Apache Kafka Is NOT Real Real-Time Data Streaming!
Learn how Apache Kafka enables low latency real-time use cases in milliseconds, but not in microseconds; learn from stock exchange use cases at NASDAQ.
Join the DZone community and get the full member experience.
Join For FreeReal-time data beats slow data. It is that easy! But what is real-time? The term always needs to be defined when discussing a use case. Apache Kafka is the de facto standard for real-time data streaming. Kafka is good enough for almost all real-time scenarios. But dedicated proprietary software is required for niche use cases. Kafka is NOT the right choice if you need microsecond latency! This article explores the architecture of NASDAQ that combines critical stock exchange trading with low-latency streaming analytics.

What Is Real-Time Data Streaming?
Apache Kafka is the de facto standard for data streaming. However, every business has a different understanding of real-time data. And Kafka cannot solve every real-time problem.
Hard real-time is a deterministic network with zero spikes and zero latency, which is a requirement for embedded systems using programming languages like C, C++, or Rust to implement safety-critical software like flight control systems or collaborative robots (cobots). Apache Kafka is not the right technology for safety-critical latency requirements.
Soft real-time is data processing in a non-deterministic network with potential latency spikes. Data is processed in near real-time. That can be microseconds, milliseconds, seconds, or slower.
Real-Time Categories for Data Streaming With Apache Kafka
I typically see three kinds of real-time use cases. But even here, Apache Kafka does not fit into each category:
- Critical real-time: Limited set of use cases that require data processing in microseconds.
- Famous use case:
- Trading markets in financial services. This is NOT Kafka.
- Famous use case:
- Low-latency real-time: Fast data processing is required in tens or hundreds of milliseconds to enable specific use cases.
- Examples:
- Sensor analytics in manufacturing, end-to-end data correlation in ride-hailing between mobile apps and backends, and fraud detection in instant payments. This is Kafka.
- Examples:
- Near real-time: Fast data processing improves the business process but is not mandatory.
- For instance:
- Data ingestion (streaming ETL) into a data warehouse is better in seconds than a batch process that runs every night. This is Kafka.
- For instance:
Note: this article focuses on Apache Kafka as it is the de facto standard for data streaming. However, the same is true for many complementary or competitive technologies, like Spark Streaming, Apache Flink, Apache Pulsar, or Redpanda.
Let’s look at a concrete example of the financial services industry.
NASDAQ Market Feeds vs. Real-Time Data
Ruchir Vani, the Director of Software Engineering at Nasdaq, presented at the “Current 2022—the Next Generation of Kafka Summit” in Austin, Texas: Improving the Reliability of Market Data Subscription Feeds.
The Nasdaq Stock Market (National Association of Securities Dealers Automated Quotations Stock Market) is an American stock exchange based in New York City. It is ranked second on the list of stock exchanges by market capitalization of shares traded, behind the New York Stock Exchange. The exchange platform is owned by Nasdaq, Inc. While most people only know the stock exchange, it is just the tip of the iceberg.

Nasdaq Cloud Data Service Powered by Apache Kafka
The Nasdaq Cloud Data Service has democratized access to financial data for companies, researchers, and educators. These downstream consumers have different requirements and SLAs.
The core engine for processing the market data feeds requires sub-15 microsecond latency. This is NOT Kafka but dedicated (expensive) proprietary software. Consumers need to be co-located and use optimized applications to leverage data at that speed.
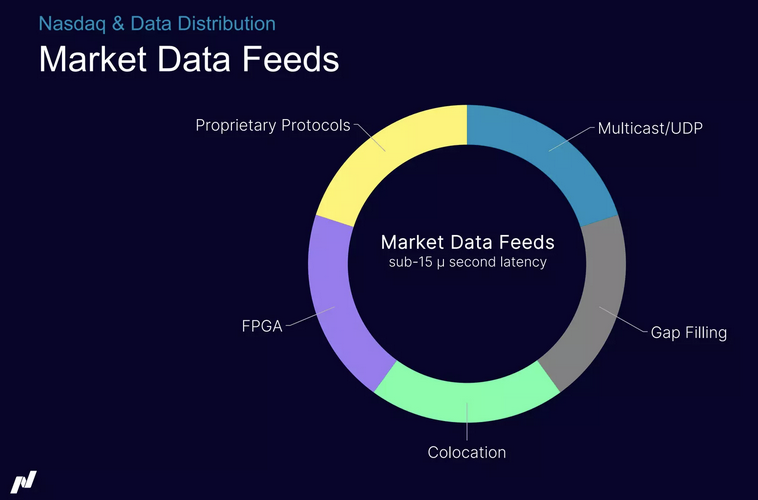
NASDAQ, Inc. wanted to capture more market share by providing additional services on top of the critical market feed. They built a service on top called Nasdaq Data Link Streaming. Kafka powers this:
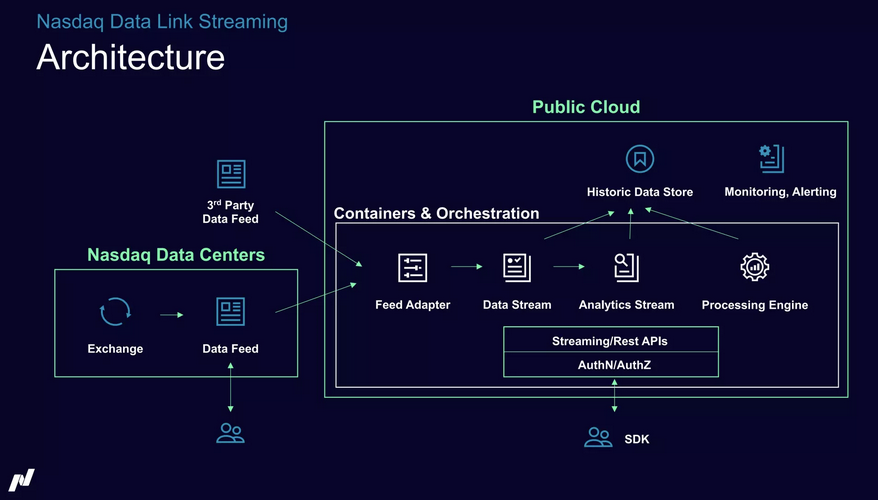
The following architecture shows the combination. Critical real-time workloads run in the Nasdaq Data Centers. The data feeds are replicated to the public cloud for further processing and analytics. Market traders need to co-locate with the critical real-time engine. Other internal and external subscribers (like research and education consumers) consume from the cloud with low latency, in near real-time, or even in batches from the historical data store:
Real Real-Time Is Proprietary (Expensive) Technology and Rarely Needed
Real-time data beats slow data. Apache Kafka and similar technologies, like Apache Flink, Spark Streaming, Apache Pulsar, Redpanda, Amazon Kinesis, Google Pub Sub, RabbitMQ, and so on, enable low latency real-time messaging or data streaming.
Apache Kafka became the de facto standard for data streaming because Kafka is good enough for almost all use cases. Most use cases do not even care if end-to-end processing takes 10ms, 100ms, or 500ms (as downstream applications are not built for that speed anyway). Niche scenarios require dedicated technology. Kafka is NOT the right choice if you need microsecond latency! The NASDAQ example showed how critical proprietary technology and low-latency data streaming work very well together.
If you want to see more use cases, read my article about low-latency data streaming with Apache Kafka and cloud-native 5G infrastructure.
What kind of real-time do you need in your projects? When do you need critical real-time? If you “just” need low latency, what use case is Kafka not good enough for?
Published at DZone with permission of Kai Wähner, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments