Comparing NATS and Kafka: Understanding the Differences
In this article, we will explore the differences between NATS and Kafka in terms of category ranking features, limitations, use cases, and capabilities.
Join the DZone community and get the full member experience.
Join For FreeMessaging systems are game-changers in modern software development, enabling communication between different components of a system. They also help tackle the challenge of processing a high volume of data efficiently while ensuring reliable service delivery, real-time data processing, and secure data transfer between systems.
As messaging systems for modern applications continue to evolve, NATS and Kafka have emerged as part of the most popular options in the market today. Both NATS and Kafka are open-source and have gained a lot of traction due to their reliability, efficiency, and scalability. However, there are several differences between the two, and deciding upon the appropriate messaging system can considerably impact your application. In this article, we will explore the differences between NATS and Kafka in terms of category ranking features, limitations, use cases, and capabilities.
Overview of NATS
NATS is an open-source, message bus technology that powers modern distributed systems. Accordingly, it is responsible for addressing, discovering, and exchanging messages that drive the common patterns in distributed systems, asking and answering questions, aka services/microservices, and making and processing statements, or stream processing.
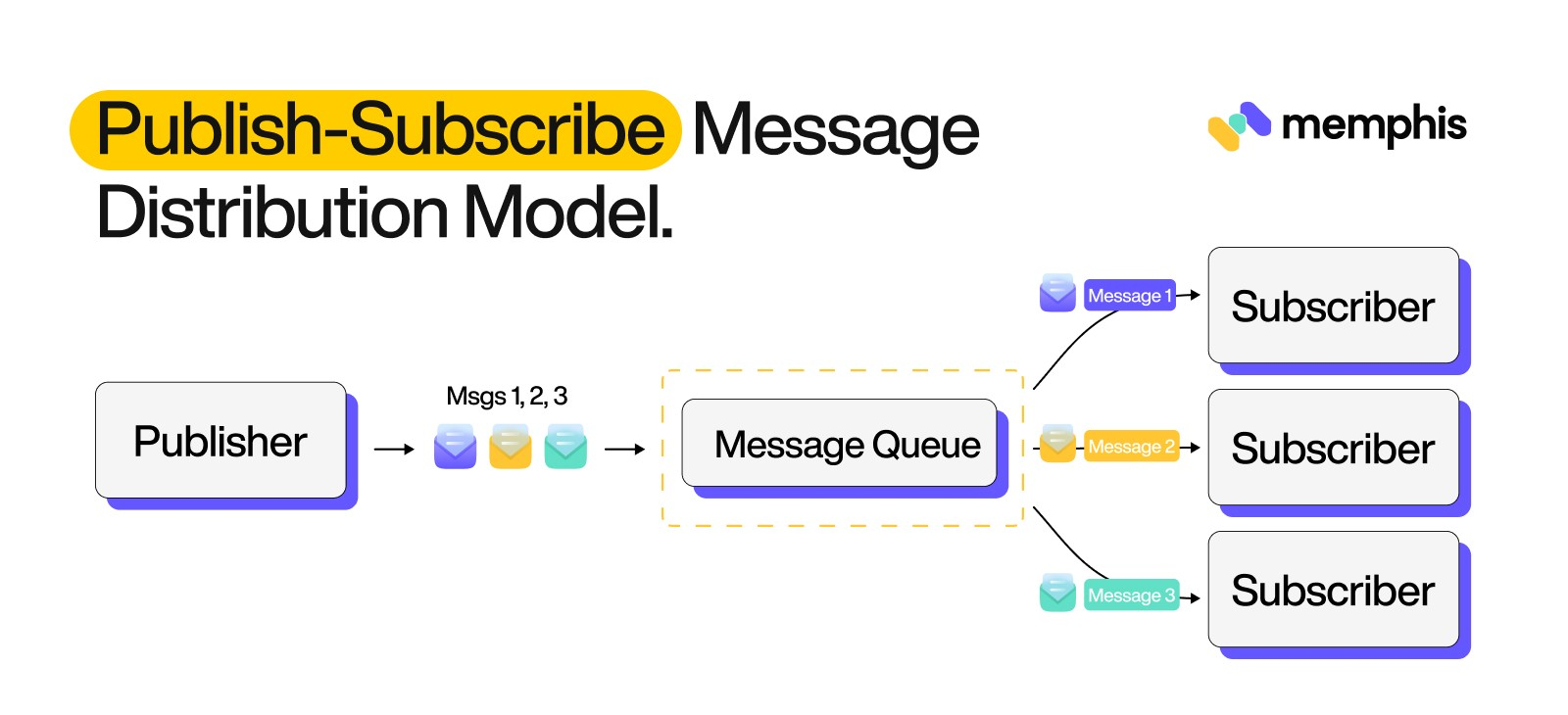
Its publish-subscribe messaging model called subject-based system. In NATS, messages are sent to subjects, which are hierarchical string values, and subscribers listen to these subjects to receive messages. NATS is known for its high throughput and low latency and supports various message types such as JSON, XML, and plain text.
NATS has a built-in distributed persistence system called JetStream. Specifically, this system enables new functionalities and higher qualities of service on top of the base ‘Core NATS’ functionalities and qualities of service. JetStream is built-in to nats-server; therefore, you only need 1 (or 3 or 5 if you want fault-tolerance against 1 or 2 simultaneous NATS server failures) of your NATS server(s) to be JetStream-enabled for it to be available to all the client applications.
Overview of Kafka
Kafka is an open-source distributed event streaming platform. Kafka is designed to offer high throughput, fault tolerance, and horizontal scalability, with the ability to handle a high volume of data. Kafka has become popular among big data and distributed systems.
Kafka was originally developed at LinkedIn. In 2011, it became an open-source Apache project, and by 2012, it had become a first-class Apache project. Kafka is written in Scala and Java, and it is designed to handle real-time data feeds with high throughput and low latency.
Kafka uses a publish-subscribe messaging model called a topic-based system. Topics are partitions that Kafka maintains in a distributed fashion, and producers send messages to these topics. Consumers subscribe to topics to receive messages. Kafka is known for its high throughput, data retention, and ability to store large amounts of data.
Comparing NATS and Kafka
NATS and Kafka have differences in their architecture, messaging patterns, and scalability. With its subject-based messaging, NATS is simpler than Kafka, which has a topic-based messaging system. NATS is more suitable for microservices while Kafka is more suitable for big data applications, where it can process large amounts of data in real-time.
Kafka’s distributed architecture allows it to achieve high concurrency and fault tolerance, while NATS is designed as a single-instance process, limiting its scalability. Kafka also supports multiple message types such as Avro, Protocol Buffers, and Thrift.
NATS is designed for scenarios where high performance and low latency are crucial, is easy to operate, with the option to deploy it over Kubernetes, monitor it using Grafana, encrypt traffic, and many other features.
Tabular Comparison Between NATS and Apache Kafka
|
NATS | Apache Kafka |
| Message Consumption Model | Publish-Subscribe. NATS supports pull-based and push-based architecture. | Publish-Subscribe. Kafka uses a pull-based architecture where consumers pull messages from the server. |
| Delivery guarantee | NATS supports at most once delivery guarantee. | Exactly-once delivery guarantee. |
| Scalability | NATS can be horizontally scaled in or out by adding or removing servers. | Kafka was designed to scale horizontally by adding brokers to a cluster or scale in by removing brokers. |
| Message Ordering | NATS implements source ordered delivery per publisher. There are no guarantees of message delivery order amongst multiple publishers. | Kafka guarantees message ordering within a partition. |
| Use cases |
|
|
| Consumer Groups | Available as Queue Groups | Available as Consumer Groups |
| Persistence | Persistence achieved using JetStream. | Built-in persistence via log storage |
| License | Apache 2.0 | Apache 2.0 |
| Languages Supported | Official clients are available in Go, Rust, JavaScript, TypeScript, Python, Java, C#, C, Ruby and Elixir, in addition to 30+ community-contributed clients. | Clients are available in Java and Scala, Go, Python, C/C++, and many other programming languages as well as REST APIs |
| Security |
|
|
Use Cases for NATS
- NATS is best suited for real-time communications between microservices, cloud-native applications, and IoT devices. It is a lightweight messaging system designed to handle real-time events and messages.
- NATS JetStream is a highly advanced message streaming system that distributes messages across a network using the publish/subscribe messaging pattern just like NATS. JetStream is the next generation of NATS, serving as the latest iteration of message streaming technology from NATS, supplanting the older NATS, which sunset in June 2023.
- JetStream provides message streaming support that is seamlessly integrated into the NATS server, ensuring efficient and hassle-free operation. With JetStream, you get a slew of outstanding features, such as a file or memory-based persistence, the ability to read messages from a specific time or message sequence, and both durable and ephemeral message consumer support.
Use Cases for Kafka
- Kafka is commonly utilized for collecting operational monitoring data. This includes collecting statistics from distributed applications to generate centralized operational data feeds.
- Kafka is suitable for applications that require high data throughputs, like big data processing and analysis. Kafka uses a distributed processing model, which makes it well-suited for high-level analytics and real-time analytics.
- Frameworks like Storm and Spark Streaming can read data from a topic within Kafka, process it, and store the processed data in a new topic where it can be accessed by users and applications.
- Kafka can be leveraged to gather logs from various services across an organization and disseminate them in a standardized format to several consumers.
- Kafka finds usefulness in many organizations and industries. These include financial industries for payment processing, healthcare organizations, telematics for real-time tracking and monitoring of cars, trucks, fleets, and shipments, and many more.
Published at DZone with permission of Sveta Gimpelson. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments