Sponsored Content
Why Kubernetes Is the New Application Server
Why Kubernetes Is the New Application Server
Why do you need containers to deploy your multi-platform app? See how Kubernetes can solve all the same problems in this article.
This article was provided by and does not represent the editorial content of DZone.
Join the DZone community and get the full member experience.
Join For FreeHave you ever wondered why you are deploying your multi-platform applications using containers? Is it just a matter of "following the hype"? In this article, I'm going to ask some provocative questions to make my case for why Kubernetes is the new application server.
You might have noticed that the majority of languages are interpreted and use "runtimes" to execute your source code. In theory, most Node.js, Python, and Ruby code can be easily moved from one platform (Windows, Mac, Linux) to another platform. Java applications go even further by having the compiled Java class turned into a bytecode, capable of running anywhere that has a JVM (Java Virtual Machine).
The Java ecosystem provides a standard format to distribute all Java classes that are part of the same application. You can package these classes as a JAR (Java Archive), WAR (Web Archive), and EAR (Enterprise Archive) that contains the front end, back end, and libraries embedded. So I ask you: Why do you use containers to distribute your Java application? Isn't it already supposed to be easily portable between environments?
Answering this question from a developer perspective isn't always obvious. But think for a moment about your development environment and some possible issues caused by the difference between it and the production environment:
- Do you use Mac, Windows, or Linux? Have you ever faced an issue related to
\versus/as the file path separator? - What version of JDK do you use? Do you use Java 10 in development, but production uses JRE 8? Have you faced any bugs introduced by JVM differences?
- What version of the application server do you use? Is the production environment using the same configuration, security patches, and library versions?
- During production deployment, have you encountered a JDBC driver issue that you didn't face in your development environment due to different versions of the driver or database server?
- Have you ever asked the application server admin to create a datasource or a JMS queue and it had a typo?
All the issues above are caused by factors external to your application, and one of the greatest things about containers is that you can deploy everything (for example, a Linux distribution, the JVM, the application server, libraries, configurations and, finally, your application) inside a pre-built container. Plus, executing a single container that has everything built in is incredibly easier than moving your code to a production environment and trying to resolve the differences when it doesn't work. Since it's easy to execute, it is also easy to scale the same container image to multiple replicas.
Empowering Your Application
Before containers became very popular, several NFR (non-functional requirements) such as security, isolation, fault tolerance, configuration management, and others were provided by application servers. As an analogy, the application servers were planned to be to applications what CD (Compact Disc) players are to CDs.
As a developer, you would be responsible to follow a predefined standard and distribute the application in a specific format, while on the other hand the application server would "execute" your application and give additional capabilities that could vary from different "brands." Note: In the Java world, the standard for enterprise capabilities provided by an application server has recently moved under the Eclipse foundation. The work on Eclipse Enterprise for Java (EE4J), has resulted in Jakarta EE. (For more info, read the article Jakarta EE is officially out or watch the DevNation video: Jakarta EE: The future of Java EE.)
Following the same CD player analogy, with the ascension of containers, the container image has become the new CD format. In fact, a container image is nothing more than a format for distributing your containers. (If you need to get a better handle on what container images are and how they are distributed see A Practical Introduction to Container Terminology.)
The real benefits of containers happen when you need to add enterprise capabilities to your application. And the best way to provide these capabilities to a containerized application is by using Kubernetes as a platform for them. Additionally, the Kubernetes platform provides a great foundation for other projects such as Red Hat OpenShift, Istio, and Apache OpenWhisk to build on and make it easier to build and deploy robust production quality applications.
Let's explore nine of these capabilities:
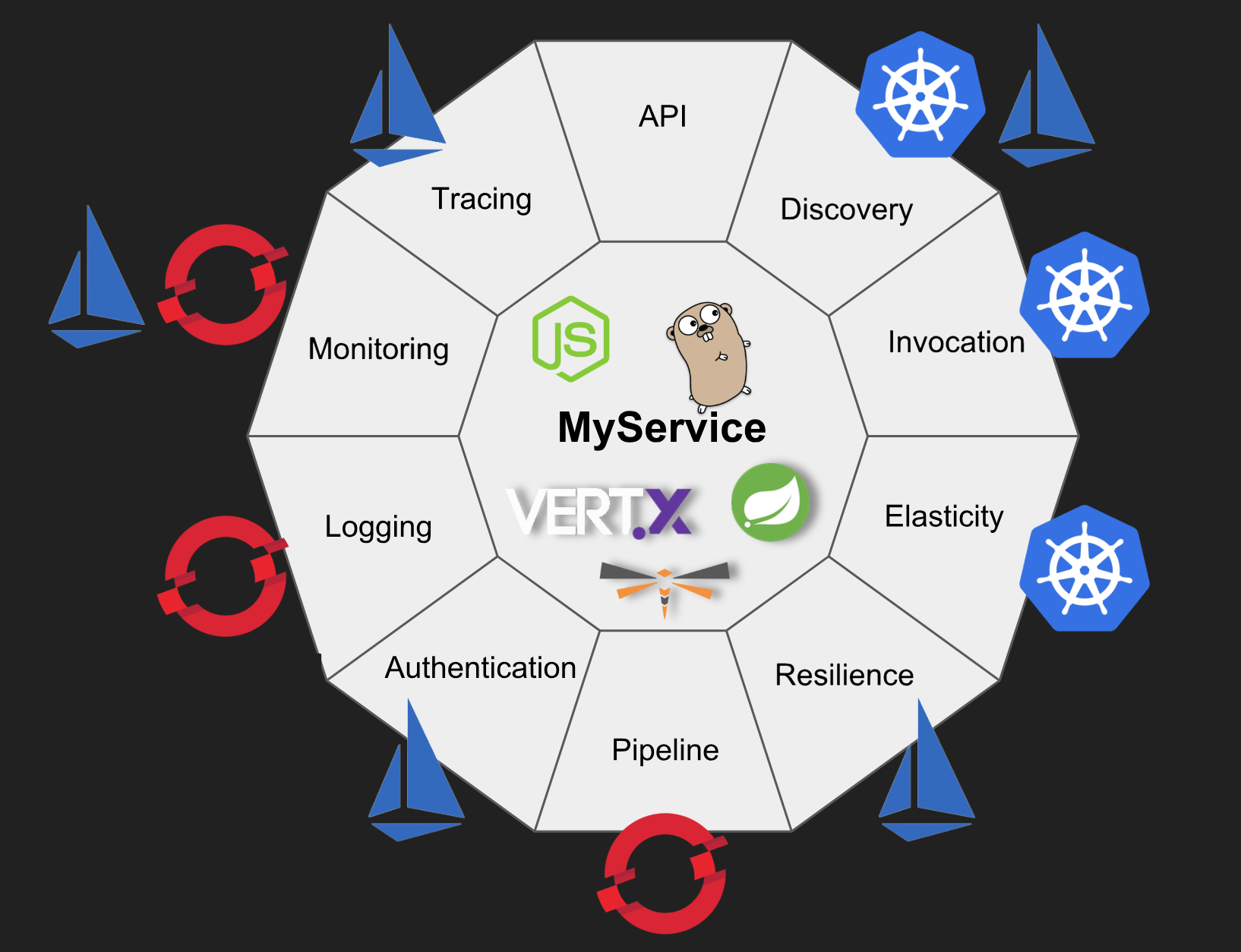
Service Discovery
Service discovery is the process of figuring out how to connect to a service. To get many of the benefits of containers and cloud-native applications, you need to remove the configuration from your container images so you can use the same container image in all environments. Externalized configuration from applications is one of the key principles of the 12-factor application. Service discovery is one of the ways to get configuration information from the runtime environment instead of it being hardcoded in the application. Kubernetes provides service discovery out of the box. Kubernetes also provides ConfigMaps and Secrets for removing the configuration from your application containers. Secrets solve some of the challenges that arise when you need to store the credentials for connecting to a service like a database in your runtime environment.
With Kubernetes, there's no need to use an external server or framework. While you can manage the environment settings for each runtime environment through Kubernetes YAML files, Red Hat OpenShift provides a GUI and CLI that can make it easier for DevOps teams to manage.
Basic Invocation
Applications running inside containers can be accessed through Ingress access — in other words, routes from the outside world to the service you are exposing. OpenShift provides route objects using HAProxy, which has several capabilities and load-balancing strategies. You can use the routing capabilities to do rolling deployments. This can be the basis of some very sophisticated CI/CD strategies. See "6 - Build and Deployment Pipelines" below.
What if you need to run a one-time job, such as a batch process, or simply leverage the cluster to compute a result (such as computing the digits of Pi)? Kubernetes provides job objects for this use case. There is also a cron job that manages time-based jobs.
Elasticity
Elasticity is solved in Kubernetes by using ReplicaSets (which used to be called Replication Controllers). Just like most configurations for Kubernetes, a ReplicaSet is a way to reconcile a desired state: you tell Kubernetes what state the system should be in and Kubernetes figures out how to make it so. A ReplicaSet controls the number of replicas or exact copies of the app that should be running at any time.
But what happens when you build a service that is even more popular than you planned for and you run out of compute? You can use the Kubernetes Horizontal Pod Autoscaler, which scales the number of pods based on observed CPU utilization (or, with custom metrics support, on some other application-provided metrics).
Logging
Since your Kubernetes cluster can and will run several replicas of your containerized application, it's important that you aggregate these logs so they can be viewed in one place. Also, in order to utilize benefits like autoscaling (and other cloud-native capabilities), your containers need to be immutable. So you need to store your logs outside of your container so they will be persistent across runs. OpenShift allows you to deploy the EFK stack to aggregate logs from hosts and applications, whether they come from multiple containers or even from deleted pods.
The EFK stack is composed of:
- Elasticsearch (ES), an object store where all logs are stored
- Fluentd, which gathers logs from nodes and feeds them to Elasticsearch
- Kibana, a web UI for Elasticsearch
Monitoring
Although logging and monitoring seem to solve the same problem, they are different from each other. Monitoring is observation, checking, often alerting, as well as recording. Logging is recording only.
Prometheus is an open-source monitoring system that includes time series database. It can be used for storing and querying metrics, alerting, and using visualizations to gain insights into your systems. Prometheus is perhaps the most popular choice for monitoring Kubernetes clusters. On the Red Hat Developers blog, there are several articles covering monitoring using Prometheus. You can also find Prometheus articles on the OpenShift blog.
You can also see Prometheus in action together with Istio here.
Build and Deployment Pipelines
CI/CD (Continuous Integration/Continuous Delivery) pipelines are not a strict "must have" requirement for your applications. However, CI/CD are often cited as pillars of successful software development and DevOps practices. No software should be deployed into production without a CI/CD pipeline. The book Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation, by Jez Humble and David Farley, says this about CD: "Continuous Delivery is the ability to get changes of all types-including new features, configuration changes, bug fixes and experiments-into production, or into the hands of users, safely and quickly in a sustainable way."
OpenShift provides CI/CD pipelines out of the box as a "build strategy." Check out this video that I recorded two years ago, which has an example of a Jenkins CI/CD pipeline that deploys a new microservice.
Resilience
While Kubernetes provides resilience options for the cluster itself, it can also help the application be resilient by providing PersistentVolumes that support replicated volumes. Kubernetes' ReplicationControllers/deployments ensure that the specified numbers of pod replicas are consistently deployed across the cluster, which automatically handles any possible node failure.
Together with resilience, fault tolerance serves as an effective means to address users' reliability and availability concerns. Fault tolerance can also be provided to an application that is running on Kubernetes through Istio by its retries rules, circuit breaker, and pool ejection. Do you want to see it for yourself? Try the Istio Circuit Breaker tutorial.
Authentication
Authentication in Kubernetes can also be provided by Istio through its mutual TLS authentication, which aims to enhance the security of microservices and their communication without requiring service code changes. It is responsible for:
- Providing each service with a strong identity that represents its role to enable interoperability across clusters and clouds
- Securing service-to-service communication and end user-to-service communication
- Providing a key management system to automate key and certificate generation, distribution, rotation, and revocation
Additionally, it is worth mentioning that you can also run Keycloak inside a Kubernetes/OpenShift cluster to provide both authentication and authorization. Keycloak is the upstream product for Red Hat Single Sign-on. For more information, read Single-Sign On Made Easy with Keycloak. If you are using Spring Boot, watch the DevNation video: Secure Spring Boot Microservices with Keycloak or read the blog article.
Tracing
Istio-enabled applications can be configured to collect trace spans using Zipkin or Jaeger. Regardless of what language, framework, or platform you use to build your application, Istio can enable distributed tracing. Check it out here. See also Getting Started with Istio and Jaeger on your laptop and the recent DevNation video: Advanced microservices tracing with Jaeger.
Are Application Servers Dead?
Going through these capabilities, you can realize how Kubernetes + OpenShift + Istio can really empower your application and provide features that used to be the responsibility of an application server or a software framework such as Netflix OSS. Does that mean application servers are dead?
In this new containerized world, application servers are mutating into becoming more like frameworks. It's natural that the evolution of software development caused the evolution of application servers. A great example of this evolution is the Eclipse MicroProfile specification having WildFly Swarm as the application server, which provides to the developer features such as fault tolerance, configuration, tracing, REST (client and server), and so on. However, WildFly Swarm and the MicroProfile specification are designed to be very lightweight. WildFly Swarm doesn't have the vast array of components required by a full Java enterprise application server. Instead, it focuses on microservices and having just enough of the application server to build and run your application as a simple executable .jar file. You can read more about MicroProfile on this blog.
Furthermore, Java applications can have features such as the Servlet engine, a datasource pool, dependency injection, transactions, messaging, and so forth. Of course, frameworks can provide these features, but an application server must also have everything you need to build, run, deploy, and manage enterprise applications in any environment, regardless of whether they are inside containers. In fact, application servers can be executed anywhere, for instance, on bare metal, on virtualization platforms such as Red Hat Virtualization, on private cloud environments such as Red Hat OpenStack Platform, and also on public cloud environments such as Microsoft Azure or Amazon Web Services.
A good application server ensures consistency between the APIs that are provided and their implementations. Developers can be sure that deploying their business logic, which requires certain capabilities, will work because the application server developers (and the defined standards) have ensured that these components work together and have evolved together. Furthermore, a good application server is also responsible for maximizing throughput and scalability, because it will handle all the requests from the users; having reduced latency and improved load times, because it will help your application's disposability; be lightweight with a small footprint that minimizes hardware resources and costs; and finally, be secure enough to avoid any security breach. For Java developers, Red Hat provides Red Hat JBoss Enterprise Application Platform, which fulfills all the requirements of a modern, modular application server.
Conclusion
Container images have become the standard packaging format to distribute cloud-native applications. While containers "per se" don't provide real business advantages to applications, Kubernetes and its related projects, such as OpenShift and Istio, provide the non-functional requirements that used to be part of an application server.
Most of these non-functional requirements that developers used to get from an application server or from a library such as Netflix OSS were bound to a specific language, for example, Java. On the other hand, when developers choose to meet these requirements using Kubernetes + OpenShift + Istio, they are not attached to any specific language, which can encourage the use of the best technology/language for each use case.
Finally, application servers still have their place in software development. However, they are mutating into becoming more like language-specific frameworks that are a great shortcut when developing applications, since they contain lots of already written and tested functionality.
One of the best things about moving to containers, Kubernetes, and microservices is that you don't have to choose a single application server, framework, architectural style or even language for your application. You can easily deploy a container with JBoss EAP running your existing Java EE application, alongside other containers that have new microservices using Wildfly Swarm, or Eclipse Vert.x for reactive programming. These containers can all be managed through Kubernetes. To see this concept in action, take a look at Red Hat OpenShift Application Runtimes. Use the Launch service to build and deploy a sample app online using WildFly Swarm, Vert.x, Spring Boot, or Node.js. Select the Externalized Configuration mission to learn how to use Kubernetes ConfigMaps. This will get you started on your path to cloud-native applications.
You can say that Kubernetes/OpenShift is the new Linux or even that "Kubernetes is the new application server." But the fact is that an application server/runtime + OpenShift/Kubernetes + Istio has become the "de facto" cloud-native application platform!
Published at DZone with permission of Rafael Benevides. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}