
About HTTP
The Hypertext Transfer Protocol (HTTP) is an application protocol for distributed, collaborative, hypermedia information systems. HTTP is the foundation of data communication for the World Wide Web.
Hypertext is a multi-linear set of objects, building a network by using logical links (the so-called hyperlinks) between the nodes (e.g. text or words). HTTP is the protocol to exchange or transfer hypertext.
RFC 2616 Hypertext Transfer Protocol: http://www.w3.org/Protocols/rfc2616/rfc2616.htmlUniform resource identifier (URI) is a string of characters used to identify a name or a resource.
RFC 1630: Universal Resource Identifiers (URI): http://tools.ietf.org/html/rfc1630Uniform resource name (URN) is a uniform resource identifier (URI) that uses the urn scheme and does not imply availability of the identified resource. Both URN's (names) and URL's (locators) are URI's, and a particular URI may be a name and a locator at the same time.
BASIC SYNTAX:

EXAMPLE:
urn:isbn:9781849683166The URN for 'Java EE6 Cookbook for Securing, Tuning and Extending Enterprise applications.'
RFC 1737: Uniform Resource Names (URN): http://tools.ietf.org/html/rfc1737Uniform resource locator (URL) is a specific character string that constitutes a reference to an Internet resource.
BASIC SYNTAX:

EXAMPLE:
http://baselogic.com:80/blog/?param1=value¶m2=value#anchorRFC 1808: Relative Uniform Resource Locators (URL): http://tools.ietf.org/html/rfc1808Typical Schemes
| Scheme | Description |
|---|---|
| http: | Hypertext transfer protocol |
| https: | Secured Hypertext transfer protocol |
| mailto: | Email composer |
| ftp: | File transfer protocol |
QUERY STRING ENCODING USES THE FOLLOWING RULES:
- Letters (A-Z and a-z), numbers (0-9) and the characters '.','-','~' and '_' are left as-is
- SPACE is encoded as '+' or hexadecimal (%20)
- All other characters are encoded as %FF hexadecimal representation with any non-ASCII characters first encoded as UTF-8 (or other specified encoding)
- The typical maximum value for a single GET parameter value is 512 bytes
Request Methods
HTTP defines methods (sometimes referred to as "verbs") to indicate the desired action to be performed on the identified resource. What this resource represents, whether pre-existing data or data that is generated dynamically, depends on the implementation of the server. Often, the resource corresponds to a file or the output of an executable residing on the server.
The HTTP/1.0 specification: section 8 defined the GET, POST and HEAD methods and the HTTP/1.1 specification: section 9 added 5 new methods: OPTIONS, PUT, DELETE, TRACE and CONNECT. By being specified in these documents their semantics are known and can be depended upon. Any client can use any method that they want and the server can choose to support any method it wants. If a method is unknown to an intermediate it will be treated as an un-safe and non-idempotent method. There is no limit to the number of methods that can be defined and this allows for future methods to be specified without breaking existing infrastructure. For example WebDAV (RFC5789) defined 7 new methods and RFC5789 specified the PATCH method.
| Method | Description |
|---|---|
| CONNECT | This specification reserves the method name CONNECT for use with a proxy that can dynamically switch to being a tunnel (e.g. SSL tunneling). |
| DELETE | The DELETE method requests that the origin server delete the resource identified by the Request-URI. |
| GET | The GET method means retrieves whatever information (in the form of an entity) is identified by the Request-URI. |
| HEAD | The HEAD method is identical to GET except that the server MUST NOT return a message-body in the response. |
| OPTIONS | The OPTIONS method represents a request for information about the communication options available on the request/response chain identified by the Request-URI. |
| POST | The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line. |
| PUT | The PUT method requests that the enclosed entity be stored under the supplied Request-URI. |
| TRACE | The TRACE method is used to invoke a remote, application-layer loop-back of the request message. |
RFC 2616-sec9: HTTP Method definitions: http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html

URI Length Limits
| Implementation | Limit |
|---|---|
| Firefox | Unlimited, although instability occurs with URLs reaching around 65,000 characters. |
| Safari | Unlimited. |
| Internet Explorer v6 - v7 | Maximum length of a URL in Internet Explorer is 2,083 characters, with no more than 2,048 characters in the path portion of the URL. |
| Internet Explorer v8+ | Maximum length of a URL in Internet Explorer is 4,095 characters, with no more than 2,048 characters in the path portion of the URL. Maximum mailto: length is 500 to 512 characters long. |
| Sitemap Protocol | <loc> URL of the page. This URL must begin with the protocol (such as http) and end with a trailing slash, if your web server requires it. This value must be less than 2,048 characters. |
| GoogleBot crawler | Google will index URLs up to 2047 characters in length. |
| Google search results page(SERP) | Google index-able links that will work when clicked in the SERP's is ~1855 characters in length. |

Request Message
The request message consists of the following:

The request line and headers must all end with <CR><LF> (that is, a carriage return character followed by a line feed character (\r\n)). The empty line must consist of only <CR><LF> and no other whitespace. In the HTTP/1.1 protocol, all headers except Host are optional.
A request line containing only the path name is accepted by servers to maintain compatibility with HTTP clients before the HTTP/1.0 specification in RFC1945.
RFC 2616-sec5: HTTP Request: http://www.w3.org/Protocols/rfc2616/rfc2616-sec5.html
Response Message
The response message consists of the following:
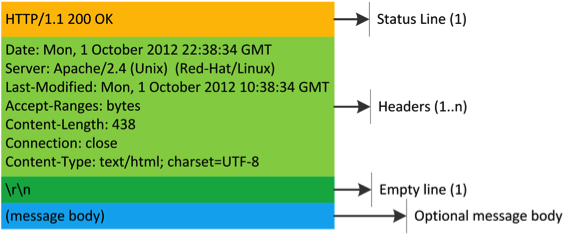
The Status-Line and headers must all end with <CR><LF> (a carriage return followed by a line feed). The empty line must consist of only <CR><LF> and no other whitespace.
RFC 2616-sec6: HTTP Response: http://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html
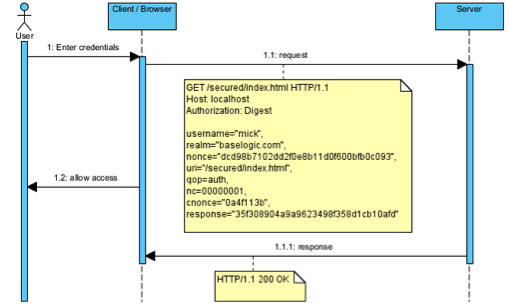
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}