AWS CDK: Infrastructure as Abstract Data Types
Begin a series examining CDK as a high-level object-oriented abstraction, defining cloud infrastructure by leveraging the power of programming languages.
Join the DZone community and get the full member experience.
Join For FreeInfrastructure as Code (IaC), as the name implies, is a practice that consists of defining infrastructure elements with code. This is opposed to doing it through a GUI (Graphical User Interface) like, for example, the AWS Console. The idea is that in order to be deterministic and repeatable, the cloud infrastructure must be captured in an abstract description based on models expressed in programming languages to allow the automation of the operations that otherwise should be performed manually.
AWS makes several IaC tools available, as follows:
- CloudFormation: A provisioning tool able to create and manage cloud resources, based on templates expressed in JSON or YAML notation
- AWS Amplify: An open-source framework that provides developers with anything they need to deliver applications connecting AWS infrastructure elements, together with web and mobile components
- AWS SAM (Serverless Application Model): A tool that facilitates the integration of AWS Lambda functions with services like API Gateway, REST API, AWS SNS/SMQ, DynamoDB, etc.
- AWS SDK (Software Development Kit): An API that provides management support to all AWS services using programming languages like Java, Python, TypeScript, and others
- AWS CDK (Cloud Development Kit): This is another API like the SDK but more furnished, allowing not only management of AWS services, but also to programmatically create, modify, and remove CloudFormation stacks, containing infrastructure elements. It supports many programming languages, including but not limited to Java, Python, TypeScript, etc.
Other non-Amazon IaC tools exist, like Pulumi and Terraform, and they provide very interesting multi-cloud support, including but not limited to AWS. For example, exactly like AWS CDK, Pulumi lets you define cloud infrastructure using common programming languages and, like CloudFormation, Terraform uses a dedicated declarative notation, called HCL (HashiCorp Configuration Language).
This post is the first part of a series that aims to examine CDK in-depth as a high-level object-oriented abstraction to define cloud infrastructure by leveraging the power of programming languages.
Introduction to AWS CDK
In AWS's own definition, CDK is an open-source software development framework that defines AWS cloud resources using common programming languages. Here, we'll be using Java.
It's interesting to observe from the beginning that as opposed to other IaC tools like CloudFormation or Terraform, the CDK isn't defined as being just an infrastructure provisioning framework. As a matter of fact, in AWS meaning of the term, the CDK is more than that: an extremely versatile IaC framework that unleashes the power of programming languages and compilers to manage highly complex AWS cloud infrastructure with code that is, compared to HCL or any other JSON/YAML based notation, much more readable and extensible. As opposed to these other IaC tools, with the CDK one can loop, map, reference, write conditions, use helper functions, in a word, take full advantage of the programming languages power.
But perhaps the most important advantage of the CDK is its Domain Specific Language (DSL)-like style, thanks to the extensive implementation of the builder design pattern that allows the developer to easily interact with the AWS services without having to learn convoluted APIs and other cloud provisioning syntaxes. Additionally, it makes possible powerful management and customizations of reusable components, security groups, certificates, load balancers, VPCs (Virtual Private Cloud), and others.
The CDK is based on the concept on Construct as its basic building block. This is a powerful notion that allows us to abstract away details of common cloud infrastructure patterns. A construct corresponds to one or more synthesized resources, which could be a small CloudFormation stack containing just an S3 bucket, or a large one containing a set of EC2 machines with the associated AWS Sytem Manager parameter store configuration, security groups, certificates, and load balancers. It may be initialized and reused as many times as required.
The Stack is a logical group of Construct objects. It can be viewed as a chart of the components to be deployed. It produces a declarative CloudFormation template, a Terraform configuration, or a Kubernetes manifest file.
Last but not least, the App is a CDK concept which corresponds to a tree of Construct objects. There is a root Appwhich may contain one or more Stack objects, containing in turn one or more Construct objects, that might encompass other Construct objects, etc. The figure below depicts this structure.
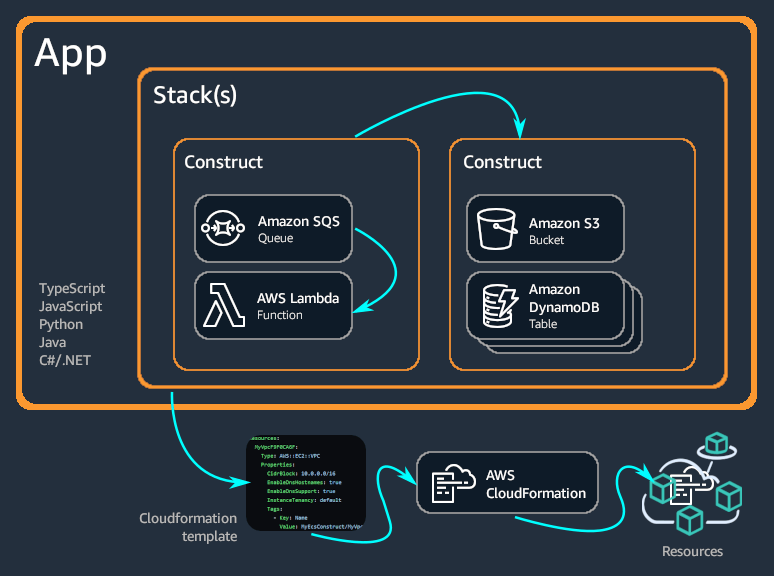
There are several examples here accompanying this post and illustrating it. They go from the most simple ones, creating a basic infrastructure, to the most complex ones, dealing with multi-region database clusters and bastion hosts. Let's look at some of them.
A CDK Starter
Let's begin with a starter project and build a CDK application that creates a simple stack containing only an S3 bucket. Installing the CDK is straightforward, as explained here. Once the CDK is installed and bootstrapped according to the above document, you may use its scaffolding functions in order to quickly create a project skeleton. Run the following command:
$ cdk init app --language javaA bunch of text will be displayed while the CDK scaffolder generates your Maven project and, once finished, you may examine its structure as shown below:
$ tree -I target
.
├── cdk.json
├── pom.xml
├── README.md
└── src
├── main
│ └── java
│ └── com
│ └── myorg
│ ├── TestApp.java
│ └── TestStack.java
└── test
└── java
└── com
└── myorg
└── TestTest.java
9 directories, 6 files
This is your project skeleton created by the CDK scaffold. As you can see, there are a couple of Java classes, as well as a test one. They aren't very interesting and you can already remove them, together with the package com.myorg which won't probably fit your naming convention. But the real advantage of using the CDK scaffolding function is the generation of the pom.xml and cdk.json files.
The first one drives your application build process and defines the required dependencies and plugins. Open it and you'll see:
...
<dependency>
<groupId>software.amazon.awscdk</groupId>
<artifactId>aws-cdk-lib</artifactId>
</dependency>
...
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<configuration>
<mainClass>fr.simplex_software.aws.iac.cdk.starter.CdkStarterApp</mainClass>
</configuration>
</plugin>
...In order to develop CDK applications, you need the aws-cdk-lib Maven artifact. This is the CDK library containing all the required resources. The exec-maven-plugin is also required in order to run your application, once built and deployed.
If you look in the cdk.json file that the cdk init command has generated for you, you'll see this:
...
"app": "mvn -e -q compile exec:java"
...
This is the command that the CDK will use in order to build your application. Of course, you don't have to use the scaffolding function if you don't want to and, if you prefer to start from scratch, you can provide your own pom.xml since, after all, as a developer, you must be used to it. However, when it comes to the cdk.jsonfile, you better should get it generated.
So, fine: you just got your project skeleton, and now you need to customize it to adapt it to your needs. Have a look at the cdk-starter project in the code repository. As you can see, there are two Java classes, CdkStarterApp and CdkStarterStack. The first one creates a CDK application by instantiating the software.amazon.awscdk.App class which abstracts the most basic CDK concept: the application. It's a recommended practice to tag the application, once instantiated, such that different automatic tools are able to manipulate it, according to different purposes. For example, we can imagine an automatic tool that removes all the test applications and, to do that, scans them looking for the tag environment:development.
The goal of an application is to define at least one stack and this is what our application does by instantiating the CdkStarterStack class. This class is a stack as it extends the software.amazon.awscdk.Stack one. And that's in its constructor that we'll be creating an S3 bucket, as shown by the code snippet below:
Bucket bucket = Bucket.Builder.create(this, "my-bucket-id")
.bucketName("my-bucket-" + System.getenv("CDK_DEFAULT_ACCOUNT"))
.autoDeleteObjects(true).removalPolicy(RemovalPolicy.DESTROY).build();Here we created an S3 bucket having the ID of my-bucket-id and the name of my-bucket to which we've appended the current user's default account ID. The reason is that the S3 bucket names must be unique worldwide.
As you can see, the class software.amazon.awscdk.services.s3.Bucket used here to abstract the Amazon Simple Storage Service implements the design pattern builder which allows to define, in a DSL-like manner, properties like the bucket name, the auto-delete, and the removal policy, etc.
So this is our first simple CDK application. The following line in the CdkStarterApp class:
app.synth();... is absolutely essential because it produces ("synthesizes," in the CDK parlance) the associated AWS CloudFormation stack template. Once "synthesized," it may be deployed and used. So here is how:
$ git clone https://github.com/nicolasduminil/cdk.git
$ cd cdk/cdk-starter
$ mvn package
$ cdk deploy --requireApproval=neverA bunch of text will be again displayed and, after a while, if everything is okay, you should see a confirmation of your stack's successful deployment. Now, in order to check that everything worked as expected, you can the list of your deployed stack as follows:
$ aws cloudformation list-stacks --stack-status-filter CREATE_COMPLETEIt is critical to filter the output list of the existent stack by their current status (in this case CREATE_COMPLETE), such that to avoid retrieving dozens of irrelevant information. So, you should see something like:
{
"StackSummaries": [
...
{
"StackId": "arn:aws:cloudformation:eu-west-3:...:stack/CdkStarterStack/83ceb390-3232-11ef-960b-0aa19373e2a7",
"StackName": "CdkStarterStack",
"CreationTime": "2024-06-24T14:03:21.519000+00:00",
"LastUpdatedTime": "2024-06-24T14:03:27.020000+00:00",
"StackStatus": "CREATE_COMPLETE",
"DriftInformation": {
"StackDriftStatus": "NOT_CHECKED"
}
}
...
]
}
Now, you can get more detailed information about your specific stack:
$ aws cloudformation describe-stacks --stack-name CdkStarterStackThe output will be very verbose, and we'll not reproduce it here, but you should see interesting information like:
...
"RoleARN": "arn:aws:iam::...:role/cdk-hnb659fds-cfn-exec-role-...-eu-west-3",
"Tags": [
{
"Key": "environment",
"Value": "development"
},
{
"Key": "application",
"Value": "CdkApiGatewayApp"
},
{
"Key": "project",
"Value": "API Gateway with Quarkus"
}
],
...And of course, you may check that your S3 bucket has been successfully created:
$ aws s3api list-buckets --query "Buckets[].Name"Here, using the option --query "Buckets[].Name, you filter the output such that only the bucket name is displayed and you'll see:
[
...
"my-bucket-...",
...
]
If you want to see some properties (for example, the associated tags):
$ aws s3api get-bucket-tagging --bucket my-bucket-...
{
"TagSet": [
{
"Key": "aws:cloudformation:stack-name",
"Value": "CdkStarterStack"
},
{
"Key": "environment",
"Value": "development"
},
{
"Key": "application",
"Value": "CdkStarterApp"
},
{
"Key": "project",
"Value": "The CDK Starter projet"
},
{
"Key": "aws-cdk:auto-delete-objects",
"Value": "true"
}
]
}
Everything seems to be okay and you may conclude that your first test with the CDK is successful. And since you have deployed now a stack with an S3 bucket, you are supposed to be able to use this bucket, for example, to upload files in it, to download them, etc. You can do that by using AWS CLI as shown here. But if you want to do it with the CDK, you need to wait for the next episode.
While waiting for that, don't forget to clean up your AWS workspace such that to avoid being invoiced!
$ cdk destroy --all
aws s3 rm s3://my-bucket-... --recursive
aws s3 rb s3://my-bucket-...Have fun and stay tuned!
Opinions expressed by DZone contributors are their own.
Comments