Conditional Probability and Bayes' Theorem
A doctor orders a blood test that is 90% accurate. Bob's test is positive. You might be tempted to say that there's a 90% chance he has the disease, but this is wrong.
Join the DZone community and get the full member experience.
Join For FreeOne morning, while seeing a mention of a disease on Hacker News, Bob decides on a whim to get tested for it; there are no other symptoms, he's just curious. He convinces his doctor to order a blood test, which is known to be 90% accurate. For 9 out of 10 sick people, it will detect the disease (but for 1 out of 10 it won't); similarly, for 9 out of 10 healthy people, it will report no disease (but for 1 out of 10 it will).
Unfortunately for Bob, his test is positive; what's the probability that Bob actually has the disease?
You might be tempted to say 90%, but this is wrong. One of the most common fallacies made in probability and statistics is mixing up conditional probabilities. Given event D ("Bob has disease") and event T ("test was positive"), we want to know what P(D|T) is: the conditional probability of D given T. But the test result is actually giving us P(D|T) — which is distinct from P(D|T).
In fact, the problem doesn't provide enough details to answer the question. An important detail that's missing is the prevalence of the disease in population; that is, the value of P(D) without being conditioned on anything. Let's say that it's a moderately common disease with 2% prevalence.
To solve this without any clever probability formulae, we can resort to the basic technique of counting by cases. Let's assume there is a sample of 10,000 people [1]; test aside, how many of them have the disease? 2%, so 200.

Of the people who have the disease, 90% will test positive and 10% will test negative. Similarly, of the people with no disease, 90% will test negative and 10% will test positive. Graphically:
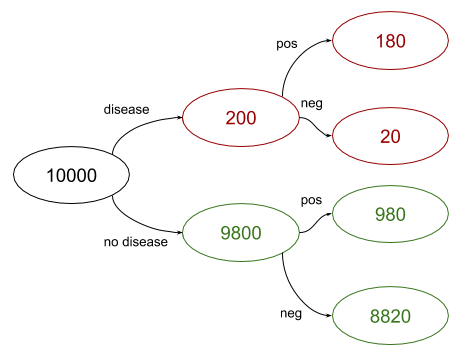
Now, we just have to count. There are 980 + 180 = 1,160 people who tested positive in the sample population. Of these people, 180 have the disease. In other words, given that Bob is in the "tested positive" population, his chance of having the disease is 180/1160 = 15.5%. This is far lower than the 90% test accuracy; conditional probability often produces surprising results. To motivate this, consider that the number of true positives (people with the disease that tested positive) is 180, while the number of false positives (people w/o the disease that tested positive) is 980. So the chance of being in the second group is larger.
Conditional Probability
As the examples shown above demonstrate, conditional probabilities involve questions like, "What's the chance of A happening, given that B happened?" and they are far from being intuitive. Luckily, the mathematical theory of probability gives us the precise and rigorous tools necessary to reason about such problems with relative elegance.
The conditional probability P(A|B) means, "What is the probability of event A given that we know event B occurred?" Its mathematical definition is:
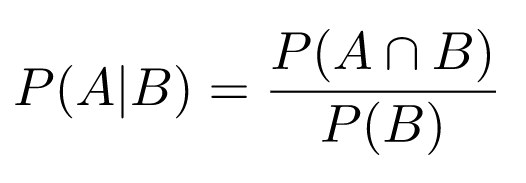
Note:
- Obviously, this is only defined when P(B) > 0.
- Here, P(A∩B) is the probability that both A and B occurred.
The first time you look at it, the definition of conditional probability looks somewhat unintuitive. Why is the connection made this way? Here's a visualization that I found useful:
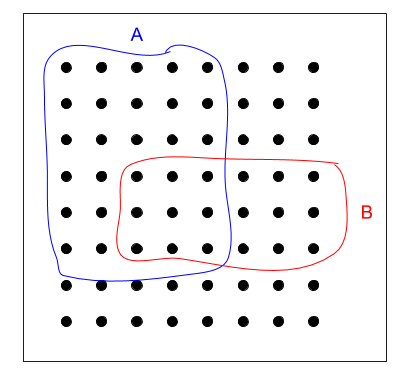
The dots in the black square represent the "universe," our whole sampling space (let's call it S, and then P(S) = 1). A and B are events. Here, P(A) = 30/64 and P(B) = 18/64. But what is P(A|B)? Let's figure it out graphically. We know that the outcome is one of the dots encircled in red. What is the chance we got a dot also encircled in blue? It's the number of dots that are both red and blue divided by the total number of dots in red. Probabilities are calculated as these counts are normalized by the size of the whole sample space; all the numbers are divided by 64, so these denominators cancal out; we'll have:
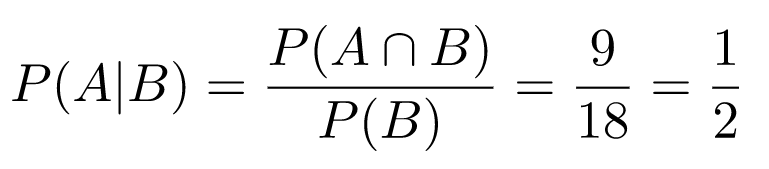
In words: the probability that A happened, given that B happened, is 1/2, which makes sense when you eyeball the diagram, and assuming events are uniformly distributed (that is, no dot is inherently more likely to be the outcome than any other dot).
Another explanation that always made sense to me was to multiply both sides of the definition of conditional probability by the denominator to get:
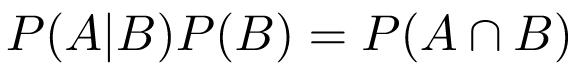
In words: We know the chance that A happens given B; if we multiply this by the chance that B happens, we get the chance that both A and B happened.
Finally, since P(A∩B) = P(B∩A), we can freely exchange A and B in these definitions (they're arbitrary labels, after all) to get:
Equation 1
This is an important equation we'll use later on.
Independence of Events
By definition, two events A and B are independent if:
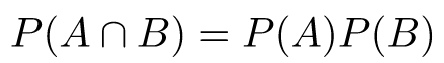
Using conditional probability, we can provide a slightly different definition. Since:
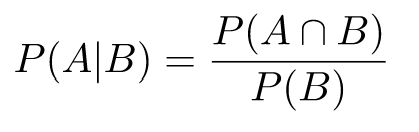
And P(A∩B) = P(A)P(B):
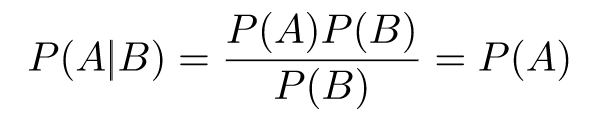
As long as P(B) > 0, for independent A and B, we have P(A|B) = P(A); in words, B doesn't affect the probability of A in any way. Similarly, we can show that for P(A) > 0, we have P(B|A) = P(B).
Independence also extends to the complements of events. Recall that P(B^C) is the probability that B did not occur, or 1 - P(B); since conditional probabilities obey the usual probability axioms, we have P(B^C|A) = 1 - P(B|A). Then, if A and B are independent:
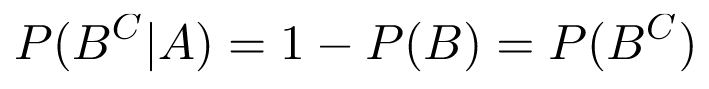
Therefore, B^C is independent of A. Similarly, the complement of A is independent of B, and the two complements are independent of each other.
Bayes' Theorem
Starting with Equation 1 from above:
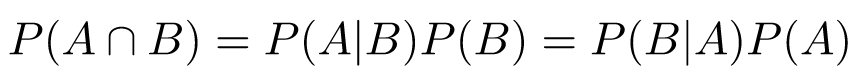
And taking the right-hand-side equality and dividing it by P(B) (which is positive, per definition), we get Bayes' theorem:
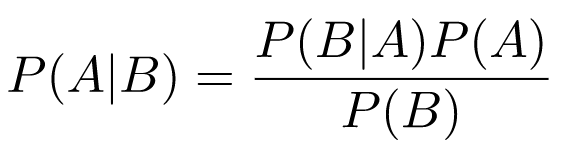
This is an extremely useful result because it links P(B|A) with P(A|B). Recall the disease test example, where we're looking for P(D|T). We can use Bayes' theorem:
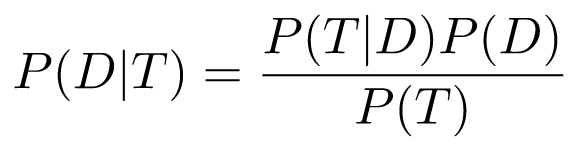
We know P(T|D) and P(D), but what is P(T)? You may be tempted to say it's 1 because, "Well, we know the test is positive," but that would be a mistake. To understand why, we have to dig a bit deeper into the meanings of conditional vs. unconditional probabilities.
Prior and Posterior Probabilities
Fundamentally, conditional probability helps us address the following question:
How do we update our beliefs in light of new data?
Prior probability is our beliefs (probabilities assigned to events) before we see the new data. Posterior probability is our beliefs after we see the new data. In the Bayes equation, prior probabilities are simply the unconditioned ones, while posterior probabilities are conditional. This leads to a key distinction:
- P(T|D): Posterior probability of the test being positive when we have new data about the person — they have the disease.
- P(T): Prior probability of the test being positive before we know anything about the person.
This should make it clearer why we can't just assign P(T) = 1. Instead, recall the "counting by cases" exercise we did in the first example, where we produced a tree of all possibilities; let's formalize it.
Law of Total Probability
Suppose we have the sample space S and some event B. Sometimes, it's easier to find the probability of B by first partitioning the space into disjoint pieces:
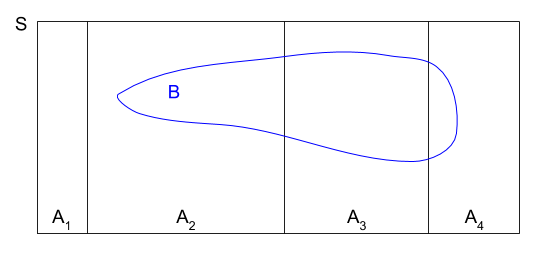 Then, because the probabilities of are disjoint, we get:
Then, because the probabilities of are disjoint, we get:
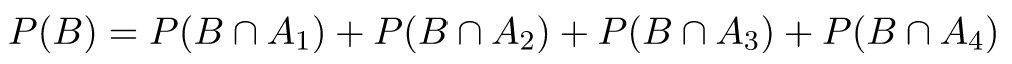
Or, using Equation 1:
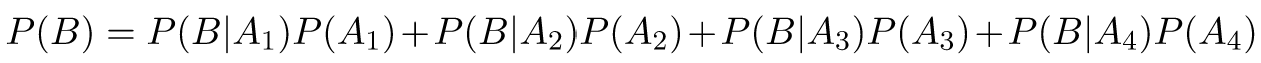
Bayesian Solution to the Disease Test Example
Now, we have everything we need to provide a Bayesian solution to the disease test example. Recall that we already know:
- P(T|D) = 0.9: Test accuracy
- P(D) = 0.02: Disease prevalance in the population
Now, we want to compute P(T). We'll use the law of total probability, with the space partitioning of "has disease"/"does not have disease":
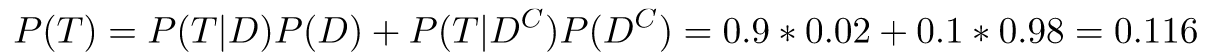
Finally, plugging everything into Bayes' theorem:
...which is the same result we got while working through possibilities in the example.
Conditioning on Multiple Events
We've just computed P(D|T): the conditional probability of event D (patient has disease) on event T (patient tested positive). An important extension of this technique is being able to reason about multiple tests, and how they affect the conditional probability. We'll want to compute P(D|T1 ∩ T2), where T1 and T2 are two events for different tests.
Let's assume T1 is our original test. T2 is a slightly different test that's only 80% accurate. Importantly, the tests are independent (they test completely different things) [2].
We'll start with a naive approach that seems reasonable. For T1, we already know that P(D|T1) = 0.155. For T2, it's similarly simple to compute:
The disease prevalence is still 2%, and using the law of total probability, we get:
Therefore:
In other words, if a person tests positive with the second test, the chance of being sick is only 7.5%. But what if they tested positive for both tests?
Well, since the tests are independent, we can do the usual probability trick of combining the complements. We'll compute the probability the person is not sick given positive tests, and then compute the complement of that. P(D^C|T1) = 1 - 0.155 = 0.845, and P(D^C|T2) = 1 - 0.075 = 0.925. Therefore:
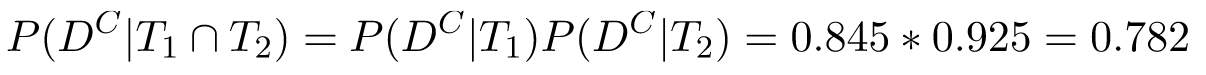
And complementing again, we get P(D|T1 ∩ T2)= 1 - 0.782 = 0.218. The chance of being sick, having tested positive both times is 21.8%.
Unfortunately, this computation is wrong — very wrong. Can you spot why before reading on?
We've committed a fairly common blunder in conditional probabilities. Given the independence of P(T1|D) and P(T2|D), we've assumed the independence of P(T1|D) and P(T2|D), but this is wrong! It's even easy to see why, given our concrete example. Both of them have P(D) — the disease prevalence — in the numerator. Changing the prevalence will change both P(T1|D) and P(T2|D) in exactly the same proportion; say, increasing the prevalence 2x will increase both probabilities 2x. They're pretty strongly dependent!
The right way of finding P(D|T1 ∩ T2) is working from first principles. T1 ∩ T2 is just another event, so treating it as such and using Bayes' theorem, we get:
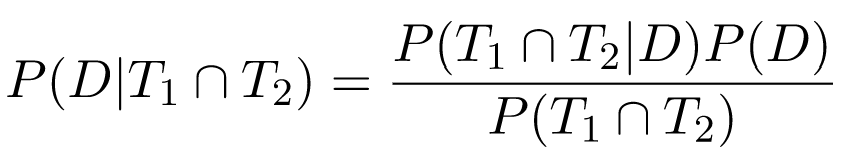
Here, P(D) is still 0.02; P(D|T1 ∩ T2) = 0.9 * 0.8 = 0.72. To compute the denominator, we'll use the law of total probability again:
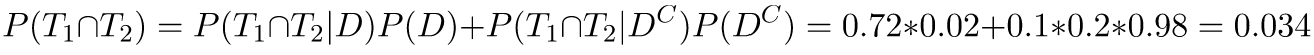
Combining them all together, we'll get P(D|T1 ∩ T2) = 0.42; the chance of being sick, given two positive tests, is 42%, which is twice higher than our erroneous estimate [3].
Bayes' Theorem With Conditioning
Since conditional probabilities satistfy all probability axioms, many theorems remain true when adding a condition. Here's Bayes theorem with extra conditioning on event C:
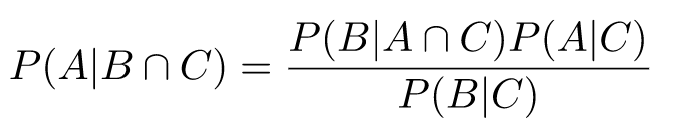
In other words, the connection between P(A|B) and P(B|A) is true even when everything is conditioned on some event C. To prove it, we can take both sides and expand the definitions of conditional probability until we reach something trivially true:
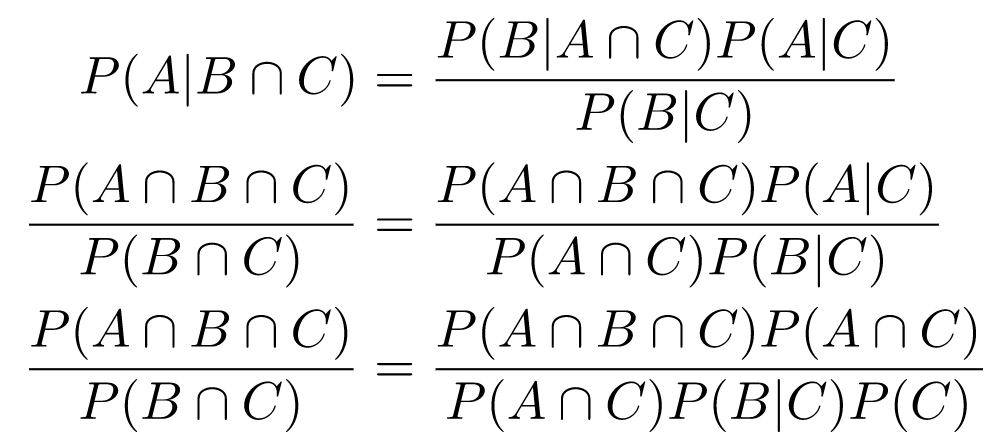
Assuming that , it cancels out (similarly for P(C) > 0 in a later step):
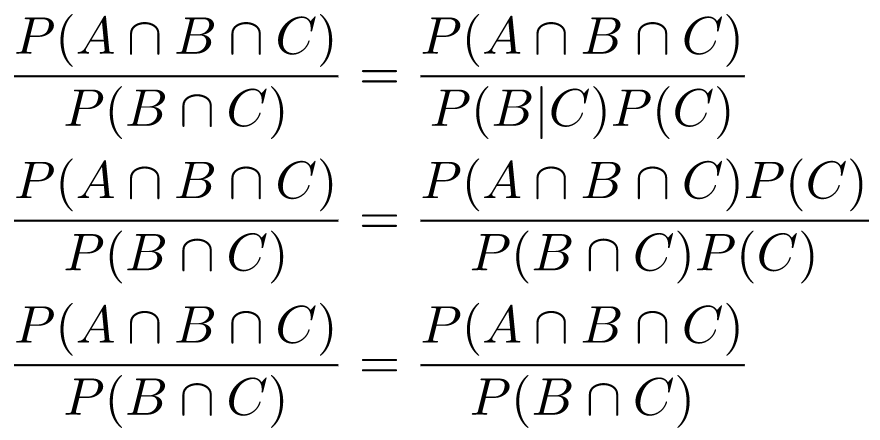
Using this new result, we can compute our two-test disease exercise in another way. Let's say that T1 happens first, and we've already computed P(D|T1). We can now treat this as the new prior data, and find P(D|T1 ∩ T2) based on the new evidence that T2 happened. We'll use the conditioned Bayes formulation with being C.
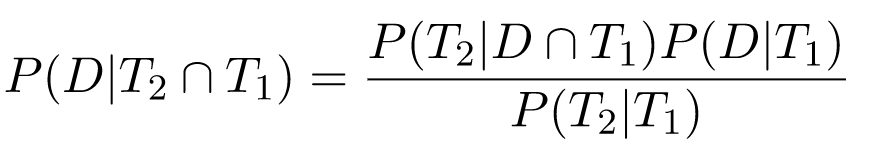
We already know that P(D|T1) is 0.155; What about P(T2|D ∩ T1)? Since the tests are independent, this is actually equivalent to P(T2|D), which is 0.8. The denominator requires a bit more careful computation:
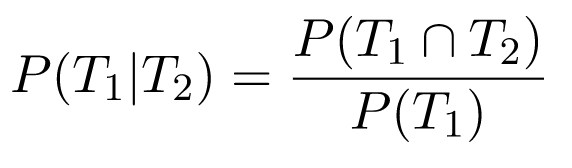
We've already found that P(T1) = 0.116 previously using the law of total probability. Using the same law:
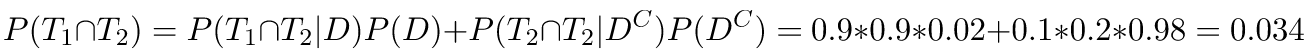
Therefore, P(T1|T2) = 0.034/0.116 = 0/293 and we now have all the ingredients:
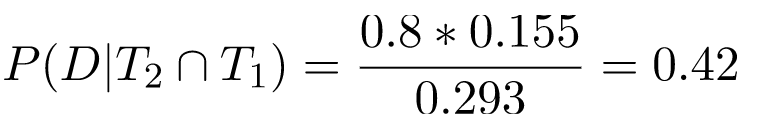
We've reached the same result using two different approaches, which is reassuring. Computing with both tests taken together is a bit quicker, but taking one test at a time is also useful because it lets us update our beliefs over time, given new data.
Computing conditional probabilities with regards to multiple parameters is very useful in machine learning — this would be a good topic for a separate article.
Published at DZone with permission of Eli Bendersky. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments