Sponsored Content
AIOps to Agentic AIOps: Building Trustworthy Symbiotic Workflows With Human-in-the-Loop LLMs
AIOps to Agentic AIOps: Building Trustworthy Symbiotic Workflows With Human-in-the-Loop LLMs
Build secure, human-in-the-loop AIOps workflows using agentic AI for smart alert triage, context summarization, and automated, safe incident resolution.
This article was provided by and does not represent the editorial content of DZone.
Join the DZone community and get the full member experience.
Join For FreeEditor’s Note: The following is an article written for and published in DZone’s 2025 Trend Report, Intelligent Observability: Building a Foundation for Reliability at Scale.
Imagine a world where the 3:00 AM PagerDuty alert doesn’t lead to a frantic scramble, but rather to a concise summary of the problem, a vetted solution, and a one-click button to approve the fix. This transformative capability represents the next frontier of AIOps (artificial intelligence for IT operations), powered by agentic AI systems that are designed to perceive, reason, act, and learn. This shift promises a significant reduction in mean time to resolution (MTTR) but critically relies on human-in-the-loop (HITL) safeguards to ensure accountability and prevent issues like AI hallucinations.
This tutorial will serve as a practical, step-by-step guide for engineers and tech ops teams and leaders. We will attempt to illustrate and sketch out the details of how to construct a scalable, secure, resilient workflow using large language model (LLM) agents for smart alert triage, context summarization, and most importantly, gated runbook execution. Such an agentic mechanism should eventually be the pioneering framework for the upcoming self-healing systems.
Prerequisites of Agentic AIOps
Before beginning the construction of the first line of code, we need to define the theoretical base, factors, and conditions for agentic AIOps to be an option.
Defining Agentic AIOps
Agentic AIOps fundamentally overhauls the relationship between AI and digital operations. It goes beyond models, which are just classifiable or predictive ones. The cornerstone of this evolution is a software entity that possesses four key attributes, allowing it to move beyond passive observation:
- Perception – the ability to ingest and understand data from the environment (e.g., observability data)
- Reasoning – the use of an LLM and structured data (tools) to formulate a goal and plan
- Action – the capacity to execute the plan through external tools (e.g., calling an API, running a script)
- Learning – the ability to refine its performance based on feedback from its actions and human input
For this model, rather than simply reacting to an alert, the agent is taking proactive ownership of a defined task (e.g., diagnosing a microservice failure and suggesting a well-tested, workable fix).
Understanding the Human-in-the-Loop Approach
HITL is the critical safety lock on AI autonomy. For AIOps, it creates a division of duties that is distinct:
- Agents handle routine – High-volume, low-risk, and repetitive tasks — like classifying alerts, fetching diagnostic context, and correlating related events — are fully automated.
- Humans authorize risk – Actions taken to alter the operating environment of a production system — like creating new configurations, restarting work, rolling back a deployment, or changing a configuration — must be processed through an HR gate that is entirely human controlled.
This architecture assures responsibility and allows the agent to correct or pause its action if its reasoning is wrong (a hallucination) or if the proposed action violates a critical business constraint. It transforms the SRE from “firefighter” to “trusted approver” and “AI model trainer.”
The Observability Trifecta
LLM agents are only as good as the situation they find themselves in. In order to engage in sophisticated reasoning, the system should reach into an observability trifecta: logs, traces, and metrics. This suite of data makes up the context trifecta, which, when synthesized by an LLM, can mirror a full incident bridge meeting — in brief paragraphs — for a human team or an advanced agent.
Technical Stack Overview
Implementation of agentic AIOps involves integration of multiple component parts that have to be combined to realize the success. The general high-level stack like this one generally contains the components found in Table 1:
|
Component Category |
Example Technologies/Concepts |
Purpose in Agentic AIOps |
|---|---|---|
|
Foundation LLM |
Enterprise-governed models (e.g., any cloud hosted) |
The “brain” for reasoning, summarization, and action planning |
|
Agent framework |
LangGraph, LangChain, etc. |
Provides the state machine and abstraction layer for defining agent personas and orchestrating their collaboration |
|
Observability/data |
OpenTelemetry, Prometheus, vector database |
Ingestion and storage of the logs, traces, and metrics needed for LLM context retrieval |
|
Security and gating |
Role-based access control (RBAC), Open Policy Agent (OPA) |
Enforcing security policies, defining human approval rights, and implementing Policy as Code for automated action checks |
|
Execution/automation |
Ansible, Terraform, Kubernetes APIs such as CI/CD tools |
The interface for agents to execute approved, low-risk, or gated actions |
|
HITL interface |
Slack/Teams APIs, PagerDuty/Jira integration |
The human-facing communication and approval channel for all high-risk actions |
Table 1. AgenticOps technical stack
System Architecture and Innovations
The architecture of an agentic AIOps system must be engineered for both speed and safety. It’s a structured pipeline designed to manage the flow of data, intelligence, and execution with multiple funnel points for human and policy oversight.
High-Level Design
Figure 1 describes this intricate apparatus consisting of five key modules: the ingestion layer, agentic core, HITL gatekeeper, execution later, and feedback loop.
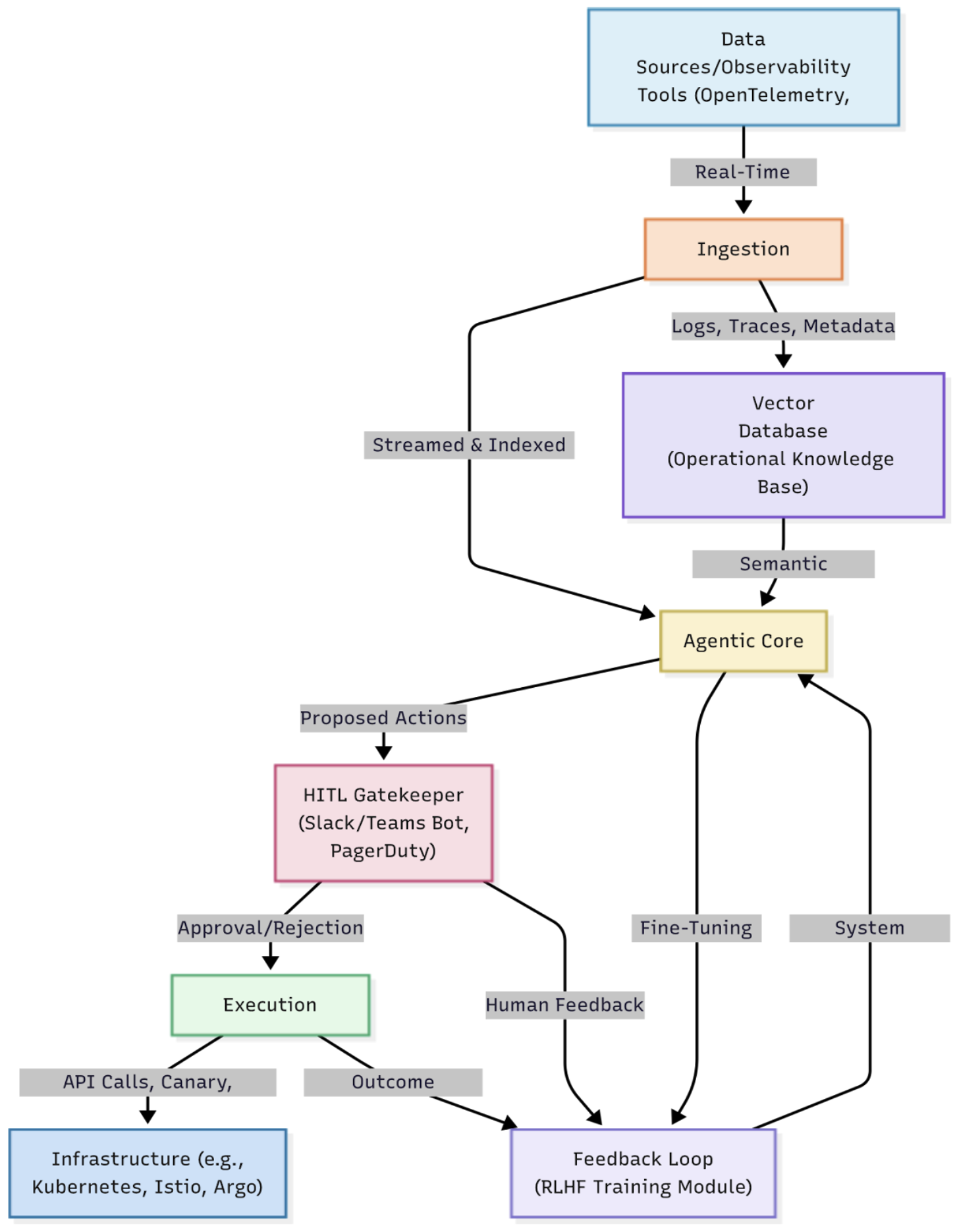
Ingestion Layer
This is the front door for all the operational data. To support this layer, we use real-time data from existing observability tools — whether they conform to the OpenTelemetry specification or utilize proprietary agents — to stream. The most important innovation here is getting ready for the LLM. The logs, traces, and metadata are indexed and translated to embeddings, which are stored in a vector database (the operational “knowledge base”) to perform rapid semantic retrieval.
Agentic Core
This is the primary intelligence engine. A multi-agent unit run by a Supervisor Agent:
- Triage Agent is the first responder, which classifies the incoming alert (e.g., seriousness, service owner) and correlates it with either recent deployment events or related past incidents.
- Summarizer Agent uses retrieval-augmented generation (RAG) to query the vector database and pull relevant logs, traces, and metrics and synthesize a coherent, plain-language incident summary.
- Runbook Proposer Agent either takes the summary of the context and maps it to a set of preapproved, executable runbooks or generates a new runbook or a new action script by looking at the previous ones (e.g., based on historical resolving scenarios).
HITL Gatekeeper
This is the critical safety barrier. The proposed action (e.g., Restart the Payment Service) is translated into a crisp approval card and sent through a standalone Slack/Teams bot to the on-call SRE. Additionally, the system should interface with an escalation system like PagerDuty so that the correct person will be notified within the SLO. This gate completely limits the agent execution privileges.
Execution Layer
The action is run after human approval. This layer was created for defensive deployment techniques:
- Gated executor is the component that runs the actual action (e.g., if I’m calling my Kubernetes cluster by API).
- Canary/rollback, used for essential changes, wraps the action in defensive mechanisms (e.g., Istio traffic splitting, any other rolling rollout strategy) to test the change on a small slice of users, the canary. It is preconfigured to roll back in real time when health checks go south.
Feedback Loop
The system is intended to learn from every interaction. The output of the human as approval or rejection, success or failure of execution, and the final MTTR are all fed back into a training module. This employs a version of Reinforcement Learning from Human Feedback (RLHF) to refine the agents’ reasoning and runbook proposal strategies periodically.
Multi-Agent Collaboration
The architecture uses a collaborative “team” rather than a single monolithic agent. While the Supervisor Agent is responsible for the flow, the specialized agents are designed to “debate” or cross-validate their conclusions. For example, the Triage Agent classifies the alert. The Summarizer Agent might challenge that classification if the underlying logs suggest another primary service is failing. This internal, automatic peer review process greatly increases the accuracy of our recommendation; it eliminates any single point of failure in the reasoning chain.
Hybrid RAG and GraphRAG
Conventional RAG only fetches chunks of text based on its semantic similarity. But this is inadequate for AIOps. A service failure is about logs and dependencies. This problem was resolved by GraphRAG, which layers a knowledge graph over the data. The underlying data in GraphRAG covers all the dependencies of services — for example, “The Checkout Service relies on the Inventory Service and Payment Gateway.”
The agent first queries the graph during an alert to comprehend the impact and upstream/downstream dependencies. Then, that RAG query looks only for the logs and traces on the affected services detected by the graph. Since the agent is reasoning over structure and text in parallel, this combination results in far faster and more accurate root cause analysis.
Zero-Trust Gating
A zero-trust principle needs to guide the execution layer; no action, even if it is authorized by a human, is inherently safe, unless its intent and context are validated against policy. This is made possible via Policy as Code, using such tools as Open Policy Agent (OPA).
Dynamic checks of the proposed action payload:
- Scope check – Is the behavior only within the service specified in the alert? (e.g., was the agent attempting to restart the entire cluster for one pod failure?)
- RBAC check – Does the approving human in fact have the appropriate security role via the HITL Gatekeeper to authorize this?
- Context check – Is the present time window (e.g., peak sales hour) relevant to prohibit this high-risk action?
The execution environment is then not released until these automated, dynamic policy checks are completed.
Step-by-Step Implementation Guide
This section provides a conceptual walk-through of building the agentic workflow using common open-source principles and tools.
Step 1: Set Up the Dev Environment
Begin by establishing the foundation:
- Dependencies – Install the necessary LLM libraries, the agent framework (e.g., LangGraph), and client libraries for observability data access.
- Observability config – Configure a basic microservice application to emit logs, traces, and metrics via OpenTelemetry. This is the standard abstraction layer that future-proofs the system against vendor lock-in.
- Sample alert generation – Create a simple trigger mechanism (e.g., a script that injects an alert into a Kafka queue or an alert manager) to simulate an incident flow.
Step 2: Build the Data Ingestion Pipeline
The goal is to prepare the operational data for semantic search:
- Stream data – Use an OpenTelemetry Collector or similar tool to funnel the raw logs, traces, and metrics.
- Vectorization – For unstructured data (logs), use an embedding model to convert the text into high-dimensional vectors.
- Storage – Store these vectors in a vector database. This allows the Summarizer Agent to pose sophisticated, natural language questions or requests, such as “Show me all logs related to user authentication errors in the last 15 minutes that correlate with an increase in P99 latency.”
Step 3: Implement the Triage Agent
This agent must be fast and accurate as it sets the stage for the entire response:
- Define persona – The agent’s LLM prompt should define a clear persona, such as “Alert Triage Specialist,” instructing it to be concise, factual, and strictly adhere to the company’s severity classification policy.
- Classification and correlation – The agent’s first action is a classification API call (using the LLM) to assign severity and service ownership. Its second action is to query the vector database to identify related events (e.g., a recent deployment, a network change, another concurrent alert).
- Output – This is a structured JSON object containing the
service_name,severity_level, and a list ofcorrelated_event_IDs.
Step 4: Develop the Context Summarizer
This context summarizer agent turns raw data into actionable intelligence. It implements the RAG pipeline:
- Retrieval – Using the Triage Agent’s output (service name, correlated events), the Summarizer Agent executes a vector search and a graph search (Hybrid RAG) to pull all relevant logs, traces, and metrics.
- Generation – The LLM is prompted with the retrieved data and instructed, “Based on the following raw operational data, generate a single, non-speculative, three-paragraph summary covering: 1) What is failing? 2) When did it start? 3) What is the likely root cause (with evidence)?”
- Output – This is the final concise incident summary ready for human consumption.
Step 5: Create the Runbook Proposer
- Runbook mapping – The agent is given access to a runbook repository (preferred to be a structured JSON list or private GitHub repository) where each entry is tagged with its
service,failure_type, andexecution_payload. - Reasoning – The agent uses the Summarizer’s context to select the most appropriate runbook. For an unprecedented event, it might generate a proposed new runbook, clearly labeled as “Experimental.”
- Output – This is a structured proposal containing the
runbook_ID, ajustificationfor its selection, and theexecution_payload(e.g., a shell script, Kubernetes YAML patch).
Step 6: Integrate HITL Gates
This is the most critical step for building trust:
- Approval workflow – The proposed solution is sent to a Slack/Teams bot, which acts as a secure intermediary. It shows a Triage Summary, Context Summary, and Runbook Proposal with action buttons: “Approve & Execute” and “Reject & Escalate” — or something else that suits your WoW style of working.
- Policy checks – Before the “Approve” button triggers any action, the Zero-Trust Gatekeeper (powered by OPA) checks the action’s details against current policies. This engine verifies the human’s role and the context of the action.
- Defensive execution– Once both policy and human approval are given, the execution layer automatically adds predefined safeguards to the runbook’s execution:
- Canary deployment – If the action involves a deployment, it’s initially rolled out to only 5% of traffic.
- Auto-rollback – Preconfigured health checks start immediately. If any fail, an automatic rollback is triggered, stopping the execution and alerting the human.
Step 7: Put the Whole Workflow Together
The Supervisor Agent connects everything using a State Machine (easily managed by a framework like LangGraph):
- Flow – The supervisor defines how things move from one stage to the next, as shown in Figure 2.
- End-to-end testing – Use the simulated alerts from Step 1 to test the entire process. The goal is to ensure that a simple alert leads to a complete context summary and a proposed action that needs human approval before it’s carried out. This confirms both the speed of the intelligence and the reliability of the safety features.

Conclusion: The Future Is Agentic Observability
This step-by-step guide illustrates that the ongoing transition is more than just an upgrade to agentic AIOps; it fundamentally redefines digital engineering and operations. This shift represents a potential paradigm in how we handle and respond to intelligence within our digital operations. The future of IT operations hinges on fostering a collaborative partnership between human experts and intelligent AI agents.
By embedding HITL principles, we create systems that are not only powerful and fast but more importantly, are safe, trustworthy, and accountable. The agent handles the cognitive load of sifting through petabytes of data, and the human retains ultimate authority over the live environment.
The journey toward this self-healing, agentic environment doesn’t require a “big bang” overhaul. Start small by identifying one persistent friction point in your incident response lifecycle — perhaps the tedious, repetitive task of context summarization — apply the agentic principles, and build a secure, gated workflow from there. This model is the foundation for proactive resilience, which is an evolution that elevates digital engineering from reactive fixes to intelligent self-management. The age of the autonomous yet overseen operations agent has arrived.
This is an excerpt from DZone’s 2025 Trend Report, Intelligent Observability: Building a Foundation for Reliability at Scale.
Read the Free Report
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}