Sponsored Content
Optimizing Isolation Levels for Scaling Distributed Databases
Optimizing Isolation Levels for Scaling Distributed Databases
This article will explain these levels and outline the tradeoffs between them. We will also recommend choosing the isolation level best suited to your needs.
This article was provided by and does not represent the editorial content of DZone.
Join the DZone community and get the full member experience.
Join For FreeIsolation is defined as the ability of a database to perform multiple transactions concurrently without negatively affecting each outcome. This article will explain these levels and outline the tradeoffs between them. We will also recommend choosing the isolation level best suited to your needs.
Let's start with the minimum knowledge required to use isolation levels effectively by examining two use cases representative of most applications and their effects on different isolation levels.
Use Case 1: Bank Transaction
A customer withdraws money from a bank account:
- Begin Transaction;
- Read the user's balance;
- Create a row in the activity table (we avoid calling this a transaction to prevent confusion with database transactions);
- Update the user's balance after subtracting the withdrawal amount from the amount read;
- Commit.
We do not want the user's balance to change until the transaction completes.
Use Case 2: Retail Transaction
An international customer purchases an item from a retail store using a currency that is different from the list price:
- Begin Transaction;
- Read the exchange_rate table to obtain the latest conversion rate;
- Create a row in the order table;
- Commit.
Let's assume that a separate process is continuously updating the exchange rates - but we do not care if an exchange rate changes after reading it, even if the current transaction has not yet been completed.
Serializable
The Serializable isolation level is the only one that satisfies the theoretical definition of the ACID property. It essentially states that two concurrent transactions are not allowed to interfere with each other's changes and must yield the same result if executed one after the other.
Unfortunately, Serializable is generally considered impractical, even for a non-distributed database. It is not a coincidence that all the existing popular databases like Postgres and MySQL recommend against it.
Why is this setting so impractical? Let us examine the two use cases:
In the Bank use case, Serializable is perfect. After reading a user's balance, the database guarantees that the user's balance will not change. So, it is safe to apply business logic, such as ensuring that the user has a sufficient balance and writing the new balance based on the value read. In the Bank use case, Serializable is perfect.
In the Retail use case, Serializable will also work correctly. The process that updates the exchange rates will not be allowed to perform its action until the transaction that creates the order succeeds.
This may sound like a great feature because of the precise sequencing of events. But what if the transaction that creates orders is slow and complex? Maybe it has to call out into warehouses to check inventory. Perhaps it has to perform credit checks on the user placing the order. It will hold the lock on that row, preventing the exchange rate process from updating. This possibly unintended dependency may prevent the system from scaling.
A Serializable setting is also subject to frequent deadlocks. For example, if two transactions read a user's balance, they will place a shared read lock on the row. If the transactions modify that row later, they will try to upgrade the read lock to a write lock. This will result in a deadlock because each transaction will be blocked by the read lock held by the other transaction. As we will see below, different isolation levels can easily avoid this problem.
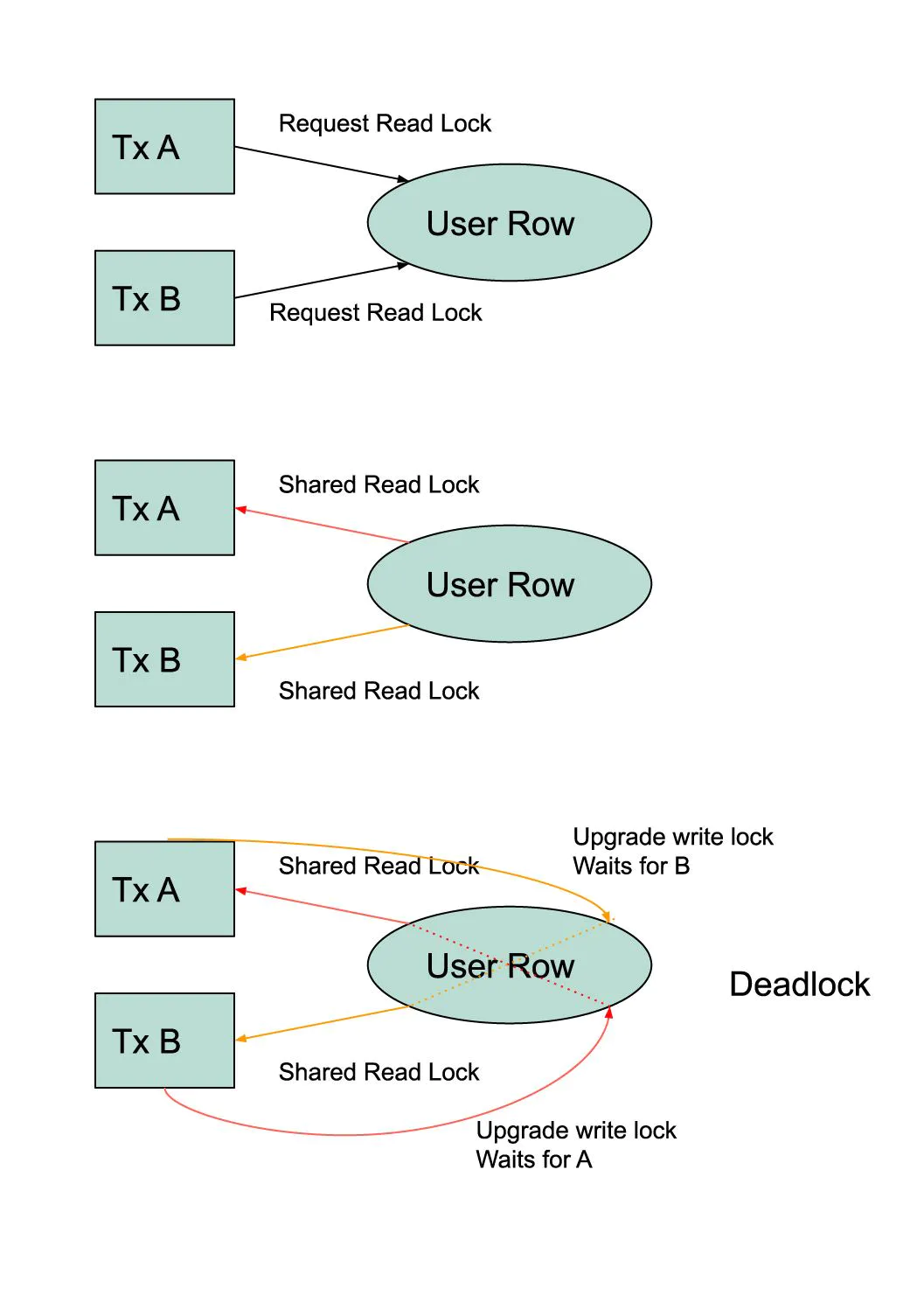
In other words, a contentious workload will fail to scale using a Serializable setting. We did not need this isolation level if the workload was not contentious. Lower isolation could have worked equally well.
To work around this unnecessary and expensive safety, the application has to be refactored. For example, the code that obtains the exchange rate may have to be called before the transaction starts, or the reader may have to be done using a separate connection.
Although not as theoretically pure, the other isolation levels allow you to perform Serializable reads on a case-by-case basis. This makes them more flexible and practical for writing scalable systems.
Lock Free Implementations
There are ways to provide Serializable consistency without locking data. However, such systems are subject to the same problems described above, where conflicting transactions fail differently. The root cause of the problem is in the isolation level itself, and no implementation can get you out of those constraints.
RepeatableRead
The RepeatableRead setting is an ambiguous one. This is because it differentiates point selects from searches and defines different behaviors for each. This is not black & white and has led to many other implementations. We won't go into the details of this isolation level. However, as far as our use cases are concerned, RepeatableRead offers the same guarantees as Serializable and consequently inherits the same problems.
SnapshotRead
The SnapshotRead isolation level, although not an ANSI standard, has been gaining popularity. This is also known as MVCC. The advantage of this isolation level is that it is contention-free: it creates a snapshot at the beginning of the transaction. All reads are sent to that snapshot without obtaining any locks. But writes follow the rules of strict Serializability.
A SnapshotRead transaction is most valuable for a read-only workload because you can see a consistent database snapshot. This avoids surprises while loading different pieces of data that depend on each other transactionally. You can also use the snapshot feature to read multiple tables at a particular time and then later observe the changes that have occurred since that snapshot. This functionality is convenient for Change Data Capture tools that want to stream changes to an analytics database.
For transactions that perform writes, the snapshot feature is not that useful. You mainly want to control whether to allow a value to change after the last read. If you want to allow the value to change, it will be stale as soon as you read it because someone else can update it later. So, it doesn't matter if you read from a snapshot or get the latest value. If you do not want it to change, you want the latest value, and the row must be locked to prevent changes.
In other words, SnapshotRead is useful for read-only workloads, but it is no better than ReadCommitted for write workloads, which we will cover next.
Re-applying the Retail use case in this isolation level works naturally without creating contention: The read from the exchange rate yields a value that was as of the snapshot when the transaction was created. While this transaction is in progress, a separate transaction is allowed to update the exchange rate.
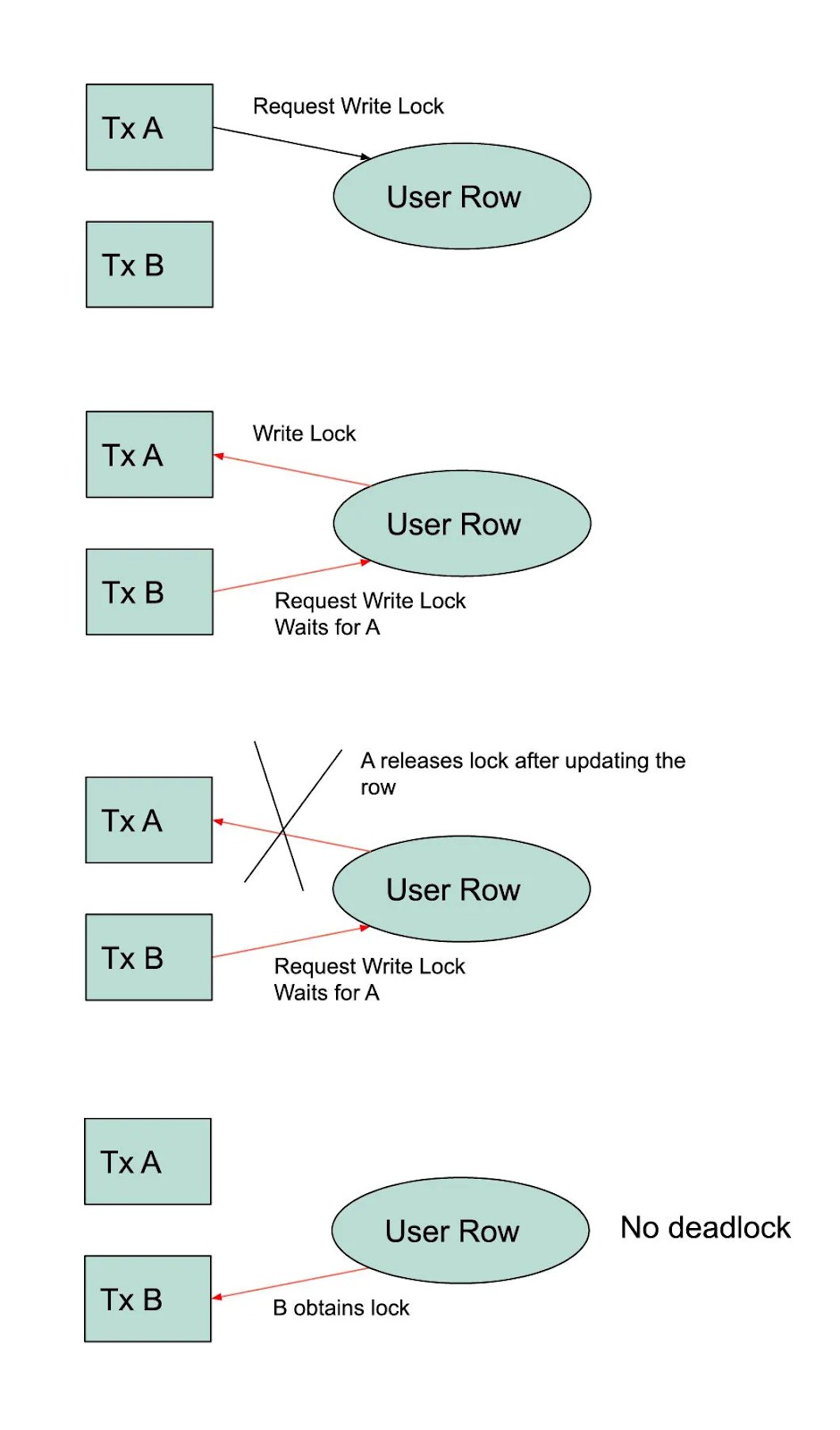
What about the Bank use case? Databases allow you to place locks on data. For example, MySQL will enable you to "select… lock in share mode" (read lock). This mode upgrades the read to that of a Serializable transaction. Of course, you also inherit the deadlock risks of this isolation level.
A lower isolation level offers you the best of both worlds. You can issue a "select… for update" (write lock). This lock prevents another transaction from obtaining any kind of lock on this row. This approach of pessimistic locking sounds worse at first but will allow two racing transactions to complete successfully without encountering a deadlock. The second transaction will wait for the first transaction to complete, at which point it will read and lock the row as of the new value.
MySQL supports the SnapshotRead isolation level by default but misleadingly calls it REPEATABLE_READ.
Distributed Databases
Although a single database has many ways of implementing Repeatable Reads efficiently, the problem becomes more complex in the case of distributed databases. This is because transactions can span multiple shards. If so, a strict ordering guarantee must be provided by the system. Such ordering requires the system to use a centralized concurrency control mechanism or a globally consistent clock. Both these approaches essentially attempt to tightly couple events that could have otherwise been executed independently of each other.
Therefore, one must understand and be willing to accept these tradeoffs before wanting a distributed database to support distributed Snapshot Reads.
ReadCommitted
The ReadCommitted isolation is less ambiguous than SnapshotRead because it continuously returns the latest view of the database. This is also the least contentious of the isolation levels. At this level, you may get a different value every time you read a row.
The ReadCommitted setting also allows you to upgrade your read by issuing a read or write lock, effectively allowing you to perform on-demand Serializable reads. As explained previously, this approach gives you the best of both worlds for application transactions that intend to modify data.
The default isolation level supported by Postgres is ReadCommitted.
ReadUncommitted
This isolation level is generally considered unsafe and is not recommended for distributed or non-distributed settings. This is because you may read data that might have later been rolled back (or never existed in the first place).
Distributed Transactions
This topic is orthogonal to isolation levels, but it is essential to cover this here because it has significance in keeping things loosely coupled.
In a distributed system, if two rows are in different shards or databases, and you want to atomically modify them in a single transaction, you incur the overhead of a two-phase commit (2PC).
This requires substantially more work:
- Metadata about the distributed transaction is created and saved to durable storage.
- A preparation is issued to all individual transactions.
- A decision to commit is saved to the metadata.
- A commit is issued to the prepared transactions.
A prepare requires you to save metadata so the transaction can be resurrected in the new leader if a node crashes before a commit (or rollback).
A distributed transaction also interacts with the isolation level. For example, let us assume that only the first commit of a 2PC transaction has succeeded, and the second commit is delayed. If the application has read the effects of the first commit, then the database must prevent the application from reading the rows of the second commit until completion. Flipping this around, if the application has read a row before the second commit, then it must not see the effects of the first commit.
The database has to do additional work to support the isolation guarantees for distributed transactions. What if the application could tolerate these partial commits? Then we are doing unnecessary work that the application doesn't care about. It may be worth introducing a new isolation level like ReadPartialCommits. Note that this differs from ReadUncommitted, where you may read data that may eventually be rolled back.
Lastly, excessive use of 2PC reduces a system's overall availability and latency. This is because the worst-performing shard will dictate your effective availability.
In Conclusion
To be scalable, an application should avoid relying on any advanced isolation features of a database. It should instead try to use as few guarantees as possible. If you can write an application to work with the ReadCommitted isolation level, then moving to SnapshotRead should be discouraged. Serializable or RepeatableRead is almost always a bad idea.
It is also better to avoid multi-statement transactions, but this may become unavoidable as the application evolves. At that point, try mainly relying on the atomic guarantees of transactions and stay at the lowest isolation level supported by the database system.
If using a sharded database, avoid distributed transactions entirely. This can be achieved by keeping related rows within the same shard. One must do this from the beginning because it is tough to refactor a non-concurrent program to be concurrent.
Published at DZone with permission of Sugu Sougoumarane. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}