API Standards Are Data Standards
API standards are often created separately from an org's data standards. However, they are much more similar than many realize and, therefore, should be created together.
Join the DZone community and get the full member experience.
Join For FreeAside from those who have ignored technology trends for the last twenty years, everyone else is aware of — and likely working with — service-based architectures, whether micro, domain-driven, modulith, integration, data, or something else. From service-based, we’ve evolved to API-First, where APIs are first-class deliverables around which all solutions are built: front-end, back-end, mobile, external integrations, whatever. The APIs are intended to be implemented before other development work starts, even if the initial implementation is stubbed out, dummy code that allows other work to begin. API-First revolves around the contract.

We software engineers focus on the way, too many different ways APIs may be implemented, but not our consumers: consumers’ concerns are that the published API contract is fulfilled as defined. Other than innate curiosity, consumers do not care about nor need to know the blood, sweat, and tears you poured into its implementation. Their concerns are fit for purpose and overall correctness.
Organizations often expend considerable effort defining their API standards and applying these standards against their APIs to increase their chances of succeeding in an API-First world. I view API standards as a data contract for the consumer, akin to data standards defined to (hopefully) improve data handling practices within an organization. Yes, API functionality often extends beyond simple CRUD operations and shares many characteristics, but it is created and maintained by different groups within an organization.
What Are Data Standards?
Data standards, also known as data modeling standards, define an organization’s methodology for defining and managing mission-critical data to ensure consistency, understanding, and usability throughout the organization, including such roles as software engineers, data scientists, compliance, business owners, and others.
Each organization has different goals and non-functional requirements important to their business, therefore no universal, all-encompassing standard exists. Methodology changes in the last 2+ decades have empowered software engineering teams to model their data solutions just in time, often with reduced involvement of the de facto data team (if one exists). Regardless, when organizational data standards are created (and enforced), its components often include:
- Naming: The term or vernacular used for consistency and ease of understanding when describing a subject area and its individual data elements, which may be industry standards, business-specific, or generic. Acceptable abbreviations may be part of naming standards. Occasionally, standards define names for internal database elements such as indices, constraints, and sequence generators.
- Data domains: Most data elements are assigned a data domain or class that defines its specific data implementation, for example: an
idis the UUID primary key; acodeis five alphanumeric characters; apercentis a floating point number with a maximum of four decimal points; anamecontains between 5 and 35 alphanumeric characters. - Structure: Determined by backend database — i.e., third-normal form in relational vs. data accessed together is stored together in document-orientedNoSQL — the persisted data can be dramatically different, though localized decisions still exist: business vs. system-generated primary keys; arrays, keys or sets for JSON subdocuments; data partitioning for performance and scaling; changes for development optimization. One solution implemented its own data dictionary on top of a relational database, simplifying customer configurability by sacrificing engineering simplicity.
- Validations: Data checks and verifications beyond what data types or data domains provide, often business- or industry-specific, such as A medical facility composed of one or more buildings, or a registered user must consist of a verified email address, corporate address, and job title. When implemented correctly, data validations improve data quality and increase the value of data to the organizations.
This is not the all-inclusive list, as organizations with more mature data practices often have more components or areas covered. Unfortunately, in my opinion,, current favored methodologies often de-emphasized defining/applying formal data standards during feature development; however, that is a discussion for a different time.
Digging Deeper
It’s easiest to demonstrate the similarities of API and data standards with a real-life example, so let’s use the GitHub endpoint. Create a commit status for demonstration purposes:
Users with push access in a repository can create commit statuses for a given SHA.
Note: there is a limit of 1000 statuses per
shaandcontextwithin a repository. Attempts to create more than 1000 statuses will result in a validation error.Fine-grained access tokens for “Create a commit status”
This endpoint works with the following fine-grained token types:
- GitHub App user access tokens
- GitHub App installation access tokens
- Fine-grained personal access tokens
The fine-grained token must have the following permission set:
URI
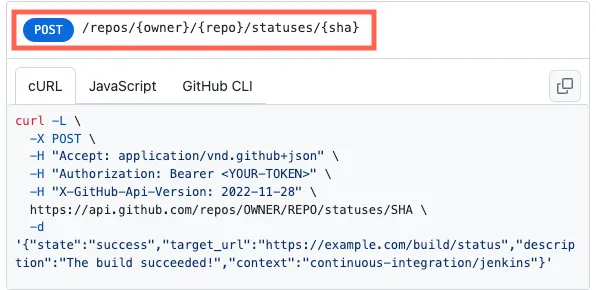
The URI and its pathname contain both terminology (names) and data:
- a
POSTis primarily used when creating data, in our example, attaching (creating) a commit status to an existing commit;; - the standard abbreviation for repository is
repos; reposandstatusesare plural and not singular (often requiring much discussion and consternation};{owner},{repo}, and{sha}are values or path parameters provided by the caller to specify the commit being updated by this call;{owner}and{repo}are defined as case-insensitive.
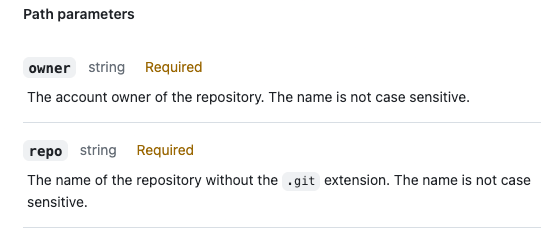
Notice that owners is not explicitly called out, such as hypothetically /owners/{owner}/repos/{repo}/statuses/{sha}. Because a GitHub repository is always identified by its owner and name. GitHub engineers likely concluded that including it was unnecessary, extraneous, or confusing.
Headers
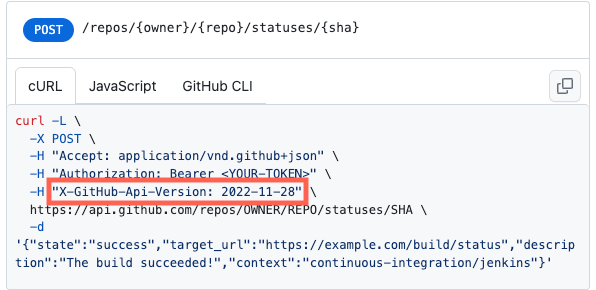
The caller (consumer) declares the API version to use by specifying it in the HTTP header as a date. Alternatively, some API standards specify the version as a sequence number in the URI; presumably, other formats exist, of which I am unaware.
Headers may also include data supporting non-functionality requirements, such as observability.
Request Body
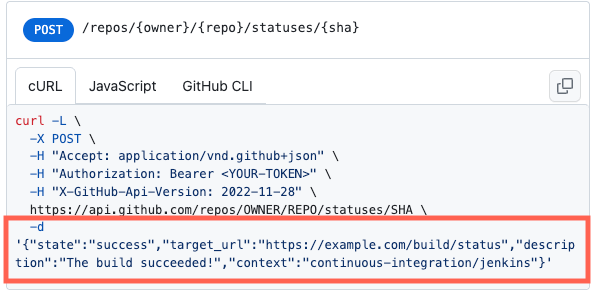
The request body provides the data supporting this API call, in this case, the data required for creating a commit status. Points to make:
- only a top-level JSON document with no subdocuments;
stateis an enumerated value with four valid values;target_urlis suffixed with a data type,_urlimplying a valid URL is expected;descriptionis a short description, though what constitutes short, is unspecified: is it 20, 100, or 1024 characters?
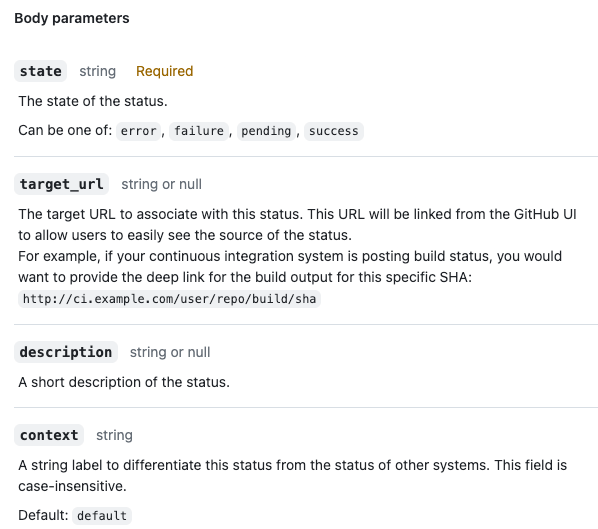
Request bodies are usually provided for HTTP POST, PUT, and PUT calls with an arbitrary size and complexity, based on the call's requirements.
Call Response
All APIs return an HTTP status code, and most return data representing the outcome (DELETE an expected exception). A successful API call for our demonstration purposes would be the created commit status. Unsuccessful API calls (non-2xx) often include error details that assist with debugging.

The response for our API clearly shows the standards being applied:
- consistent
_urldata domain for the various URLs returned by GitHub, i.e.,target_url,avatar_url,followers_url, etc; _iddata domain for unique identifiers, i.e.,node_id,gravatar_id, and standalone_id;creatorsubdocument which is the (complete?) user object;- more plurals:
followers_url,subscriptions_url,organizations_url,received_events_url.
Query Parameters
Our demonstration API does not have supporting query parameters, but APIs retrieving data often require these for filtering, pagination, and ordering purposes.
Final Thoughts
API standards and data standards are more similar, with similar issues and goals than many engineers wish to admit. Organizations would benefit if these standards were aligned for consistency rather than creating each in a vacuum. Though use cases supported by APIs often encompass more than base CRUD operations — and some APIs don’t result in persisted data — the API consumers view the contracts as data-driven. Therefore, applying well-known principles of data standards to your API standards increases the consistency and completeness of the APIs, reduces development time, and reduces errors.
Originally published at https://scottsosna.com/2025/07/07/api-standards-are-data-standards/.
Published at DZone with permission of Scott Sosna. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments