Arrays in JSON: Modeling, Querying and Indexing Performance
Join the DZone community and get the full member experience.
Join For FreeArray is THE difference between the relational model and the JSON model. — Gerald Sangudi
Abstract
JSON array gives you flexibility in the type of elements, number of elements, size of the elements, and the depth of the elements. This adds to the flexibility of operational JSON databases like Couchbase and MongoDB. The performance of queries with an array predicate in operational databases depends on the array indexes. However, the array indexes in these databases come with significant limitations. E.g. only one array key is allowed per index. The array indexes, even when created, can only process AND predicates efficiently. The Couchbase 6.6 release removes these limitations by using a built-in inverted index to be used to index and query arrays in N1QL. This article explains the background and the workings of this novel implementation.
Introduction
An array is a basic type built into JSON defined as An array is an ordered collection of values. An array begins with [left bracket and ends with ]right bracket. Values are separated by ,comma. An array gives you flexibility because it can contain an arbitrary number of scalar, vector, and object values. A user profile can have an array of hobbies, a customer profile an array of cars, a member profile an array of friends. Couchbase N1QL provides a set of operators to manipulate arrays; MongoDB has a list of operators to handle arrays as well.
Before you start querying, you need to model your data in arrays. All JSON document databases like Couchbase, MongoDB recommend you to denormalize your data model to improve your performance and appdev. What that means is, transform your 1:N relationship into a single document by embedded the N into 1. In JSON, you’d do that by using an array. The example below, the document(1) contains 8 (N) likes. Instead of storing a foreign key reference to another table, in JSON, we store data inline.
xxxxxxxxxx
"public_likes": [
"Julius Tromp I",
"Corrine Hilll",
"Jaeden McKenzie",
"Vallie Ryan",
"Brian Kilback",
"Lilian McLaughlin",
"Ms. Moses Feeney",
"Elnora Trantow"
],
Values here are arrays of strings. In JSON, each element can be any valid JSON type: scalars (numeric, string, etc), or objects or vectors (arrays). Each hotel document contains an array of reviews. This is the process of denormalization. Converting multiple 1:N relationships to a single hotel object that contains N public_likes and M reviews. With this, the hotel object embeds two arrays: public_likes and reviews. There can be any number of values of any type under these arrays. This is the key contributing factor to JSON Schema flexibility. When you need to add new likes or reviews, you simply add a new value or an object to this.
xxxxxxxxxx
"reviews": [
{
"author": "Ozella Sipes",
"content": "This was our 2nd trip here...",
"date": "2013-06-22 18:33:50 +0300",
"ratings": {
"Cleanliness": 5,
"Location": 4,
"Overall": 4,
"Rooms": 3,
"Service": 5,
"Value": 4
}
},
{
"author": "Barton Marks",
"content": "We found the hotel ...",
"date": "2015-03-02 19:56:13 +0300",
"ratings": {
"Business service (e.g., internet access)": 4,
"Check in / front desk": 4,
"Cleanliness": 4,
"Location": 4,
"Overall": 4,
"Rooms": 3,
"Service": 3,
"Value": 5
}
}
],
Like the hotel object above, you denormalize your data model into JSON, there could be many arrays for each object. Profiles have arrays for hobbies, cars, credit cards, preferences, etc. each of these can be scalars (simple numeric/string/boolean values) or vectors (arrays of other scalars, arrays of objects, etc).
Once you model and store the data, you need to process it — select, join, project. Couchbase N1QL (SQL for JSON) provides an expressive language to do these and more. Here are common use cases.
xxxxxxxxxx
1. Find all the documents with a simple value can be done by either of the following queries.
SELECT *
FROM `travel-sample`
WHERE type = "hotel"
AND ANY p IN public_likes SATISFIES p = "Vallie Ryan" END
SELECT t
FROM `travel-sample` t
UNNEST t.public_likes AS p
WHERE t.type = "hotel"
AND p = "Vallie Ryan"
xxxxxxxxxx
2. Find all the documents that match a range. In this case, we try to find all the documents that have atleast one rating has “Overall” > 4
SELECT COUNT(1)
FROM `travel-sample`
WHERE type = "hotel"
AND ANY r IN reviews SATISFIES r.ratings.Overall > 4 END
SELECT COUNT(1)
FROM `travel-sample` t
UNNEST reviews AS r
WHERE t.type = "hotel"
AND r.ratings.Overall > 4
GROUP BY t.type
xxxxxxxxxx
3. Find all the documents where every rating for “Overall” > 4
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ AND ANY AND EVERY r in reviews SATISFIES r.Overall > 4 END
SELECT COUNT(1)
FROM `travel-sample`
WHERE type = "hotel"
AND ANY
AND EVERY r IN reviews SATISFIES r.ratings.Overall > 4 END
SELECT reviews[*].ratings[*].Overall
FROM `travel-sample`
WHERE type = "hotel"
AND ANY
AND EVERY r IN reviews SATISFIES r.ratings.Overall > 4 END
limit 10;
[
{
"Overall": [
5
],
"name": "The Bulls Head"
},
{
"Overall": [
5,
5,
5,
5,
5
],
"name": "La Pradella"
},
{
"Overall": [
5,
5,
5
],
"name": "Culloden House Hotel"
},
{
"Overall": [
5
],
"name": "Auberge-Camping Bagatelle"
},
{
"Overall": [
5,
5
],
"name": "Avignon Hotel Monclar"
}
]
Array Indexing:
Indexing arrays are a challenge for B-tree based indexes. However, the JSON database has to do it to meet the performance requirements: MongoDB does it; Couchbase does it. However, both come with limitations. You can only have one array key within an index. This is true of MongoDB; this is true of Couchbase N1QL. The core reason for this limitation is when you index elements of an array, you need separate index entries.
xxxxxxxxxx
Consider the array:
Document key: “bob”
{
“Id”: “bob123”
“A”: [1, 2, 3, 4]
“B”: [521, 4892, 284]
}
Indexing of the field “id” simply requires 1 entry in the index:
“bob123”:bob
Indexing of the field “a” requires 4 entries in the index:
“1”:”bob”, 2:”bob”, 3:”bob”, 4:”bob”
Indexing of the composite index (id, a) requires 4 entries:
“bob123”, 1: bob
“bob123”, 2: bob
“bob123”, 3: bob
“bob123”, 4: bob
Indexing of the composite index (id, a, b) requires the following 12 entries:
“bob123”, 1, 521: bob
“bob123”, 1,4982: bob
“bob123”, 1, 284: bob
“bob123”, 2, 521: bob
“bob123”, 2,4982: bob
“bob123”, 2, 284: bob
“bob123”, 3, 521: bob
“bob123”, 3,4982: bob
“bob123”, 3, 284: bob
“bob123”, 4, 521: bob
“bob123”, 4,4982: bob
“bob123”, 4, 284: bob
The size of the index grows exponentially as the number of array keys in the index and the number of array elements in the index. Hence the limitation. Implications of this limitation are:
- Push only one array predicate to the index scan and handle other predicates after the index scan.
- This means queries with multiple array predicates could be slow
- Avoid composite indexes with array keys to avoid huge indexes.
- This means queries with complex predicates on array keys will be slow
Good news from the LEFT FIELD.
The full-text search index was designed to handle text pattern search based on relevance. The way it does by tokenizing each field. In this example below, each document is analyzed to get tokens:
xxxxxxxxxx
“doc:1”->”desc”: {“desc”: “an appel a day, keeps the doctor away.”}
“doc:2”->”desc”: {“desc”:”an appel a day, keeps Billl Gates away.”}
“doc:3”->”desc”: {“desc”: “an apple a dday, keeps the apple farmer rich.”}
“doc:1”->”desc”: [“apple”, “day”, “keep”, “doctor”, “away”]
“doc:2”->”desc”: [“apple”, “day”, “keep”, “bill”, “gates”, “away”]
“doc:3”->”desc”: [“apple”, “day”, “keep”, “farmer”, “rich”]
This then is combined to get a single array of tokens:
[“apple”, “away”, “bill”, “day”, “doctor”, “farmer”, “gates”, “keep”, “rich”]
For each token, it keeps the list of documents that token is present. This is the inverted tree structure! Unlike a B-Tree based index, it avoids repeating the same token value N number of times, one for each document it’s present in. When you have millions or billions of documents, this is a huge saving.
The second thing to note here is, the inverted index used for an ARRAY OF TOKENS! In fact, the inverted tree structure in the full-text-search is ideal for indexing and searching for array values, especially when these values have duplicates.
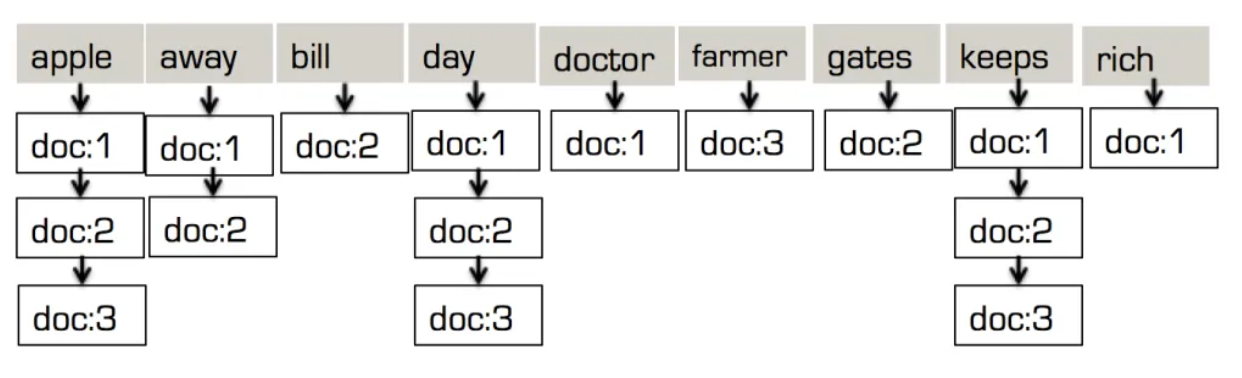
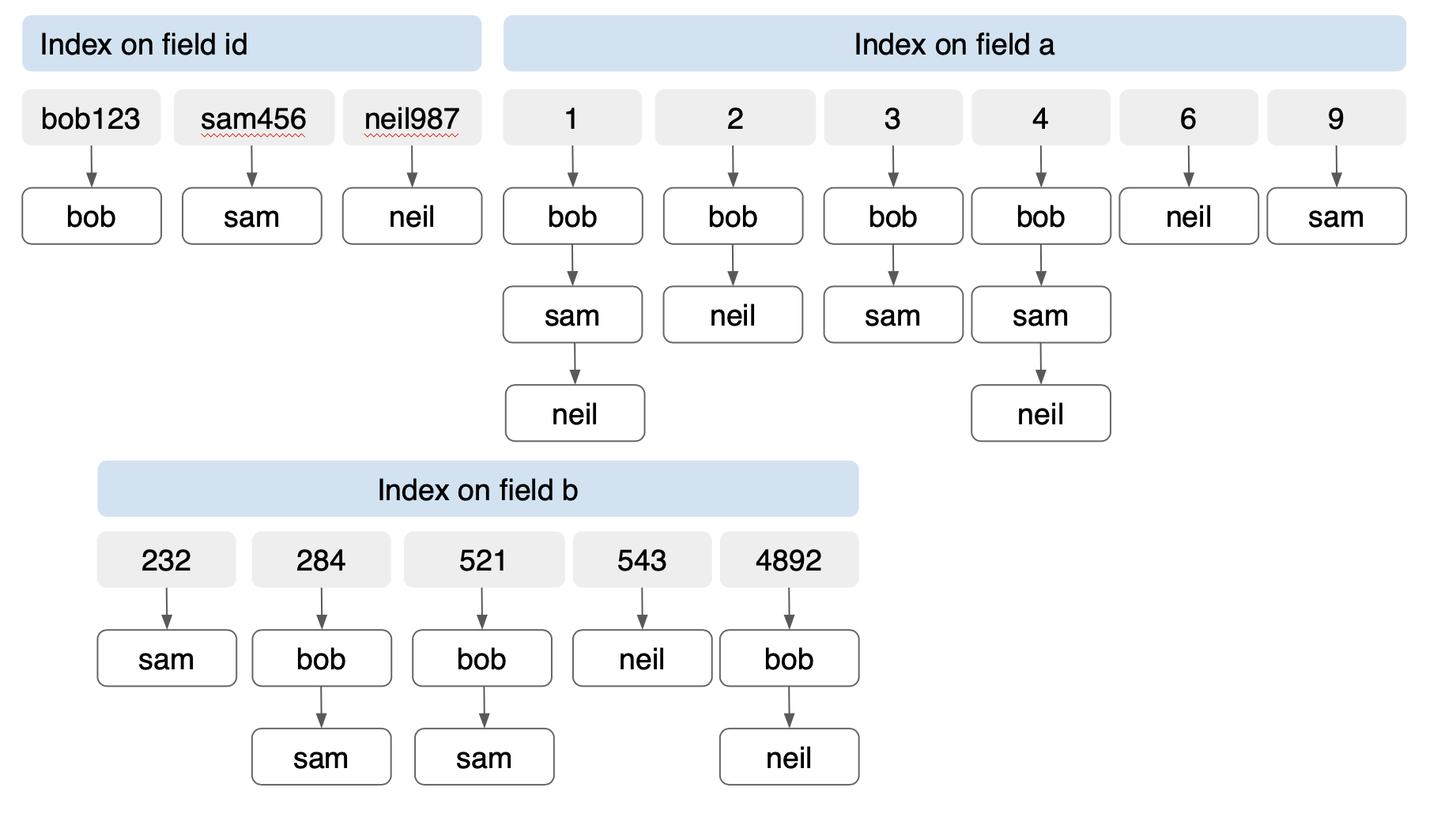
Indexing arrays using the inverted index will be the same process, except there’s no tokenization. Let’s revisit indexing our document “bob”, with additional documents, “Sam” and “Neill”
xxxxxxxxxx
Document key: “bob”
{
id”: “bob123”
“a”: [1, 2, 3, 4]
“b”: [521, 4892, 284]
}
Document key: “sam”
{
“id”: “sam456”
“a”: [1,3, 4, 9]
“b”: [521, 232, 284]
}
Document key: “neil”
{
“id”: “neil987”
“a”[1, 2, 4, 6]
“b”: [521, 4892, 543]
}
The Couchbase FTS has an analyzer called a keyword analyzer. This indexes the values as-is instead of trying to find its root by stemming it. Basically, value is the token. For array value indexing, we can use this index and exploit the efficiencies of an inverted index. Let’s construct an FTS index on the documents bob, sam, neil. In the case of the inverted tree, each field gets its own inverted tree: one each for id, a, and b. Because these are individual trees, they don’t grow exponentially as the B-tree composite index. The number of index entries is proportional to the number of unique items in each field. In this case, we have 14 entries for the 3 documents with three fields of a total of 24 values. Creating a B-tree index on (id, a, b) for the same document will create 36 entries!
Notice that for three documents with two index entries the difference is 157%. As the number of documents, the number of arrays increases, the savings using an inverted index increase as well.
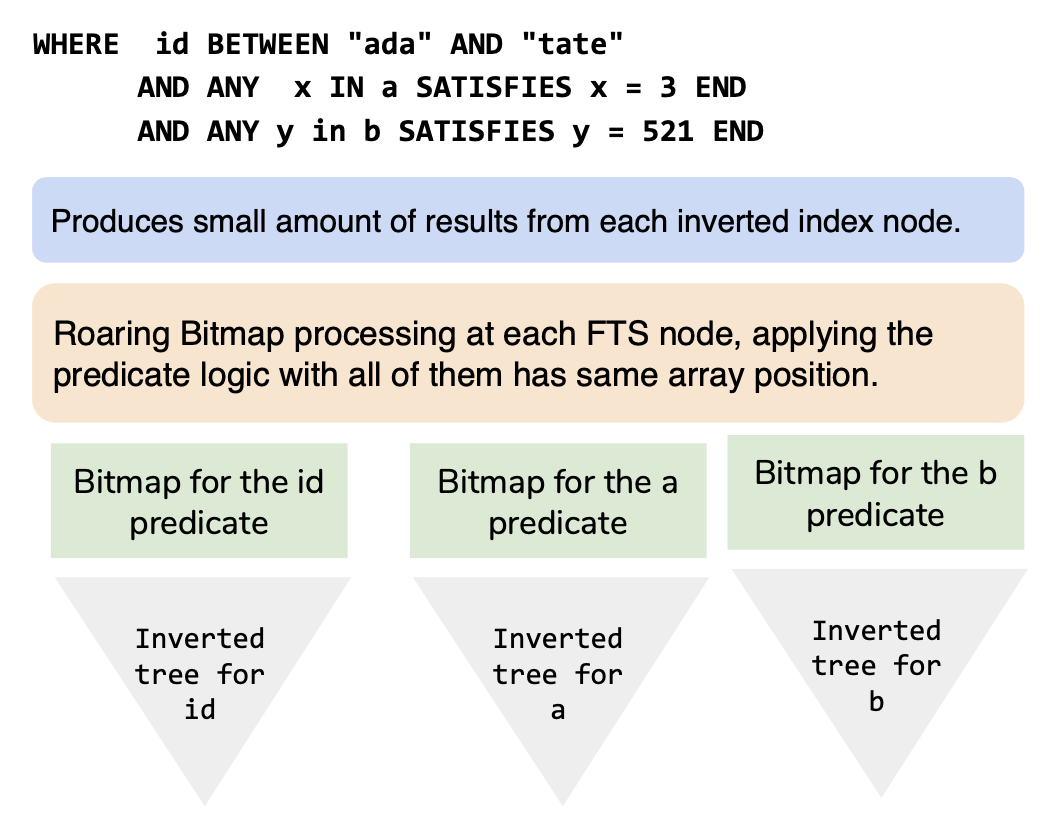
However, we do have an issue. How you process predicates?
xxxxxxxxxx
WHERE id between "ada" and "tate"
AND ANY x IN a SATISFIES x = 3 END
AND ANY y in b SATISFIES y = 521 END
The B-Tree index stores all of the values in (id, a, and b) together, the inverted index in FTS has distinct trees for each field. So, applying multiple predicates is not so easy. This is true for our array processing as well as text processing. It’s common in text processing to ask questions like: search for all Californian residents with skiing as their hobby.
To process this, FTS applies the predicate on each field individually to get the list of document-keys for each predicate. It then applies the boolean predicate AND on top of it. This layer uses the famed roaring bitmap package to create and process the bitmap of document ids to finalize the result. Yes, there is extra processing here compared to a simpler B-TREE based index, but this makes it possible to index many arrays and process the query in a reasonable time.
Inverted Tree: A tree that keeps on giving!
The B-Tree composite index combines the scanning and the AND predicate application. The inverted tree approach separates the two. Index and scanning each field is different from processing the composite predicate. Because of this separation, the bitmap layer can process OR, NOT predicates along with AND predicates. Changing the AND in the previous example to OR is simply an instruction to the bitmap processing on the document qualification and deduplication
xxxxxxxxxx
WHERE id BETWEEN "ada" AND "tate"
OR ANY x IN a SATISFIES x = 3 END
OR ANY y in b SATISFIES y = 521 END
COUCHBASE Release:
Couchbase 6.6 supports using FTS indexes for processing complex array predicates. This improves the TCO of array handling, enables developers and designers to use, index, query arrays as needed without limitations. Look for upcoming announcements, documentation, feature blogs, etc.
References
- Announcing Flex Index with Couchbase
- Working with JSON Arrays in N1QL
- Utilizing Arrays: Modeling, Querying, and Indexing
- Couchbase N1QL Collection Operators
- MongoDB: Query an arrray
- Couchbase FTS
- FREE: Couchbase interactive training
- FTS BLogs: https://blog.couchbase.com/tag/fts/
- Collection operators
- ARRAY indexing
- Making most of your arrays…with N1QL Array Indexing
- Making most of your Arrays.. with Covering Array Indexes and more.
- Couchbase Indexing
- NEST and UNNEST: Normalizing and Denormalizing JSON on the Fly
Opinions expressed by DZone contributors are their own.
Comments