Sponsored Content
Deployment of Low-Latency Solutions in the Cloud
Deployment of Low-Latency Solutions in the Cloud
This demo implements a replicated Chronicle Queue in a typical cloud-native environment.
This article was provided by and does not represent the editorial content of DZone.
Join the DZone community and get the full member experience.
Join For FreeTraditionally, companies with low-latency requirements deployed to bare-metal servers, eschewing the convenience and programmability of virtualization and containerization in an effort to squeeze maximum performance and minimal latency from “on-premises” (often co-located) hardware.
More recently, these companies are increasingly moving to public and private “cloud” environments, either for satellite services around their tuned low-latency/high-volume (LL/HV) systems or in some cases for LL/HV workloads themselves.
This demo implements a replicated Chronicle Queue in a typical cloud-native environment. The solution implements active/passive redundancy and automated fail-over driven by Consul service registry health checks. Live metrics are exposed using Prometheus and a Grafana dashboard.
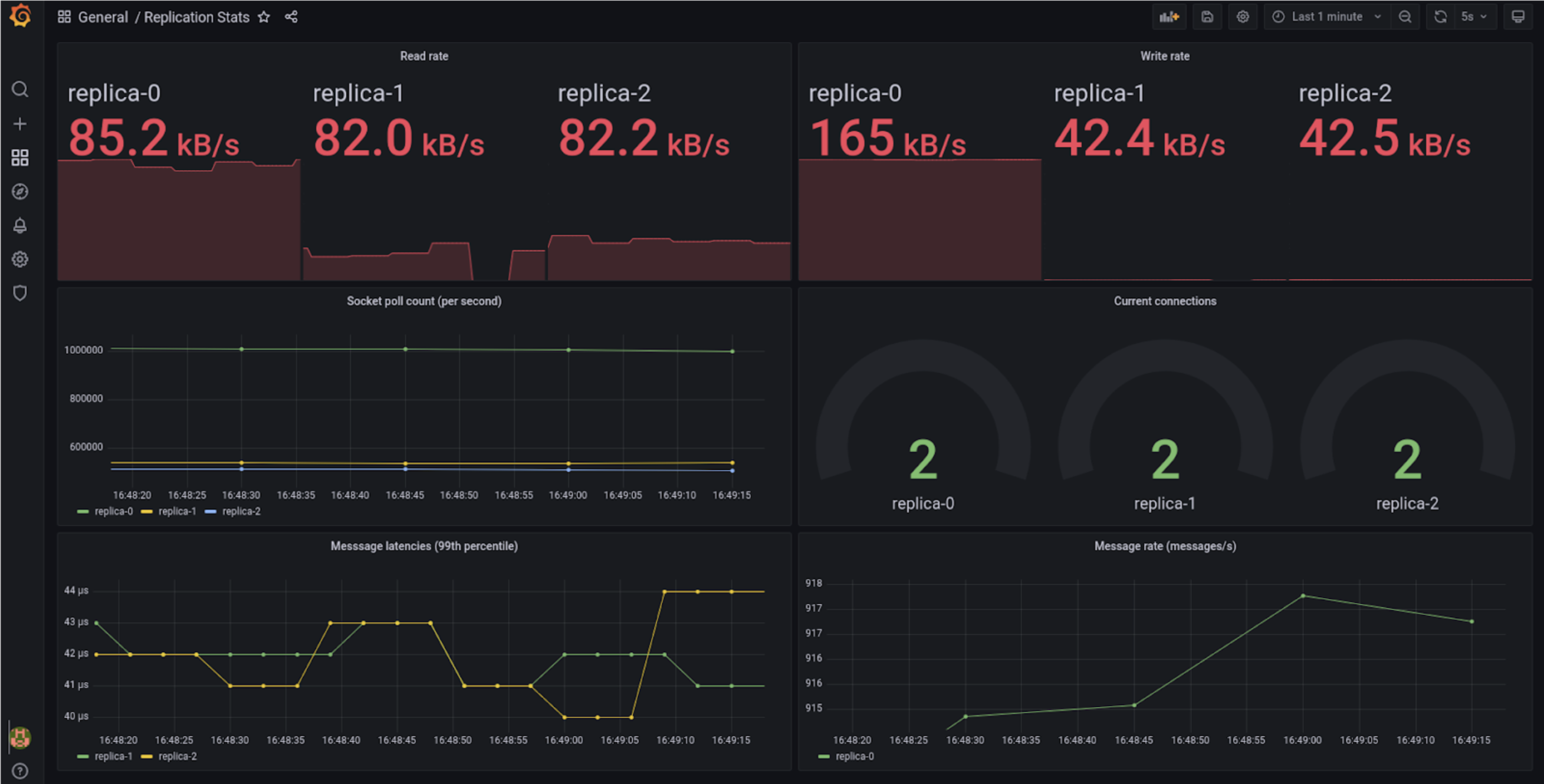
Figure 1: Metrics Panel — On the test device (an i9 laptop with NVME SSD running Minikube with the Docker driver) we see 99th percentile write-to-read latencies in the order of 40us (measured from leader to follower). This performance could be improved considerably, but no effort was made to tune the deployment or example code, as performance tuning is out of scope for this article.
Benefits and Challenges
Cloud-native environments offer a common platform and interfaces to ease definition and deployment of complex application architectures. This infrastructure enables the use of mature off-the-shelf components to solve common problems such as leader election, service discovery, observability, health-checks, self-healing, scaling, and configuration management.
Typically the pattern has been to run containers atop of virtual machines in these environments; however, now all the main cloud providers offer bare-metal (or near bare-metal) solutions, so even latency-sensitive workloads can be hosted in the cloud.
This is the first iteration of a demonstration of how Chronicle products can be used in these architectures and includes solutions to some of the challenges encountered by our clients in cloud and other environments. By leveraging common infrastructure solutions, we can marry the strengths of Chronicle products with the convenience of modern production environments to provide simple low-latency, operationally robust systems.
The Solution
The demo consists of a set of nodes in a cluster of configurable (and dynamic) size. We chose Kubernetes for the demo because it’s the de-facto standard for cloud-native infrastructure; however, most orchestration platforms implement similar features.
Each node in the cluster contains some toy business logic which stores its state in a replicated Chronicle Queue.
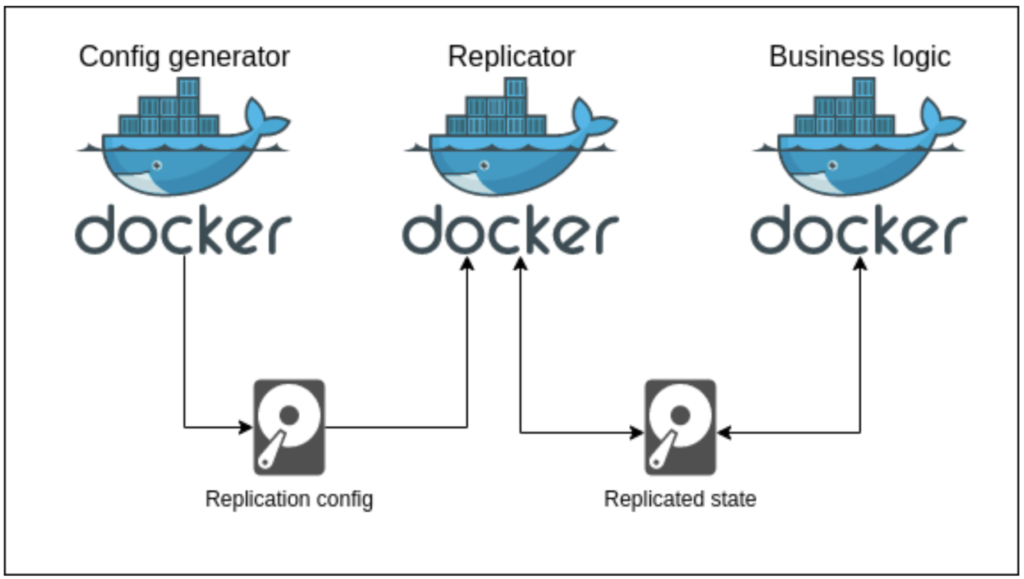
Figure 2: A diagram of a single pod, showing the important containers and volumes
The nodes in the cluster each maintain a copy of a Chronicle Queue, the copies are kept in sync by Chronicle Queue Enterprise replication. At any given time, one of the nodes is set as the “leader” node; the leader is responsible for populating the queue according to some business process. When the current leader node fails or is removed from the cluster, one of the “follower” nodes will be promoted to leader. This is a common pattern used to implement high availability.
The cluster nodes register themselves with the Consul service registry and configure a simple health check that monitors the node’s health by polling its metrics endpoint over HTTP. In a production deployment, this health check might be more sophisticated.
Each node is a Kubernetes Pod in a StatefulSet. The pods each contain the following containers:
1. business-logic
This container runs the toy “business logic” that either populates or reads from the queue (depending on its role). For the purposes of the demo, the business logic layer simply writes a sequence of values to the queue when leader, and prints those sequence numbers out as a follower. In a real-world deployment, this would be a real application — for example, Chronicle FIX in HA (High Availability) mode, Chronicle Matching Engine, or a custom application.
The cluster must nominate a single leader pod which is responsible for populating the queue, so the business logic layer engages in a Consul leader election. The pseudo-code for the business logic layer is as follows:
while (running) {
role = runLeaderElection()
while (role == leader) {
// Do leader logic
}
while (role == follower) {
// Do follower logic (if any)
}
}
The business logic container reads/writes the queue from/to the “replicated state” volume.
2. replicator
This container runs the Chronicle Enterprise Queue replication process. It monitors the “replication config” volume for updates to the replication configuration file and when an update is detected, it restarts replication with the new configuration. If the replication configuration is not present or invalid it does not start replication.
Restarting replication when a cluster changes is a common pattern we recommend, the restart itself happens in milliseconds meaning interruption to replication is minimal.
3. config-generator
Because we have Consul as a service registry, and our leadership election is conducted via the Consul key-value store, we can derive our replication configuration from the state of Consul alone.
This container uses Consul template to monitor Consul for changes in the cluster (e.g., addition or removal of nodes) or changes in the current leader. When any of these changes occur, the replication configuration is regenerated to the “replication config” volume.
4. exporter-merger
This container runs a process to combine Prometheus metrics from the replicator and business-logic containers.
Monitoring
Consul monitors the health of containers using configurable checks. If the health checks detect that a node has failed, it relinquishes the leadership (if held) and is removed from the cluster. Kubernetes also monitors the health of each pod, and when one fails, it is shut down and another is created to take its place.
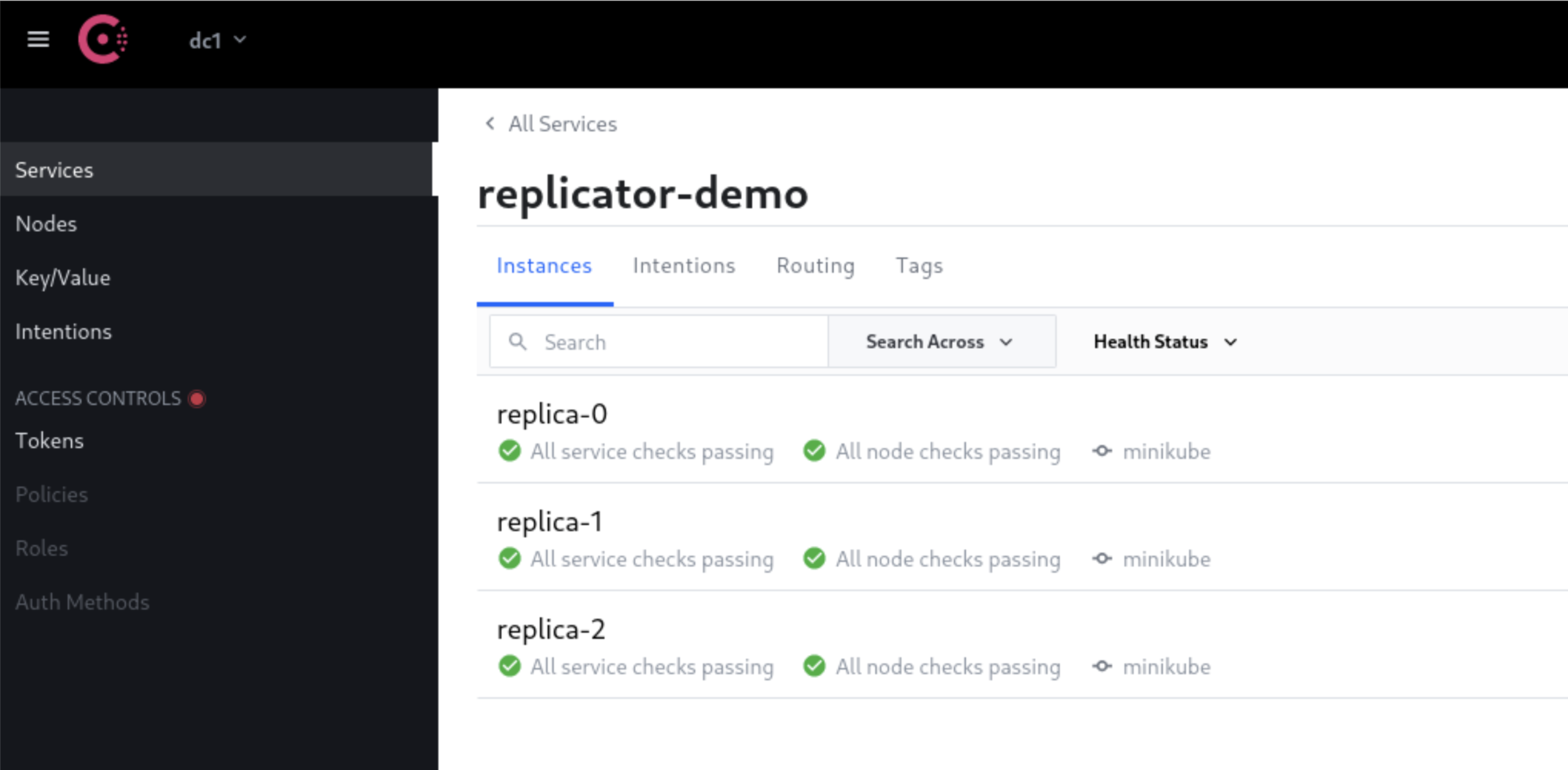
Figure 3: The Consul service registry UI showing the healthy cluster of replicas
The business logic and replication containers both publish metrics via Prometheus to expose the state of the cluster. The metrics published via Prometheus are then rendered as a dashboard by Grafana.
Figure 1 shows the metrics dashboard. You can see in this snapshot replica-0 was the leader and the other replicas are followers. The read rate on replica-0 is very high due to the acknowledgements coming back from the other replicas.
Summary
Consul maintains a registry of the cluster members and our application registers health checks to evict any unhealthy nodes from that. Consul also facilitates the leader election, determining which node should be leader and which should be followers. The Chronicle Queue replication configuration is then derived from the state of the cluster in Consul.
The demo has the following properties:
- When the leader node fails, a follower node is automatically promoted to be the new leader node.
- If the Kubernetes “scale” command is used to change the size of the cluster, the configuration of the nodes will automatically adjust. This scaling could also be automated in response to load.
- New nodes are discovered by Prometheus, and their metrics are automatically included in the dashboard.
- The fail-over occurs in approximately (time taken to detect failure, i.e., the health-check timeout) + (time to propagate Consul state) + (TCP round-trip to the Consul server) which, in the demo environment, is dominated by the health check timeout. For more geographically distributed deployments, the time to propagate consul state would become more significant.
- Most of this functionality is implemented by configuration not code. There are some thin adapters plugged into standard Chronicle interfaces that enable this behavior.
Conclusion
This article demonstrates one way to deploy a dynamic, low-latency, fault-tolerant Chronicle Queue-based application into a Kubernetes cluster.
There are constructs in Kubernetes (StatefulSets, dynamic provisioning) and Consul (service registry, leader election, configuration templating) that match nicely with concepts in Chronicle Queue Enterprise to greatly simplify the operational aspects of this.
Standard Chronicle interfaces allow the publishing of key metrics to provide a live view of the state of the deployed application.
Published at DZone with permission of Peter Lawrey. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}