Assigning Pods to Nodes Using Affinity Rules
Affinity and anti-affinity are Kubernetes features to help you manage the schedule of your applications. Explore two scenarios where to use these features.
Join the DZone community and get the full member experience.
Join For FreeThis article describes how to configure your Pods to run in specific nodes based on affinity and anti-affinity rules. Affinity and anti-affinity allow you to inform the Kubernetes Scheduler whether to assign or not assign your Pods, which can help optimize performance, reliability, and compliance.
There are two types of affinity and anti-affinity, as per the Kubernetes documentation:
requiredDuringSchedulingIgnoredDuringExecution: The scheduler can't schedule the Pod unless the rule is met. This functions likenodeSelector, but with a more expressive syntax.preferredDuringSchedulingIgnoredDuringExecution: The scheduler tries to find a node that meets the rule. If a matching node is not available, the scheduler still schedules the Pod.
Let's see a couple of scenarios where you can use this configuration.
Scenario 1: Kafka Cluster With a Pod in a Different K8s Worker Node
In this scenario, I'm running a Kafka cluster with 3 nodes (Pods). For resilience and high availability, I want to have each Kafka node running in a different worker node.
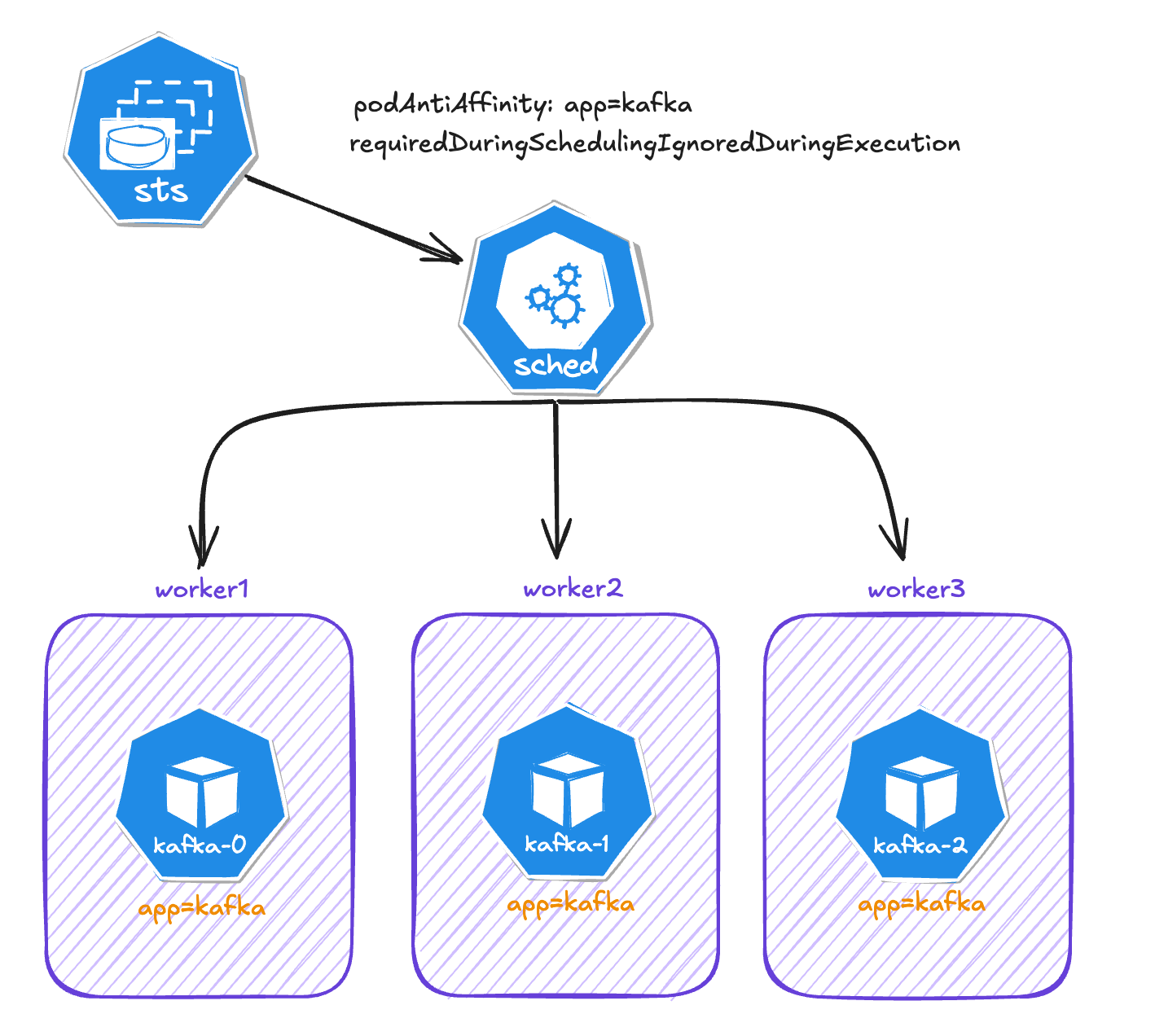
In this case, Kafka is deployed as a StatefulSet, so the affinity is configured in the .template.spec.affinity field:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- kafka
topologyKey: kubernetes.io/hostname
In the configuration above, I'm using podAntiAffinity because it allows us to create rules based on labels on Pods and not only in the node itself. In addition to that, I'm setting the requiredDuringSchedulingIgnoredDuringExecution because I don't want two Kafka Pods running in the same cluster at any time. The labelSelector field look for the label app=kafka in the Pod and topologyKey is the label node. Pod anti-affinity requires nodes to be consistently labeled, in other words, every node in the cluster must have an appropriate label matching topologyKey.
In the event of a failure in one of the workers (considering that we only have three workers), the Kafka Pod will be in a Pending status because the other two nodes already have a Kafka node running.
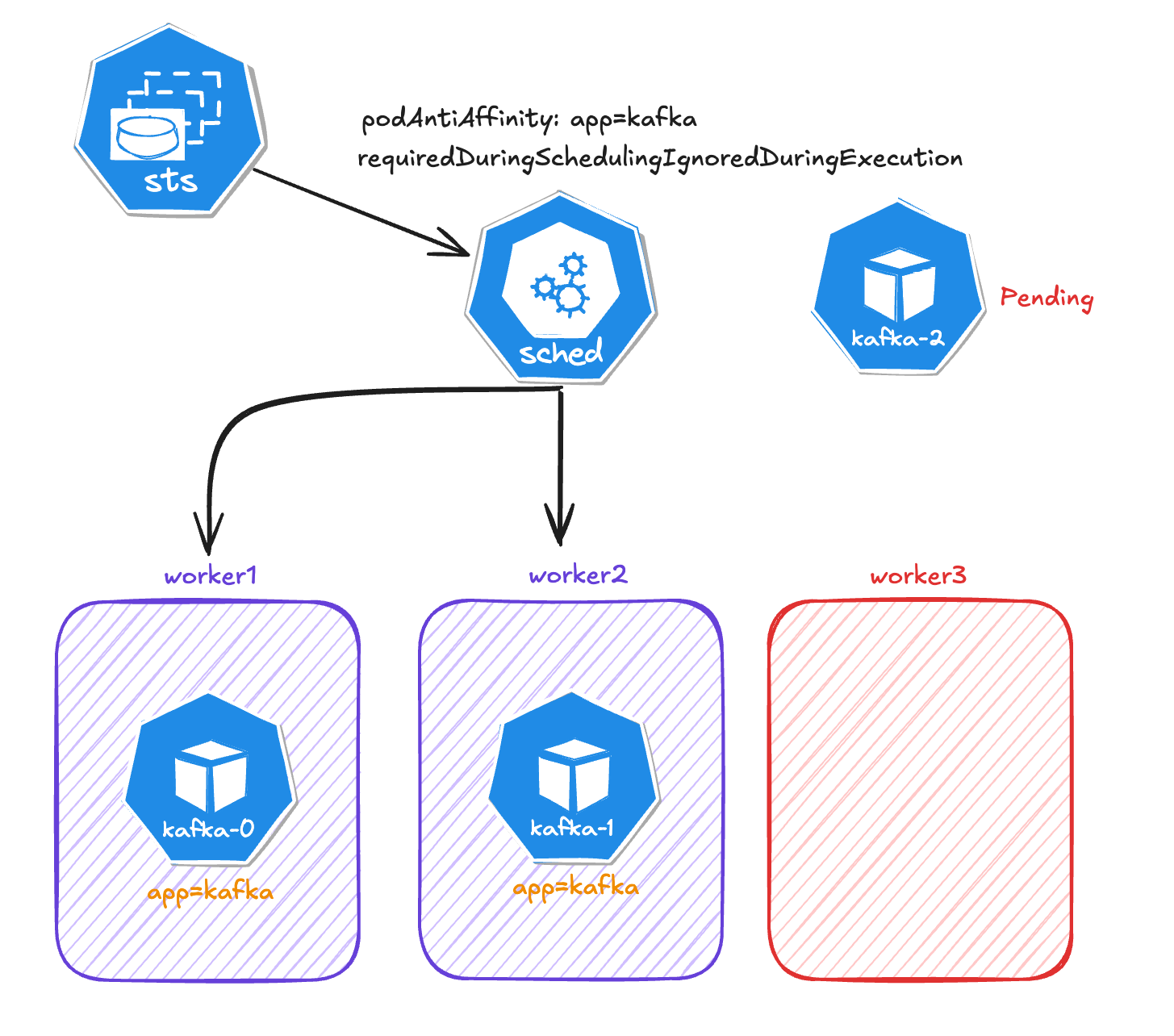
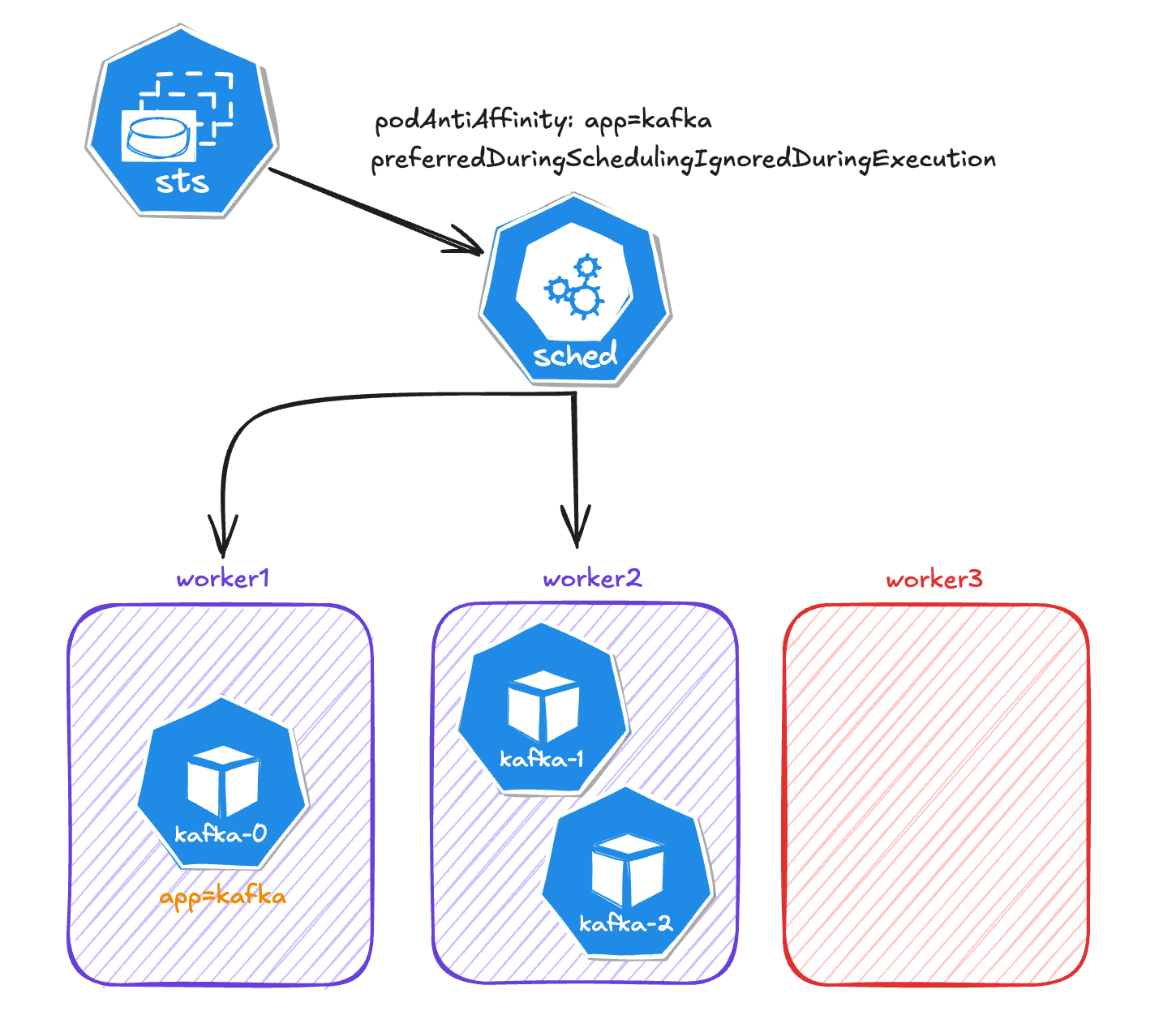
If we change the type from requiredDuringSchedulingIgnoredDuringExecution to preferredDuringSchedulingIgnoredDuringExecution, then kafka-2 would be assigned to another worker.
Scenario 2: Data Science Applications That Must Run on Specific Nodes
Conceptually, node affinity is similar to nodeSelector where you define where a Pod will run. However, affinity gives us more flexibility. Let's say that in our cluster we have two worker nodes with GPU processors and some of our applications must run in one of these nodes.
In the Pod configuration we configure the .spec.affinity field:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: processor
operator: In
values:
- gpu-east1
- gpu-west1
In this example, the following rules apply:
-
The node must have a label with the key processor and the value of that label must be either
gpu-east1orgpu-west1.
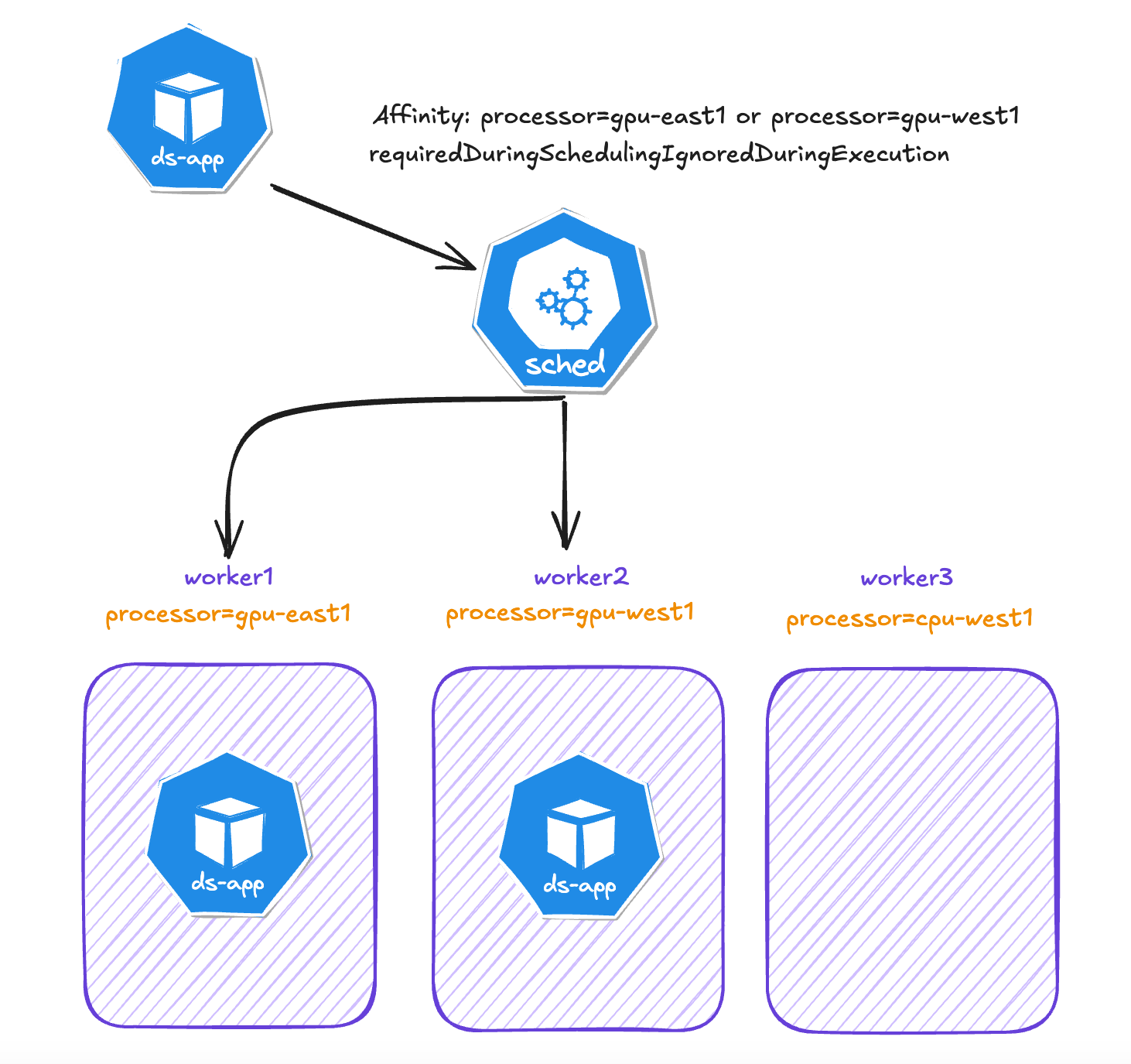
In this scenario, the Data Science applications will be assigned to workers 1 and 2. Worker 3 will never host a Data Science application.
Summary
Affinity and anti-affinity rules provide us flexibility and control on where to run our applications in Kubernetes. It's an important feature to create a highly available and resilient platform. There are more features, like weight, that you can study in the official Kubernetes documentation.
Published at DZone with permission of Rafael Natali. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments