Sponsored Content
Diffs Are Dead: Why You Need Scalable Previews
Diffs Are Dead: Why You Need Scalable Previews
Coding agents are rendering manual code review obsolete. The shift to an outcome-based review model is necessary, but poses a challenge for platform teams at scale.
This article was provided by and does not represent the editorial content of DZone.
Join the DZone community and get the full member experience.
Join For FreeThe software development lifecycle (SDLC) is going through a massive shift as coding agents become increasingly ubiquitous in the industry. While this has very visible impacts that have been widely documented, it also results in more subtle changes that are less obvious.
I noticed one of those changes recently: code review has all but died without us noticing. I have seen this happen on my own engineering team. Senior engineers known for meticulous review are approving pull requests (PRs) within minutes.
Code generated by agents has perfect syntax. If it passes unit tests and the linter is happy, what is the point of reviewing the diff line by line? Reviewers are spinning up the deploy preview, validating that the change functions as expected, and moving on.
This is a positive shift. The goal of engineering has always been to deliver outcomes, not code with perfect syntax. By removing the friction of line-by-line review, agents allow us to focus on end results. However, this transformation to an outcome-based review model presents an infrastructural challenge: validating behavior at the same pace as agents can generate code.

This challenge is particularly acute for cloud-native teams. Validating a change to a cloud-native application requires access to dozens of dependencies, making local testing impossible and shifting the burden entirely to shared cloud infrastructure.
The Collapse of Text-Based Review
The diff-based peer review has long been the primary mechanism for quality assurance in software. This process relies on a specific assumption: that code is written with human intent. When a developer writes a function, the diff represents a deliberate set of choices. A human reviewer reads the diff to understand the intent and verify that the implementation matches their mental model of the system.
AI agents break this assumption. An agent does not have intent. It has probabilistic determination. When an agent generates a thousand lines of code to solve a ticket, the resulting diff is not a map of intent. It is simply a large volume of tokens that statistically align with a prompt.
Reviewing this output via a text-based diff is increasingly dangerous. The code often looks syntactically perfect. It adheres to linting rules. It includes passing unit tests. Consequently, human reviewers fall into a pattern of superficial approval. They see green tests and clean syntax, so they approve the change.
As developers increasingly rely on agents to write code, syntax becomes increasingly irrelevant. The only thing that matters is behavior. To verify behavior, engineers cannot rely on static text files. They need to see the code running in an integrated environment. The pull request view has to be replaced by a live preview environment, and code review has to be replaced by behavior validation.
The Concurrency Problem
The issue is that for most teams, getting a live preview environment means submitting a PR and waiting for CI. This quickly becomes unworkable at scale when you introduce the velocity of coding agents.
Consider the workflow of a human developer. They work linearly: they open a branch, write code, open a pull request, and wait for feedback. A single developer might have one or two active branches at a time. A team of twenty developers might generate five to ten PRs per day.
Agents allow a single developer to become a manager of multiple workstreams. Instead of serially fixing one bug, waiting for CI, and then moving to the next, a developer can assign three agents to three different tickets simultaneously.
Each of those agents needs a validation environment. Cloud-native apps are too complex for changes to be validated fully locally, so every iteration the agent makes triggers a build and deploy to shared infrastructure. The agent cannot test locally and only submits the best one. It needs access to the cluster context.
If a team of ten engineers uses multiple agents to parallelize addressing their backlog, the pipeline suddenly faces a massive load of concurrent integration jobs that it wasn’t built for.
Traditional pipelines handle this scenario poorly. Most organizations rely on a limited set of staging environments or a shared integration cluster. When the queue depth explodes from five jobs to hundreds, the pipeline grinds to a halt. The time-to-feedback increases from minutes to hours, negating the velocity gains provided by the coding agents in the first place.
Environment Cloning Does Not Scale
The brute-force solution to this problem is to scale the infrastructure linearly with the agents. If you have one hundred agent tasks, you simply spin up one hundred full-stack environments.
This approach is impossible in practical terms for cloud-native teams. A modern microservices architecture running on Kubernetes might consist of fifty distinct services, a primary database, a Redis cache, and a message queue. Duplicating this entire stack for every single agent-generated PR is astronomically expensive and complex to manage.
Cloud provisioning is also slow. Spinning up a fresh Kubernetes cluster and seeding a database with test data can take ten to twenty minutes. If the infrastructure takes orders of magnitude longer to provision than the code takes to write, the infrastructure becomes the critical constraint.
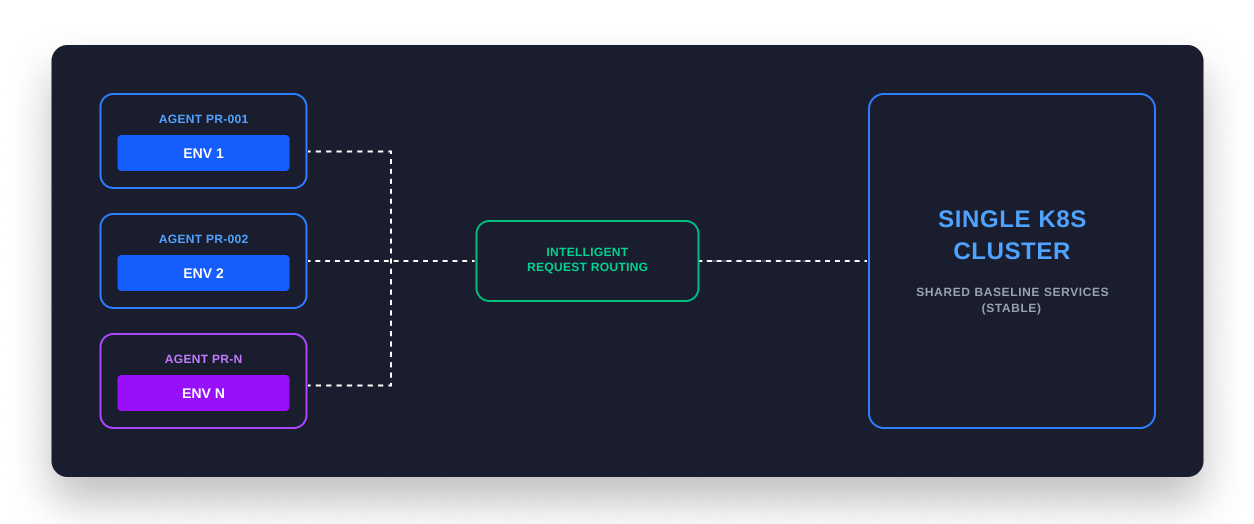
Ephemeral Environments for Scalable Validation
To solve the validation gap, platform teams need to implement scalable preview infrastructure. The goal is to provide every agent-generated PR with a unique, isolated environment that enables previews without the overhead of duplication.
Using ephemeral environments combined with intelligent request routing offers a solution here. This architecture shares a baseline environment that runs the stable version of all services. When an agent proposes a change to a specific microservice, the preview infrastructure spins up only that modified service in a lightweight sandbox.
Traffic routing becomes the mechanism of isolation. The system routes requests dynamically based on context. When a request is associated with a specific agent PR, the network layer routes that request to the sandboxed version of the modified service. If the request needs to communicate with downstream dependencies that have not changed, it is routed back to the stable baseline services.
This approach allows for hundreds of environments to exist within a single physical cluster without the load or cost of namespace duplication. It makes the cost of spinning up a new preview environment marginal because you are only paying for the compute of the specific microservices that are under test and their dependencies, not the entire stack.
Conclusion
We are moving from an era of scarcity to an era of abundance in code generation. This shift exposes the fragility of our current code review model. The diff is a relic of a time when code volume was low, and human intent was the primary driver of change.
To survive the concurrency explosion brought on by AI agents, organizations must invest in preview infrastructure that is as scalable as the new generation layer. This means moving away from linear CI pipelines and heavy, static staging environments.
By leveraging lightweight ephemeral environment solutions like Signadot that use intelligent request routing, teams can multiplex hundreds or thousands of concurrent previews on shared infrastructure without the cost of duplication.
As agent-generated code becomes the norm, the thing that differentiates one team from another in terms of productivity will no longer be the speed of their engineers, but rather the speed of their validation infrastructure.
Check out the full Signadot article collection here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}