From Chaos to Clarity: Building a Data Quality Framework That Actually Works
This article offers a practical, step-by-step guide to fix this by defining data quality goals, setting governance standards, adding monitoring, and building trust.
Join the DZone community and get the full member experience.
Join For FreeThe dream of a "data-driven" organization is common to all of them. However, the reality across a wide range of business sectors is that the situation is very opposite; the data is so overwhelming that it can't be managed properly. Even strong data initiatives are sometimes undermined by incomplete records, inconsistent formats, duplicate entries, and obsolete information. The misinterpretation of the situation caused by the use of poor-quality data is the main consequence leading to confusion instead of insight, which is interpreted as missed opportunities, flawed strategies, and wastage of resources.
Data chaos doesn't happen all of a sudden; it silently grows from siloed systems, a lack of governance, and unclear ownership. With the increasing number of data sources and automation of processes, the need for a structured approach to data quality management becomes crucial.
This article presents a no-nonsense, practical, step-by-step framework for converting data confusion into solid wisdom. It covers everything from the definition of quality dimensions, through the establishment of governance standards and monitoring mechanisms, to the implementation of a data trust-building roadmap. Basically, this article describes the creation of a data quality framework across the enterprise that guarantees consistency, reliability, and clarity.
Understanding Data Chaos
“Data chaos” is the term that describes the confusion and disorder of enterprise data, which makes it impossible for organizations to make correct, timely, and certain decisions. It can take different forms, for instance, phony figures caused by duplicate records, changes in analysis due to missing fields, distorted meaning resulting from inconsistent definitions across systems, and valueless or aging data that no longer match the current situation. In such a scenario, even the simplest question, “How many active customers do we have?” can receive a number of contradictory answers.
The situation is usually caused by the combination of technical fragmentation and organizational neglect. Inconsistencies grow when the data is collected by hand, trapped in silos, lacking proper validation procedures, or behind slow technical support. To add to that, without a common data governance structure and common definitions, each business unit is likely to have its own way of interpreting and dealing with data.
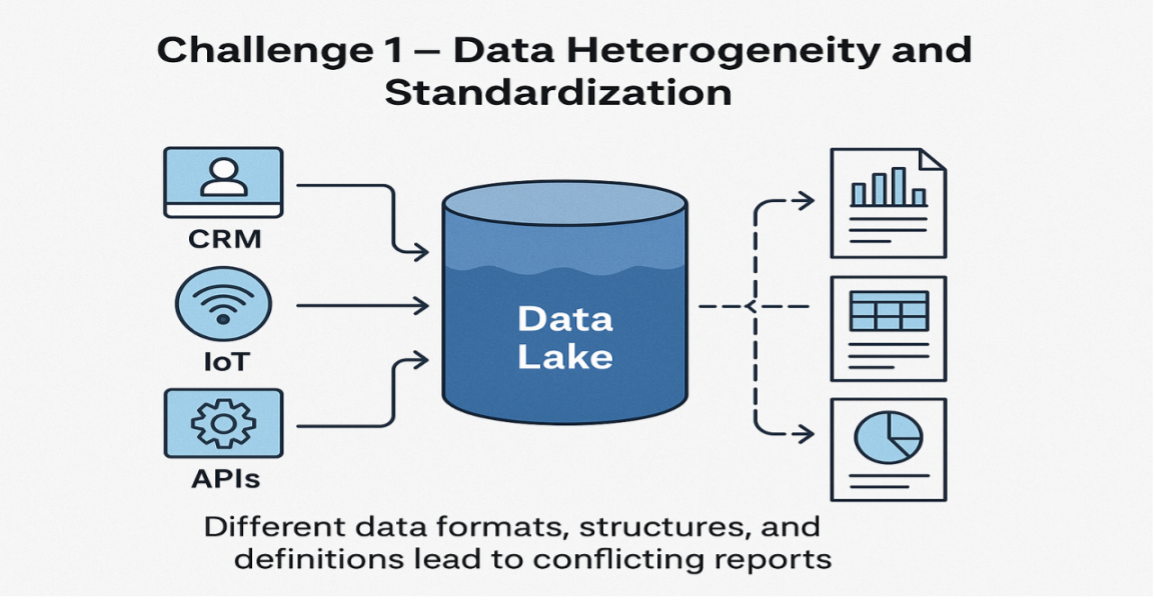
Imagine a retail business in which the different sales regions have different meanings of the term “sales”; one branch counts returns, another doesn’t, and a third one includes discounts as separate transactions. What is the outcome? A set of executive reports that contradict each other, which eventually leads to a lack of trust in analytics and decision-making processes.
Optional Mini-Formula (For Inconsistency)
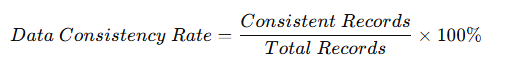
The above formula can be used to show how consistency can be measured
With the increasing reliance on automation, AI, and analytics in business, the cost of data chaos rises proportionately. The quality of every insight is directly linked to the quality of its underlying data. Gaining an understanding of the root causes of chaos is the first step towards achieving clarity.
The Pillars of Data Quality
The establishment of a sustainable data quality framework is not possible for an organization until it gets acquainted with the main pillars that delineate the meaning of “quality.” These dimensions will give the criteria that are measurable to be used in assessing and improving the quality of enterprise data.
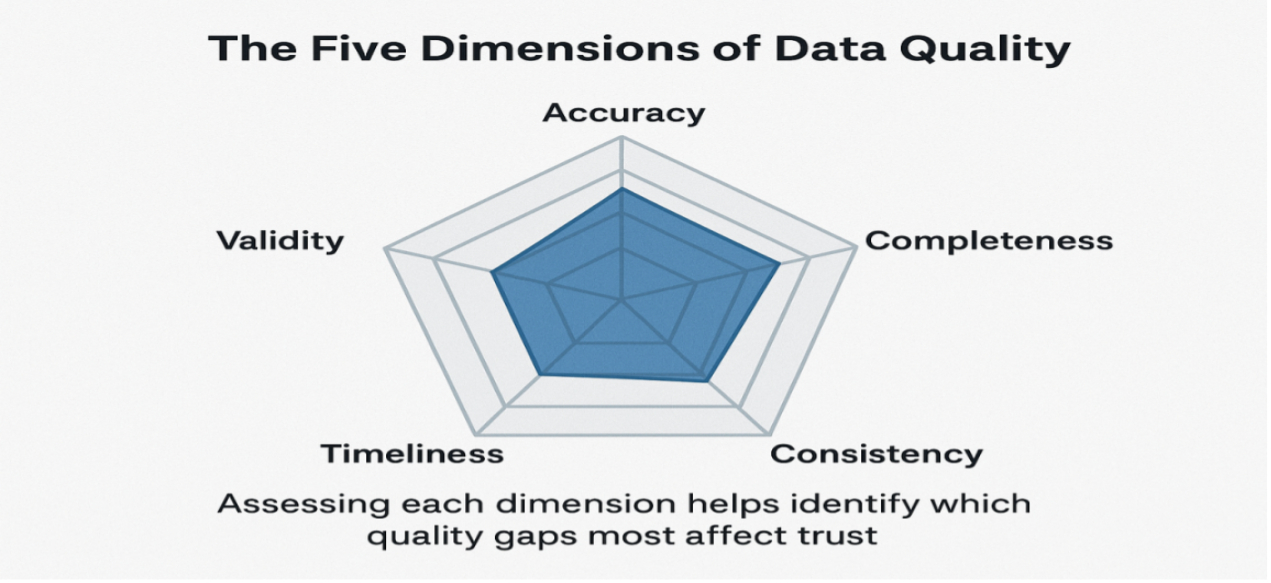
1. Accuracy
The accuracy of data is measured, and the real-world facts are represented by the data correctly. For instance, the address of a customer must be in line with his/her actual location; a tiny typo could result in the wrong address being delivered or even the company's financial problems due to non-compliance.
2. Completeness
Completeness takes care of the situation where all the important fields have been filled in. Missing values, like an email address or a transaction date that is not indicated, may lead to downstream analytics being disrupted or customer engagement being limited.
3. Consistency
Consistency refers to the state in which data is the same throughout all systems. In case a database shows a product price as $99 and another shows it as $95, then reports and forecasts will contradict each other, leading to distrust in the insights being produced.
4. Timeliness
Timeliness indicates how up-to-date and frequently updated the data is. Old inventory records, for example, could lead to either stockouts or overstocking and hence directly influence the profits.
5. Validity
The validity of data is determined by the data being up to the required formats, standards, or business rules. A date field must be in the correct format (for example, YYYY-MM-DD), and the numbers should not exceed the maximum or minimum limits specified in the rules.
Pseudocode (Data Quality Check Function)
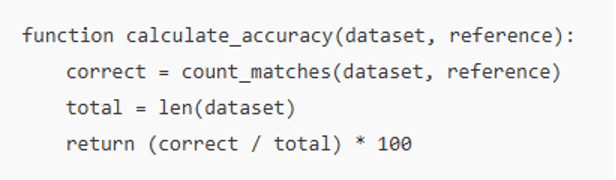
All these dimensions are interrelated in one way or another: there will be no significance of accuracy without timeliness, and completeness will not be maintained without consistency. An effective framework must constantly measure and enhance these dimensions.
Building a Data Quality Framework
A data quality framework is a systematic approach that translates the abstract quality principles into concrete, measurable, and repeatable actions. It gives the organizations the infrastructure they require to evaluate, track, and permanently enhance their data resources. The whole procedure can be outlined in five main stages, each progressive to the last in terms of bringing clarity out of chaos.
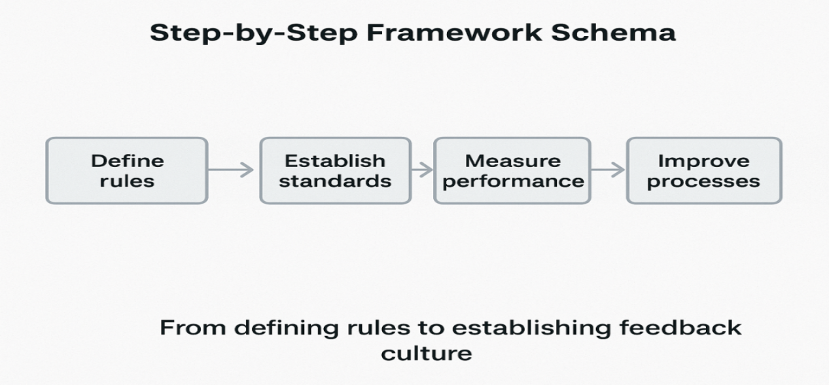
Step 1: Define Quality Rules
The groundwork for any data quality project is the transparent and mutual understanding of the term “good data”. Work together with both non-technical and technical stakeholders to pick out important data entities and to set the validation criteria.
For example:
- Customer_ID has to be both unique and not null.
- Addresses of email accounts must adhere to the standard format.
- Transaction_Date can never be set to a future date.
By setting these rules, the vague expectations become clear standards that can be enforced. Ensure that all teams can access a centralized repository for documentation.
Step 2: Profile and Assess Data
You cannot fix a problem unless you understand how severe it is. Data profiling is a process of examining datasets to find inconsistencies, duplicates, and missing values. Using state-of-the-art tools such as Great Expectations, Deequ, and Soda Core, one can automatically recognize data discrepancies and create comprehensive quality reports. Moreover, the profiling process helps identify the most critical areas, for instance, customer or financial data, where the risk of poor quality is highest and should therefore be the focus of your efforts.
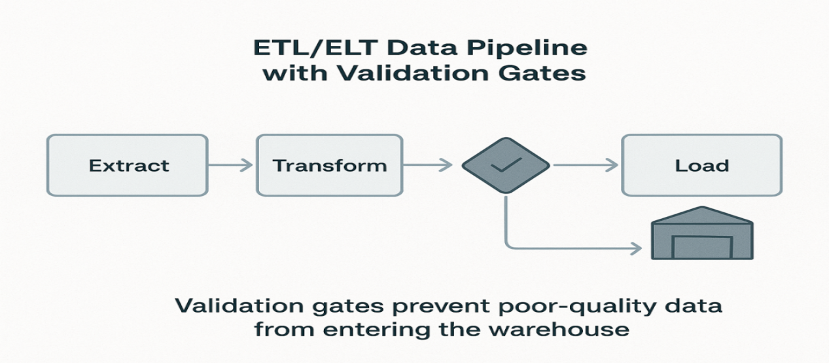
Step 3: Automate Data Validation
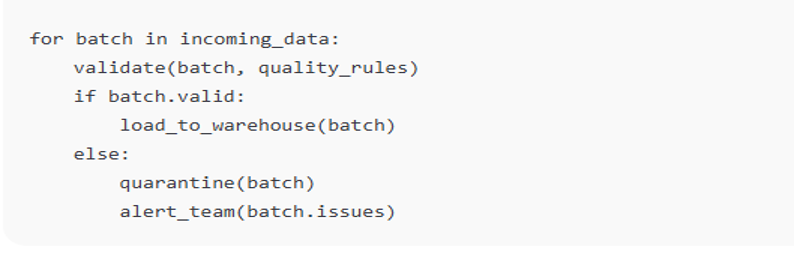
The outdated manual checks cannot cope with the scale of modern data streams. The integration of automatic validation into ETL or ELT pipelines ensures that bad data is flagged or corrected before it spreads. The adoption of tools like Great Expectations permits the definition of tests in code by the engineers:
- df.expect_column_values_to_not_be_null("customer_id")
- df.expect_column_values_to_match_regex("email", r"[^@]+@[^@]+\.[^@]+")
On the other hand, on-the-go facilitation of these rules as part of data ingestion or data transformation jobs turns the quality process into a proactive rather than a reactive one.
Formula example:
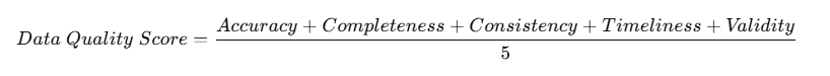
Step 4: Monitor and Visualize
Quality should be tracked as any other business metric. Create dashboards to monitor KPIs such as data completeness, accuracy rates, and timeliness. Visualization tools such as Grafana, Power BI, or Tableau can work with validation logs to visualize the real-time trends and send alerts when limits are crossed. This openness allows technical and business leaders to determine the problematic areas and how the improvements are going.
Step 5: Create Continuous Feedback
Maintaining top-quality data requires a feedback-oriented attitude. Users should be given the opportunity to report mistakes and to participate in developing the validation rules. Quality assessments and automated notifications should pass insights back to governance policies. Data quality should no longer be regarded as an IT function, but rather as an organizational discipline in which every department feels responsible for data integrity.
Pseudo code snippet (pipeline validation):
The five stages working together, organizations' data issues would not be fire-fought but managed through a quality system. The outcome is not only cleaner data but also reliable insights resulting in confident, data-informed decisions.
Tools and Technologies for Data Quality
Governance and processes can be seen as the backbone that gives shape to the data quality framework, while the proper set of tools makes the quality data framework a reality. Modern data ecosystems are heavily dependent on a mix of open-source libraries and enterprise-grade platforms to automate validation, monitoring, and observability. Here are a few essential technologies that play a role in efficient data quality management.
1. Great Expectations
This is an extremely popular Python-based open-source library that facilitates the collaboration of different teams to define, test, and document the data expectations right in their pipelines. The tool also plays well with ETL workflows and data warehouses, which, in turn, help developers check quality through code. For instance, a single process can be used to validate column formats, identify null values, and generate automated data documentation.
2. AWS Deequ
The Deequ tool, developed by Amazon and built on top of Apache Spark, is aimed at performing one of its most scalable data quality checks across huge datasets. It’s characterized by its suitability for cloud-native organizations that are constantly dealing with huge amounts of data, like millions of records daily, offering programmatic ways for profiling, constraint checking, and anomaly detection.
3. Soda Core
This is an easy-to-use open-source tool that allows defining the quality checks for the data in a declarative manner by means of simple YAML-based files. Soda Core is also integrated with Airflow and dbt, which makes it an excellent fit for the data engineering teams that favor configuration over coding.
4. Monte Carlo/Bigeye
These platforms for data observability not only validate data but also monitor the whole data lifecycle. They continuously provide notices to users, even before users in the business become aware of issues, by detecting data drift, schema changes, and pipeline failures in real time.
A detailed table explaining the state of each of the above models is written below:
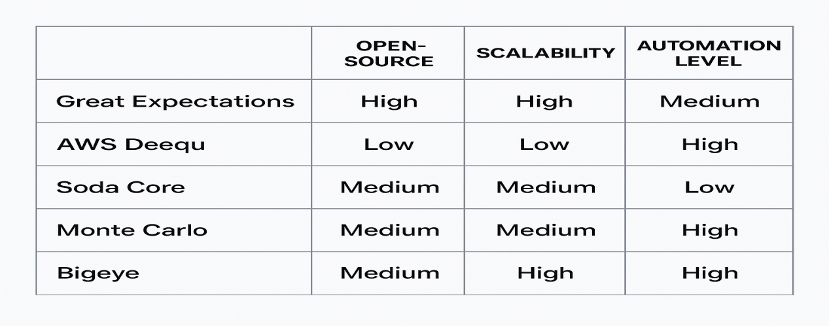
The ideal toolset is determined by data volume, the cloud environment, the team's skill level, and the existing workflow. The main objective remains the same, whether it is achieved through code-based checks or full observability platforms: ensuring the availability of reliable, high-quality data that will serve as the basis for trustworthy, well-informed analytics and business decisions.
Common Pitfalls and How to Avoid Them
Implementing a data quality framework is not an overly technological challenge, but a question of the organization's treatment. Some quite tricky mistakes can completely ruin, and/or evidence, even the best way of the initiative.
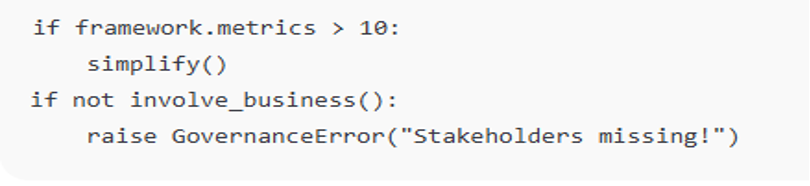
Overcomplicating the Framework
Many teams start by considering too many metrics and KPIs, which only creates confusion rather than clarifying the situation. Identify the most important data elements, then gradually build on them as you grow the organization’s data maturity.
Not Involving Business Stakeholders
Data quality is a matter that goes beyond the technical aspects. If business users are not involved in setting validation rules or priorities, the framework will most likely not meet real-world needs. Working together is the only way to keep data and decision-making close.
Treating Data Quality as a One-Time Fix
Once the data is cleaned up, it still does not mean that all future problems are canceled. Sustainable quality requires continuous monitoring, feedback, and iterative improvement integrated into daily workflows.
Ignoring Ongoing Monitoring
Issues might resurface silently without dashboards, alerts, and regular reviews. Automated and monitored tools have to be used to keep data health visible and actionable.
Ultimately, it is not the tools that cause data quality failures but rather the ownership issue. Success hinges on creating a culture of responsibility for the maintenance of trustworthy data shared across the board, from engineers to top management.
Conclusion
Data disorder is a natural phenomenon that cannot be prevented, but it can be managed with proper measures. Organizations that have the right framework in place can get the most out of their data by turning the unreliable, scattered data into a trustworthy foundation for insight and innovation. Not only does data quality become a technical goal, but it is also a strategic advantage when quality rules are defined, validation is automated, monitoring is continuous, and accountability is fostered.
The path from chaos to clarity is not traveled overnight, but each small advancement builds the organization's capacity to make smarter, quicker, and more confident decisions. With the money taken in for the data quality process, chaos is gone, and the results are truly data-driven.
References and Further Reading
For readers who want to explore data quality tools, methodologies, and governance best practices in more depth, the following resources provide valuable insights and hands-on documentation:
- Great Expectations Documentation: Comprehensive guide to defining, validating, and documenting data expectations.
- AWS Deequ GitHub Repository: Source code and examples for implementing scalable data quality checks using Apache Spark.
- Soda Core Documentation: Open-source framework for declarative data quality testing and monitoring.
- DZone's Data Governance Articles: Expert insights and best practices for establishing governance frameworks and ensuring data integrity.
- Monte Carlo Data Observability: Overview of monitoring strategies for data reliability and pipeline health.
Opinions expressed by DZone contributors are their own.
Comments