow you to create custom conflict resolution policies in order to provide more flexibility for specific use cases.
Finally, conflict resolution needs to be lightning fast, so look for capabilities to resolve conflicts at the device layer. Resolving conflicts in aggregate in the cloud can bring huge compute costs and increases the risk of latency or data loss due to internet dependencies.
Security
When you’re using synchronized and decentralized storage, it’s important to access, transmit, and store data securely, as well as ensure only the data that is needed is sent to the device. To cover this completely, you need to address authentication, data at rest, data in motion, and read/write access control. Here's what to look for in a mobile database to ensure end-to-end data security and governance for your apps.
User Authentication
Ensure your mobile database supports open, standards-based, pluggable authentication like OAuth2 and OpenID Connect (OIDC) providers. For flexibility, look for support for integrating your own custom provider.
Data Read/Write Access
Make sure your mobile database offers fine-grained policy tools that allow controlling data access for individual users and roles. The ability to provide data partitioning (for example, isolating access to data by region or store) is important for assigning or revoking access permissions in aggregate. Also ensure that authorization is granular and goes beyond database-level permissions; look for fine-grained permissions at the document and field level.
Data Transport on the Wire
For data in motion, ensure that your mobile sync supports encryption using SSL or TLS.
Data Storage on Device
For data at rest on a device, use the device’s built-in File System Encryption and 256-bit AES full database encryption. While platforms like iOS and Android do provide encryption, don’t assume that the on-device data persistence layer will be encrypted by default. Develop with an assumption that there is no default encryption enabled.
Data Storage in the Cloud
For data at rest in back-end cloud databases, you should leverage File System Encryption to encrypt the entire database, or look for a database that can leverage the native encryption solution offered by the cloud provider, such as Encrypted EBS Volumes in AWS. Also make sure your database supports role-based access control (RBAC).
Data Governance
As a best practice, make sure your mobile database features align with your overall data retention policies. To reduce the risk of unauthorized data access, you need the ability to add or remove permissions instantly throughout the distributed architecture — not just on the back-end database but also for any devices where the data can also live. Look for a mobile database that can support auto purging of local data on access revocation, guaranteeing that only authorized users retain access to the data.
Platform Support
It’s important to evaluate mobile database options based on the platforms you plan to support — not only today but also into the future. For example, in addition to mobile devices, determine if you will ever need to support Windows and Mac desktops and laptops, or embedded IoT devices as well.
When approaching mobile development, you must decide if you will build it as native, that is, built specifically for a particular operating system leveraging platform-specific programming languages, or if you will build it using cross-platform tools, which creates a single codebase designed to work on multiple platforms.
The predominant skills and expertise across your development team should be a key factor in choosing your approach — go with what your team knows. Also be sure to consider your UI/UX, examine all planned cards and determine how the app needs to look and behave on different devices and form factors, such as on a smartphone vs. a tablet. Understanding these details will help you make an informed decision on how to approach your mobile app development and choose the most appropriate database.
Native Platform
Developing mobile apps on native platforms like Swift, Kotlin, or Java can bring specific advantages, especially for the user experience. Apps built on these platforms will appear and behave seamlessly on the device and provide a more intuitive experience for users. Native apps can also take better advantage of inherent device capabilities like GPS, the camera, or phone, making it easier to add these types of features to your app. And native apps can arguably perform better because of direct access to device resources, allowing them to consume less CPU and memory than the comparable apps built with a cross-platform tool.
Keep in mind that developing on native platforms means you have to build a separate codebase for each platform, but don’t assume this makes it a less ideal approach for your project. Of course, the database you choose should offer an SDK for the native platforms you decide to develop on, as well as extensive docs and tutorials to accelerate development.
Cross-Platform
Cross-platform tools like Flutter, .NET (Xamarin/Maui), React Native, and Ionic are frameworks for developing apps that work on multiple platforms. Using cross-platform tools can save time by removing the need to develop a unique codebase for each platform, and it makes code maintenance easier as there's only one codebase to maintain.
But there are tradeoffs for this efficiency depending on your app’s required features and integrations. For example, when developing complex interfaces using cross-platform tools, you must carefully consider the differences among operating systems and hardware and address any variance in how specific features will be handled on each platform because they can impact how a given functionality will work from device to device. For example, navigation bars and widgets look and behave differently on iOS vs. Android; developers must weigh these sorts of differences and understand how they will affect the user experience when using cross-platform tools.
Correspondingly, the mobile database you choose for your stack should offer an SDK for the cross-platform tool you decide to develop on, as well as extensive docs and tutorials to help with development.
Flexible Deployment
How and where you deploy the database for mobile applications is a very important decision and one that should not be constrained by requirements to use a particular hosting provider or platform. To meet specific requirements for app availability and speed, you need the ability to host your back-end database on any public or private cloud and on-premises in your own data center, as well as the ability to leverage containerization strategies to manage deployments as needs change or grow.
Cloud to Edge Deployment
When evaluating mobile databases, look for those that are cloud service provider agnostic and that will allow you to deploy wherever you need to meet your goals. This will help avoid vendor lock-in, make future migrations easier, and will help support more topologies and mobile use cases. In addition, look for a mobile database that can support a layered hierarchical architecture, allowing you to distribute data processing across an edge ecosystem — from the cloud to the edge to the device — in order to support low-latency and availability requirements.
Finally, look for a database with deployment options including managed back-end services for data storage and sync (meaning you don’t have to manage servers), as well as the ability to host and manage the database and sync functionality yourself. This flexibility will allow you to support any edge architecture.
The deployment topology depicted in Figure 8 below is similar to Figure 7, except in this case, we introduce on-premises data centers as an additional layer between the provider edge and the mobile clients, and we distribute the data storage and processing across multiple cloud regions. Red cylinder icons represent a database, and green lines indicate data synchronization.
Figure 8 depicts a distributed edge architecture with the mobile database deployed across all tiers. Regional cloud data centers sync data between cloud provider edge data centers, on-prem data centers, and embedded on-device databases.
Figure 8
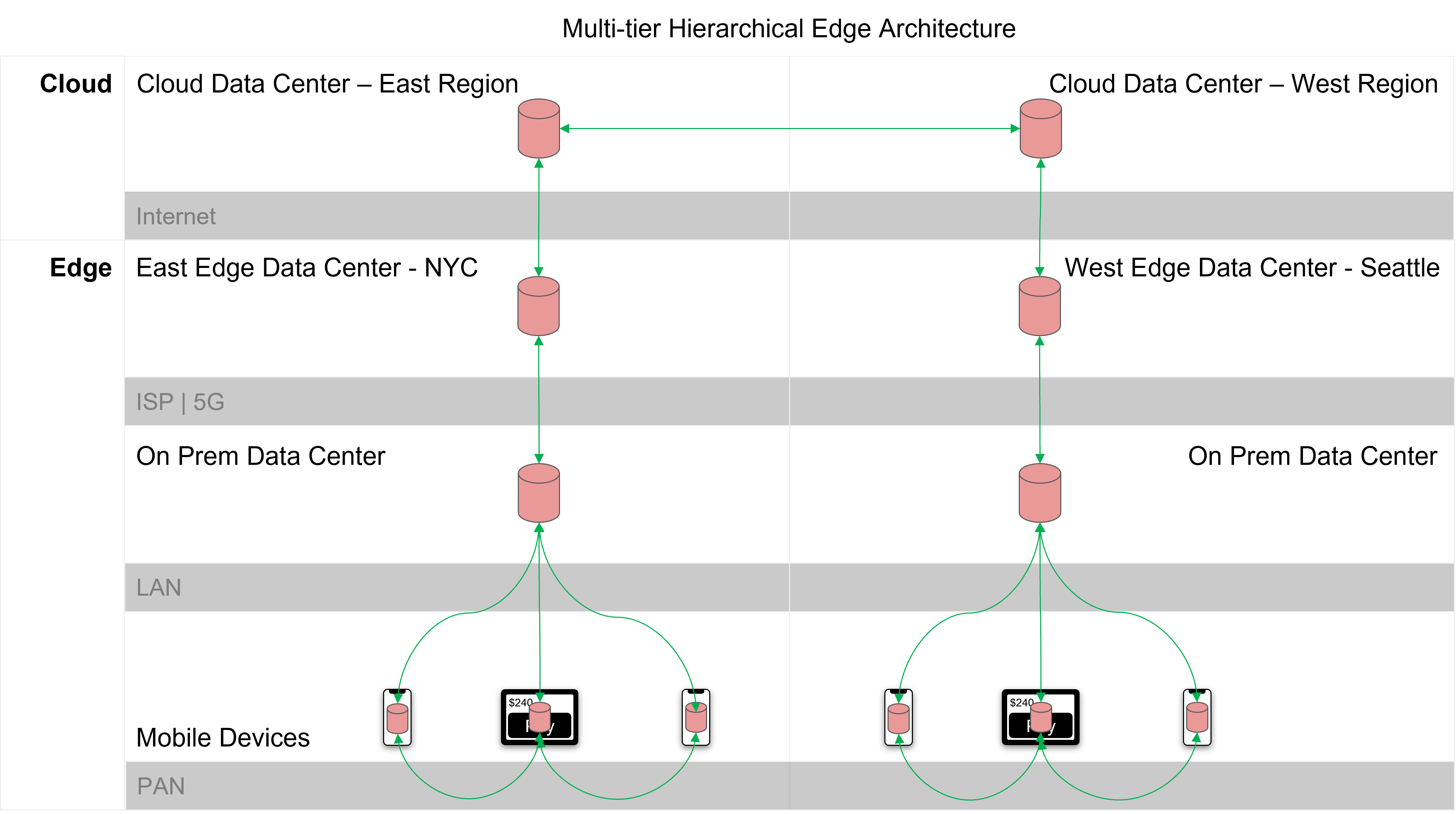
Figure 8 depicts an architectural topology intended to create partitioned edge ecosystems that are impervious to network problems, and that can operate completely disconnected from the cloud. Should any upstream layer suffer an outage, mobile apps using downstream edge data processing remain responsive and unaffected. And by bringing data processing closer to the mobile app clients at the edge, this topology eliminates internet latency issues and provides superior speed for latency sensitive apps.
If your apps require high guarantees of availability and low latency, look for a database that supports the ability to deploy and sync data across a distributed edge architecture.

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}