AWS Bedrock Knowledge Bases: Comparing S3 Vector Store, OpenSearch, PostgreSQL, and Neptune for Cost and Performance
In this article, we compare the performance of AWS OpenSearch and S3 Vector Store to find the optimal balance between cost and speed.
Join the DZone community and get the full member experience.
Join For FreeSince July 15, 2025, AWS has added support for S3 vector stores for Bedrock knowledge bases, allowing for seamless storage and retrieval of embeddings for RAG workflows. Currently, it supports multiple stores:
| AWS-Managed | Non AWS-Managed |
|---|---|
| OpenSearch | MongoDB Atlas |
| S3 vector store | Pinecone |
| PostgreSQL | Redis Enterprise Cloud |
| Neptune |
Let's take a deeper look at each of them.
AWS OpenSearch
OpenSearch is a distributed, community-driven, Apache 2.0-licensed, 100% open-source search and analytics suite used for a broad range of use cases, including real-time application monitoring, log analytics, and website search.
OpenSearch provides a highly scalable system for providing fast access and response to large volumes of data with an integrated visualization tool, OpenSearch Dashboards, that makes it easy for users to explore their data. OpenSearch is powered by the Apache Lucene search library, and it supports a number of search and analytics capabilities such as k-nearest neighbors (KNN) search, SQL, anomaly detection, machine learning commons, trace analytics, full-text search, and more.
S3 Vector Store
Amazon S3 Vectors is the first cloud object store with native support to store and query vectors, delivering purpose-built, cost-optimized vector storage for AI agents, AI inference, and semantic search of your content stored in Amazon S3.
By reducing the cost of uploading, storing, and querying vectors by up to 90%, S3 Vectors makes it cost-effective to create and use large vector datasets to improve the memory and context of AI agents and the semantic search results for your S3 data.
AWS Aurora PostgreSQL
Amazon Aurora PostgreSQL is a cloud-based, fully managed relational database service that is compatible with PostgreSQL. It combines the performance and availability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases, specifically PostgreSQL. Essentially, it's a PostgreSQL-compatible database offered as a service by Amazon Web Services
Amazon Neptune
Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets
Non-AWS Managed
MongoDB Atlas
MongoDB Atlas is a multi-cloud database service by the same people that build MongoDB. Atlas simplifies deploying and managing your databases while offering the versatility you need to build resilient and performant global applications on the cloud providers of your choice.
Pinecone
Pinecone is a cloud-based vector database service designed for AI applications, particularly those involving retrieval-augmented generation.
Redis Enterprise Cloud
Redis Enterprise Cloud is a fully managed, on-demand database-as-a-service (DBaaS) offering from Redis, built on the open-source Redis foundation.
Now that all supported stores have been established, I'm going to test and compare only AWS-managed stores. I have created a Python lambda function below.
import json
import time
import boto3
def lambda_handler(event, context):
"""Demo: Bedrock Nova Micro with Knowledge Base timing comparison"""
# Configuration - easily change these for testing
MODEL_ID = "amazon.nova-micro-v1:0"
# Allow override for comparison
KNOWLEDGE_BASE_ID = event.get('kb_id')
# Initialize clients
bedrock_runtime = boto3.client('bedrock-runtime')
bedrock_agent_runtime = boto3.client('bedrock-agent-runtime')
query = event.get(
'query', 'Can you provide a list of bank holidays employers can have?')
start_time = time.time()
try:
# 1. Retrieve from Knowledge Base
kb_start = time.time()
kb_response = bedrock_agent_runtime.retrieve(
knowledgeBaseId=KNOWLEDGE_BASE_ID,
retrievalQuery={'text': query},
retrievalConfiguration={
'vectorSearchConfiguration': {'numberOfResults': 3}}
)
kb_time = time.time() - kb_start
# 2. Build context and prompt
context = "\n".join([r['content']['text']
for r in kb_response.get('retrievalResults', [])])
prompt = f"Context: {context}\n\nQuestion: {query}\n\nAnswer:"
# 3. Call Bedrock model
model_start = time.time()
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig={"maxTokens": 500, "temperature": 0.7}
)
model_time = time.time() - model_start
total_time = time.time() - start_time
answer = response['output']['message']['content'][0]['text']
return {
'statusCode': 200,
'body': json.dumps({
'kb_id': KNOWLEDGE_BASE_ID,
'query': query,
'answer': answer,
'timing_ms': {
'kb_retrieval': round(kb_time * 1000),
'model_inference': round(model_time * 1000),
'total': round(total_time * 1000)
},
'chunks_found': len(kb_response.get('retrievalResults', []))
})
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps({
'error': str(e),
'kb_id': KNOWLEDGE_BASE_ID
})
}This lambda function expects a test event in the following format, where "query" is the actual prompt we want to ask, and kb_id is the knowledge base ID:
{
"query": "Can you provide a list of bank holidays employers can have?",
"kb_id": "AAUAL8BHQV"
}And I have created four different knowledge bases using different data sources:
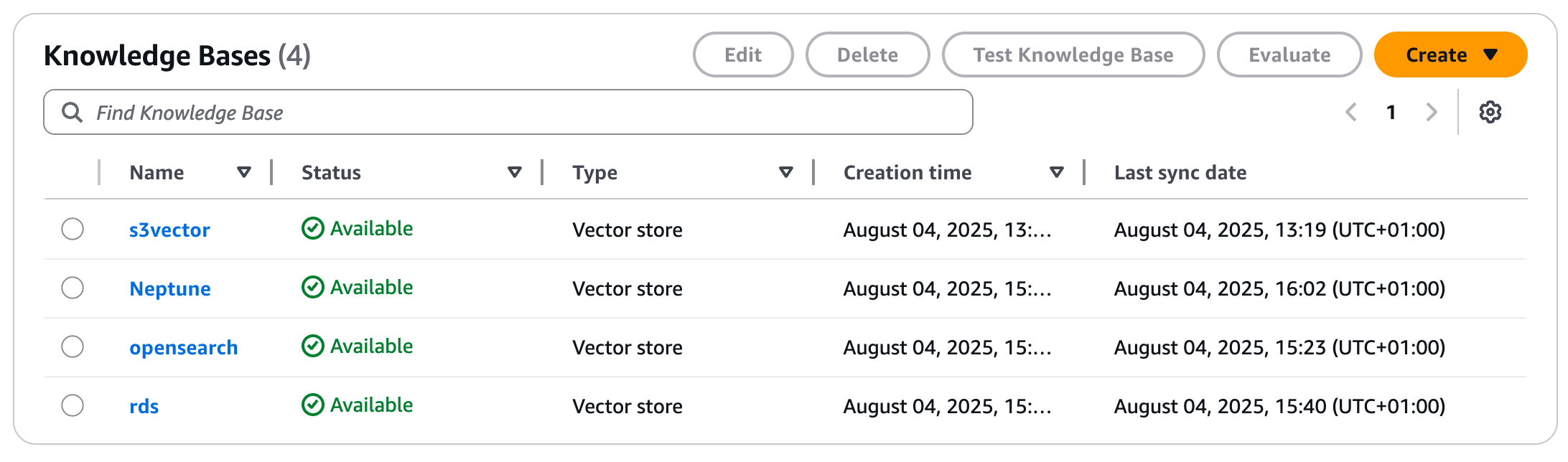
Finally, we have everything we need to make our tests.
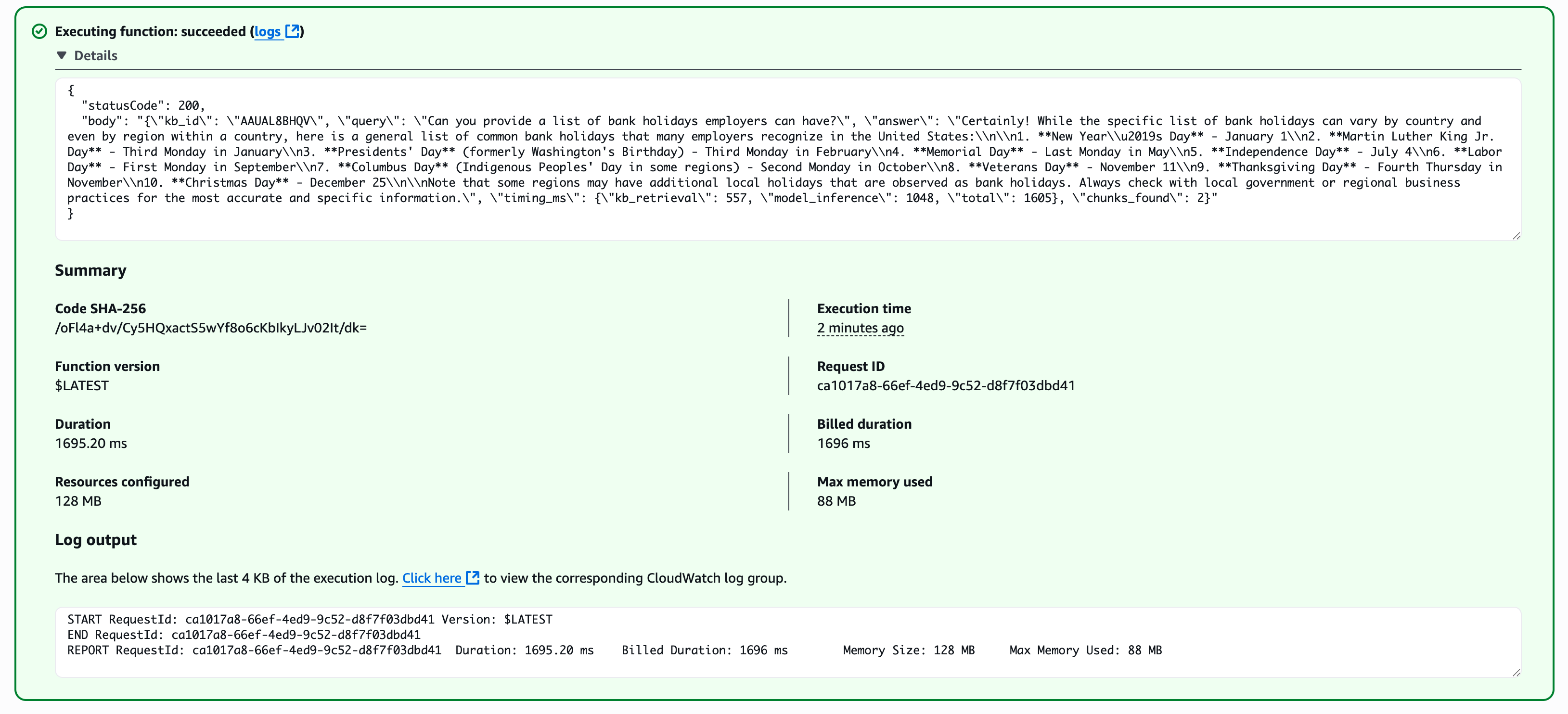
Opensearch:
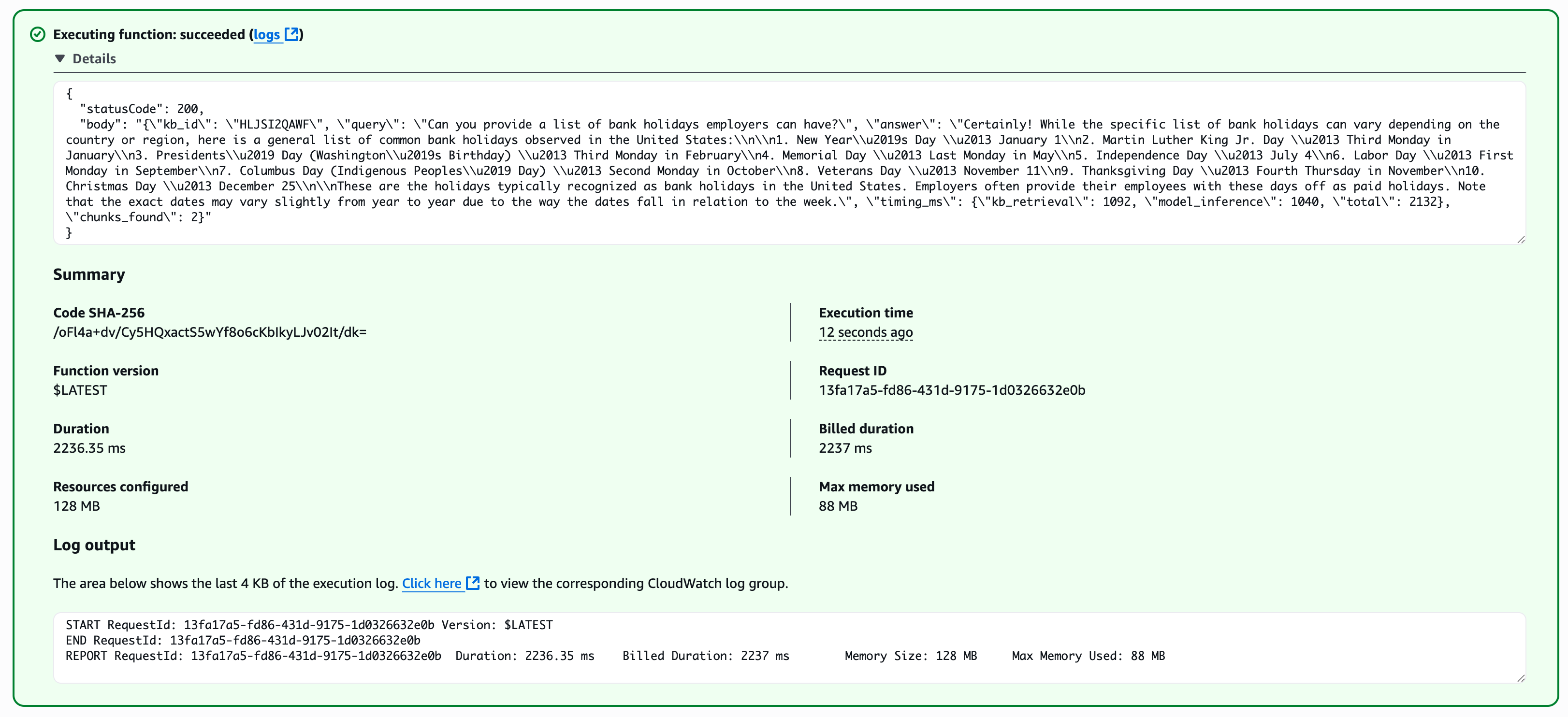
Neptune:
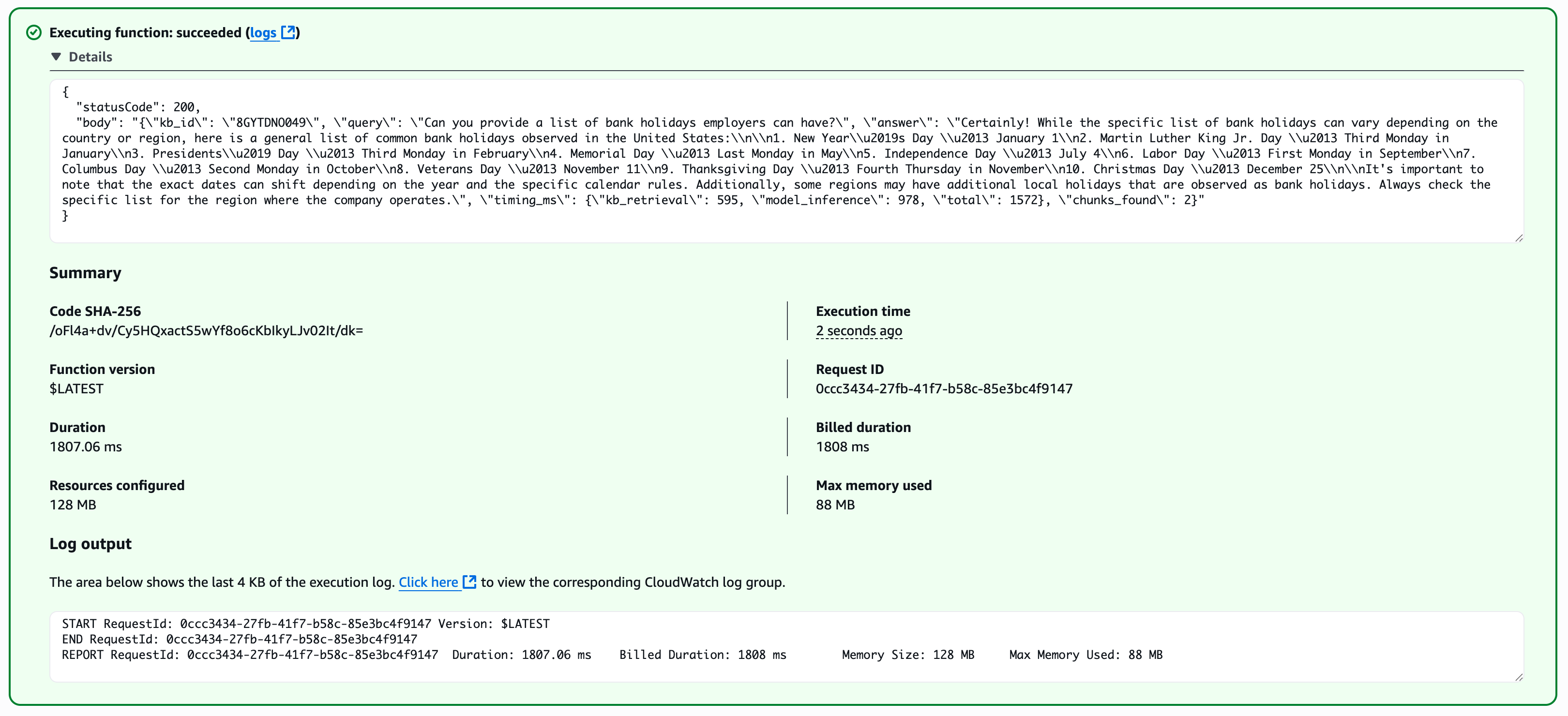
PostgreSQL:
S3 Vector store:
And for better visuality, ordered by execution time:
|
OpenSearch |
1695ms |
|
PostgreSQL |
1807ms |
|
Neptune |
2236ms |
|
S3 vector store |
2284ms |
As you can see here, OpenSearch is the fastest storage. But what about pricing?
OpenSearch — pay as per OCU.
| OpenSearch Compute Unit (OCU) - Indexing | $0.24 per OCU per hour |
| OpenSearch Compute Unit (OCU) - Search and Query | $0.24 per OCU per hour |
The minimum OCU you can pay for is 0.5. It means $0.24 * 24 hours * 30 days * 2 (indexing and search and query) * 0.5 (minimum OCU) = $172.
PostgreSQL — pay per ACU:
| Aurora Capacity Unit (ACU) | $0.12 per ACU per hour |
The minimum ACU you can pay for is 0. But 1 ACU will cost you $0.12 * 24 hours * 30 days = $86
Neptune:
| Memory-optimized Neptune Capacity Units configuration | Pricing |
|---|---|
| 16 m-NCUs | $0.48 per hour |
| 32 m-NCUs | $0.96 per hour |
| 64 m-NCUs | $1.92 per hour |
| 128 m-NCUs | $3.84 per hour |
| 256 m-NCUs | $7.68 per hour |
| 384 m-NCUs | $11.52 per hour |
Minimal instance is $0.48 per hour. It means per month it will cost you $0.48 * 24 hours * 30 days = $345. Wow!
S3 vector store — you will need to pay for requests and storage.
| Item | Price |
|---|---|
| S3 Vector Storage/month — monthly logical storage of vector data, key, and metadata | $0.06 per GB |
S3 Vectors request pricing:
| Request Type | Price |
|---|---|
| PUT requests (per GB)* | $0.20 |
| GET, LIST and all other requests (per 1,000 requests) | $0.055 |
*PUT is subject to a minimum charge of 128KB per PUT. To lower PUT costs, you can batch multiple vectors per PUT request.
S3 Vectors query pricing:
| Request Type | Price |
|---|---|
| S3 Vectors query requests (per 1,000 requests) | $0.0025 |
S3 Vector data — sum of vectors per index multiplied by average vector size (vector data, key, and filterable metadata):
| Number of Vectors | Price per TB |
|---|---|
| First 100 thousand vectors | $0.0040 |
| Over 100 thousand vectors | $0.0020 |
TLDR
S3 Vectors storage charge:
| Calculation Step | Value |
|---|---|
| Logical storage per average vector | (4 bytes * 1024 dimensions) vector data/vector + 1 KB filterable metadata/vector + 1 KB non-filterable metadata/vector + 0.17 KB key/vector = 6.17 KB |
| Total logical storage | 6.17 KB/average vector * 250,000 vectors * 40 vector indexes = 59 GB |
| Total monthly storage cost | 59 GB * $0.06/GB per month = $3.54 |
Final comparison table:
| Vector store type |
Retrieval time |
Approx pricing per month |
|---|---|---|
| S3 vector | 2284 ms | $3.54 |
| Neptune | 2236 ms | $345 |
| PostgreSQL | 1807 ms | $86 |
| OpenSearch | 1695 ms | $172 |
If speed is not so critical, I'd choose the S3 vector store. It's the obvious winner; otherwise, OpenSearch would probably be the better choice.
Opinions expressed by DZone contributors are their own.
Comments