6 Effective Strategies for Kubernetes Observability in Hybrid Cloud Environments
Observing Kubernetes in hybrid cloud environments requires understanding distributed system behavior and performance. These six strategies can help achieve this.
Join the DZone community and get the full member experience.
Join For Free2023 has seen rapid growth in native-cloud applications and platforms. Organizations are constantly striving to maximize the potential of their applications, ensure seamless user experiences, and drive business growth.
The rise of hybrid cloud environments and the adoption of containerization technologies, such as Kubernetes, have revolutionized the way modern applications are developed, deployed, and scaled.
In this digital arena, Kubernetes is the platform of choice for most cloud-native applications and workloads, which is adopted across industries.
According to a 2022 report, 96% of companies are already either using or evaluating the implementation of Kubernetes in their cloud system. This popular open-source utility is helpful for container orchestration and discovery, load balancing, and other capabilities.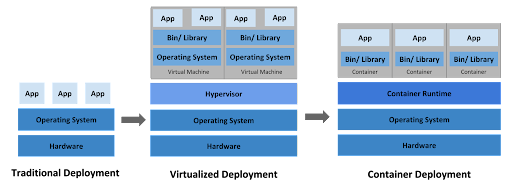
However, with this transformation comes a new set of challenges.
As the complexity of applications increases, so does the need for robust observability solutions that enable businesses to gain deep insights into their containerized workloads. Enter Kubernetes observability—a critical aspect of managing and optimizing containerized applications in hybrid cloud environments.
In this blog post, we will delve into Kubernetes observability, exploring six effective strategies that can empower businesses to unlock the full potential of their containerized applications in hybrid cloud environments.
These strategies, backed by industry expertise and real-world experiences, will equip you with the tools and knowledge to enhance the observability of your Kubernetes deployments, driving business success.
Understanding Observability in Kubernetes
Let us first start with the basics.
Kubernetes is a powerful tool for managing containerized applications. But despite its powerful features, keeping track of what's happening in a hybrid cloud environment can be difficult. This is where observability comes in.
Observability is collecting, analyzing, and acting on data in a particular environment. In the context of Kubernetes, observability refers to gaining insights into the behavior, performance, and health of containerized applications running within a Kubernetes cluster.
Kubernetes Observability is based on three key pillars:
1. Logs: Logs provide valuable information about the behavior and events within a Kubernetes cluster. They capture important details such as application output, system errors, and operational events. Analyzing logs helps troubleshoot issues, understand application behavior, and identify patterns or anomalies.
2. Metrics: Metrics are quantitative measurements that provide insights into a Kubernetes environment's performance and resource utilization. They include CPU usage, memory consumption, network traffic, and request latency information. Monitoring and analyzing metrics help identify performance bottlenecks, plan capacity, and optimize resource allocation.
3. Traces: Traces enable end-to-end visibility into the flow of requests across microservices within a Kubernetes application. Distributed tracing captures timing data and dependencies between different components, providing a comprehensive understanding of request paths. Traces help identify latency issues, understand system dependencies, and optimize critical paths for improved application performance.
Kubernetes observability processes typically involve collecting and analyzing data from various sources to understand the system's internal state and provide actionable intelligence. By implementing the right observability strategies, you can gain a deep understanding of your applications and infrastructure, which will help you to:
- Detect and troubleshoot problems quickly
- Improve performance and reliability
- Optimize resource usage
- Meet compliance requirements
Observability processes are being adopted at a rapid pace by IT teams. By 2026, 70% of organizations will have successfully applied observability to achieve shorter latency for decision-making while increasing distributed, organized, and simplified data management processes.
1. Use Centralized Logging and Log Aggregation
For gaining insights into distributed systems, centralized logging is an essential strategy. In Kubernetes environments, where applications span multiple containers and nodes, collecting and analyzing logs from various sources becomes crucial.
Centralized logging involves consolidating logs from different components into a single, easily accessible location. The importance of centralized logging lies in its ability to provide a holistic view of your system's behavior and performance.
With Kubernetes logging, you can correlate events and identify patterns across your Kubernetes cluster, enabling efficient troubleshooting and root-cause analysis.
To implement centralized logging in Kubernetes, you can leverage robust log aggregation tools or cloud-native solutions like Amazon CloudWatch Logs or Google Cloud Logging. These tools provide scalable and efficient ways to collect, store, and analyze logs from your Kubernetes cluster.
2. Leverage Distributed Tracing for End-to-End Visibility
In a complex Kubernetes environment with microservices distributed across multiple containers and nodes, understanding the flow of requests and interactions between different components becomes challenging. This is where distributed tracing comes into play, providing end-to-end visibility into the execution path of requests as they traverse through various services.
Distributed tracing allows you to trace a request's journey from its entry point to all the microservices it touches, capturing valuable information about each step. By instrumenting your applications with tracing libraries or agents, you can generate trace data that reveals each service's duration, latency, and potential bottlenecks.
The benefits of leveraging distributed tracing in Kubernetes are significant.
Firstly, it helps you understand the dependencies and relationships between services, enabling better troubleshooting and performance optimization. When a request experiences latency or errors, you can quickly identify the service or component responsible and take corrective actions.
Secondly, distributed tracing allows you to measure and monitor the performance of individual services and their interactions.
By analyzing trace data, you can identify performance bottlenecks, detect inefficient resource usage, and optimize the overall responsiveness of your system. This information is invaluable with regard to capacity planning and ensuring scalability in your Kubernetes environment.
Several popular distributed tracing solutions are available. These tools provide the necessary instrumentation and infrastructure to effectively collect and visualize trace data. By integrating these solutions into your Kubernetes deployments, you can gain comprehensive visibility into the behavior of your microservices and drive continuous improvement.
3. Integrate Kubernetes With APM Solutions
To achieve comprehensive observability in Kubernetes, it is essential to integrate your environment with Application Performance Monitoring (APM) solutions. APM solutions provide advanced monitoring capabilities beyond traditional metrics and logs, offering insights into the performance and behavior of individual application components.
One of the primary benefits of APM integration is the ability to detect and diagnose performance bottlenecks within your Kubernetes applications.
With APM solutions, you can trace requests as they traverse through various services and identify areas of high latency or resource contention. Armed with this information, you can take targeted actions to optimize critical paths and improve overall application performance.
Many APM solutions offer dedicated Kubernetes integrations that streamline the monitoring and management of containerized applications. These integrations provide pre-configured dashboards, alerts, and instrumentation libraries that simplify capturing and analyzing APM data within your Kubernetes environment.
4. Use Metrics-Based Monitoring
Metrics-based monitoring forms the foundation of observability in Kubernetes. It involves collecting and analyzing key metrics that provide insights into your Kubernetes clusters and applications' health, performance, and resource utilization.
When it comes to metrics-based monitoring in Kubernetes, there are several essential components to consider:
- Node-Level Metrics: Monitoring the resource utilization of individual nodes in your Kubernetes cluster is crucial for capacity planning and infrastructure optimization. Metrics such as CPU usage, memory usage, disk I/O, and network bandwidth help you identify potential resource bottlenecks and ensure optimal allocation.
- Pod-Level Metrics: Pods are the basic units of deployment in Kubernetes. Monitoring metrics related to pods allows you to assess their resource consumption, health, and overall performance. Key pod-level metrics include CPU and memory usage, network throughput, and request success rates.
- Container-Level Metrics: Containers within pods encapsulate individual application components. Monitoring container-level metrics helps you understand the resource consumption and behavior of specific application services or processes. Metrics such as CPU usage, memory usage, and file system utilization offer insights into container performance.
- Application-Specific Metrics: Depending on your application's requirements, you may need to monitor custom metrics specific to your business logic or domain. These metrics could include transaction rates, error rates, cache hit ratios, or other relevant performance indicators.
5. Use Custom Kubernetes Events for Enhanced Observability
Custom events communicate between Kubernetes components and between Kubernetes and external systems. They can signal important events, such as deployments, scaling operations, configuration changes, or even application-specific events within your containers.
By leveraging custom events, you can achieve several benefits in terms of observability:
- Proactive Monitoring: Custom events allow you to define and monitor specific conditions that require attention. For example, you can create events to indicate when resources are running low, when pods experience failures, or when specific thresholds are exceeded. By capturing these events, you can proactively detect and address issues before they escalate.
- Contextual Information: Custom events can include additional contextual information that helps troubleshoot and analyze root causes. You can attach relevant details, such as error messages, timestamps, affected resources, or any other metadata that provides insights into the event's significance. This additional context aids in understanding and resolving issues more effectively.
- Integration with External Systems: Kubernetes custom events can be consumed by external systems, such as monitoring platforms or incident management tools. Integrating these systems allows you to trigger automated responses or notifications based on specific events. This streamlines incident response processes and ensures the timely resolution of critical issues.
To leverage custom Kubernetes events, you can use Kubernetes event hooks, custom controllers, or even develop your event-driven applications using the Kubernetes API.
By defining event triggers, capturing relevant information, and reacting to events, you can establish a robust observability framework that complements traditional monitoring approaches.
6. Incorporating Synthetic Monitoring for Proactive Observability
Synthetic monitoring simulates user journeys or specific transactions that represent everyday interactions with your application. These synthetic tests can be scheduled to run regularly from various geographic locations, mimicking user behavior and measuring key performance indicators.
There are several key benefits to incorporating synthetic monitoring in your Kubernetes environment:
- Proactive Issue Detection: Synthetic tests allow you to detect issues before real users are affected. By regularly simulating user interactions, you can identify performance degradations, errors, or unresponsive components. This early detection enables you to address issues proactively and maintain high application availability.
- Performance Benchmarking: Synthetic monitoring provides a baseline for performance benchmarking and SLA compliance. You can measure response times, latency, and availability under normal conditions by running consistent tests from different locations. These benchmarks serve as a reference for detecting anomalies and ensuring optimal performance.
- Geographic Insights: Synthetic tests can be configured to run from different geographic locations, providing insights into the performance of your application from various regions. This helps identify latency issues or regional disparities that may impact user experience. By optimizing your application's performance based on these insights, you can ensure a consistent user experience globally.
You can leverage specialized tools to incorporate synthetic monitoring into your Kubernetes environment. These tools offer capabilities for creating and scheduling synthetic tests, monitoring performance metrics, and generating reports.
An approach for gaining Kubernetes observability for traditional and microservice-based applications is by using third-party tools like Datadog, Splunk, Middleware, and Dynatrace. This tool captures metrics and events, providing several out-of-the-box reports, charts, and alerts to save time.
Wrapping Up
This blog explored six practical strategies for achieving Kubernetes observability in hybrid cloud environments.
By utilizing centralized logging and log aggregation, leveraging distributed tracing, integrating Kubernetes with APM solutions, adopting metrics-based monitoring, incorporating custom Kubernetes events, and synthetic monitoring, you can enhance your understanding of the behavior and performance of your Kubernetes deployments.
Implementing these strategies will provide comprehensive insights into your distributed systems, enabling efficient troubleshooting, performance optimization, proactive issue detection, and improved user experience.
Whether you are operating a small-scale Kubernetes environment or managing a complex hybrid cloud deployment, applying these strategies will contribute to the success and reliability of your applications.
Opinions expressed by DZone contributors are their own.
Comments