Consider Using [NOT] EXISTS Instead of [NOT] IN
Which performs better for database query optimization: EXISTS, IN, ANY, EXCEPT, INNER JOIN, OUTER JOIN, or INTERSECT?
Join the DZone community and get the full member experience.
Join For FreeIt used to be that the EXISTS logical operator was faster than IN when comparing datasets using a subquery. For example, in cases where the query had to perform a certain task, but only if the subquery returned any rows, then when evaluating WHERE [NOT] EXISTS (subquery), the database engine could quit searching as soon as it had found just one row, whereas WHERE [NOT] IN (subquery) would always collect all the results from the sub-query, before further processing.
However, the query optimizer now treats EXISTS and IN the same way, whenever it can, so you're unlikely to see any significant performance differences. Nevertheless, you need to be cautious when using the NOT IN operator if the subquery's source data contains NULL values. If so, you should consider using a NOT EXISTS operator instead of NOT IN, or recast the statement as a left outer join.
A recommendation to prefer the use of [NOT] EXISTS over [NOT] IN is included as a code analysis rule in SQL Prompt (PE019).
Which Performs Better: EXISTS or IN....?
There are many ways of working out the differences between two datasets, but two of the most common are the EXISTS and the IN logical operator. Imagine that we have two simple tables, one with all the common words in the English language (CommonWords) and the other with a list of all the words in Bram Stoker's Dracula (WordsInDracula). The TestExistsAndIn download includes the script to create these two tables and populate each one from its associated text file. It is useful, generally, to have tables like these in your sandbox server for running tests while doing development work, though the book you use is your choice!
How many words occur in Dracula that aren't common words? Assuming there are no NULL values in the CommonWords.Word column (more on this later), then the following queries will return the same result (1555 words), and have the same execution plan, which uses a Merge Join (Right Anti Semi Join) between the two tables.
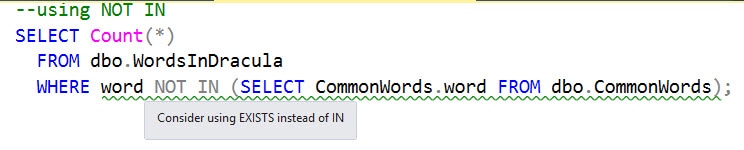
--using NOT IN
SELECT Count(*)
FROM dbo.WordsInDracula
WHERE word NOT IN (SELECT CommonWords.word FROM dbo.CommonWords);
--Using NOT EXISTS
SELECT Count(*)
FROM dbo.WordsInDracula
WHERE NOT EXISTS
(SELECT * FROM dbo.CommonWords
WHERE CommonWords.word = WordsInDracula.word);Listing 1
In short, the SQL Server optimizer treats either query in the same way, and they will perform the same too.
...or ANY, EXCEPT, INNER JOIN, OUTER JOIN, or INTERSECT...?
What about all the other possible techniques, though, such as using ANY, EXCEPT, INNERJOIN, OUTERJOIN, or INTERSECT? Listing 2 shows seven further alternatives that I could think of easily, though there will be others.
--using ANY
SELECT Count(*)
FROM dbo.WordsInDracula
WHERE NOT(WordsInDracula.word = ANY
(SELECT word
FROM commonwords )) ;
--Right anti semi merge join
--using EXCEPT
SELECT Count(*)
FROM
(
SELECT word
FROM dbo.WordsInDracula
EXCEPT
SELECT word
FROM dbo.CommonWords
) AS JustTheUncommonOnes;
--Right anti semi merge join
--using LEFT OUTER JOIN
SELECT Count(*)
FROM dbo.WordsInDracula
LEFT OUTER JOIN dbo.CommonWords
ON CommonWords.word = WordsinDracula.word
WHERE CommonWords.word IS NULL;
--right outer merge join
--using FULL OUTER JOIN
SELECT Count(*)
FROM dbo.WordsInDracula
full OUTER JOIN dbo.CommonWords
ON CommonWords.word = WordsinDracula.word
WHERE CommonWords.word IS NULL;
--Full outer join implemented as a merge join.
--using intersect to get the difference
SELECT (SELECT Count(*) FROM WordsInDracula)-Count(*)
FROM
(
SELECT word
FROM dbo.WordsInDracula
intersect
SELECT word
FROM dbo.CommonWords
) AS JustTheUncommonOnes;
--inner merge join
--using FULL OUTER JOIN syntax to get the difference
SELECT Count(*)-(SELECT Count(*) FROM CommonWords)
FROM dbo.WordsInDracula
full OUTER JOIN dbo.CommonWords
ON CommonWords.word = WordsinDracula.word
--full outer merge join
--using INNER JOIN syntax to get the difference
SELECT (SELECT Count(*) FROM WordsinDracula)-Count(*)
FROM dbo.WordsInDracula
INNER JOIN dbo.CommonWords
ON CommonWords.word = WordsinDracula.word
--inner merge joinListing 2
The Test Harness
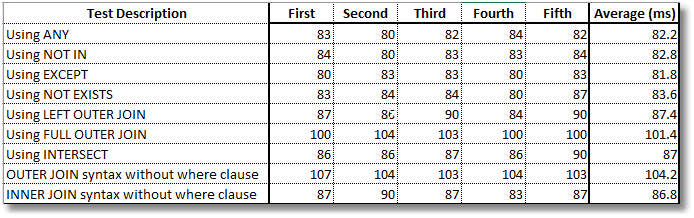
All nine queries give the same results, but does anyone approach perform better? Let's put them all in a simple test harness to see how long each version takes! Again, the code download file includes the test harness code and all nine queries.
As the results show, although the queries look rather different, it's generally just syntactic sugar to the optimizer. However elegant your SQL, the optimizer merely shrugs and comes up with an efficient plan to execute it. In fact, the first four all use the exact same "right anti semi merge join" execution plan, and all take the same amount of time.
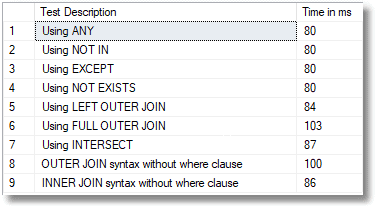
We'll check for variation by running the test several times. The INTERSECT and INNER JOIN queries both used an inner merge join and were close. The two FULL OUTER JOIN queries were a bit slower, but it was a close race.
The Pitfall of NOT IN
There is a certain unreality in comparing sets with null values in them, but if it happens in the heat of everyday database reporting, things can go very wrong. If you have a NULL value in the result of the subquery or expression, that is passed to the IN logical operator, it will give a reasonable response, and the same as the equivalent EXISTS. However, NOT IN behaves very differently.
Listing 3 demonstrates the problem. We insert three common and three uncommon words into a @someWord table variable, and we want to know the number of common words that aren't in our table variable.
SET NOCOUNT ON;
DECLARE @someWord TABLE
(
word NVARCHAR(35) NULL
);
INSERT INTO @someWord
(
word
)
--three common words
SELECT TOP 3
word
FROM dbo.commonwords
ORDER BY word DESC;
-- three uncommon words
INSERT INTO @someWord
(
word
)
VALUES
('flibberty'),
('jibberty'),
('flob');
SELECT [NOT EXISTS without NULL] = COUNT(*)
FROM commonwords AS MyWords
WHERE NOT EXISTS
(
SELECT word FROM @someWord AS s WHERE s.word LIKE MyWords.word
);
SELECT [NOT IN without NULL] = COUNT(*)
FROM commonwords AS MyWords
WHERE word NOT IN (
SELECT word FROM @someWord
);
--Insert a NULL value
INSERT INTO @someWord
(
word
)
VALUES
(NULL);
SELECT [NOT EXISTS with NULL] = COUNT(*)
FROM commonwords AS MyWords
WHERE NOT EXISTS
(
SELECT word FROM @someWord AS s WHERE s.word LIKE MyWords.word
);
SELECT [NOT IN with NULL] = COUNT(*)
FROM commonwords AS MyWords
WHERE word NOT IN (
SELECT word FROM @someWord
);Listing 3
The NOTIN query, before we inserted a NULL into @ some word, and both the NOTEXISTS queries, all tell us correctly that 60,385 words are not in our table variable, because three are, and there are 60,388 common words in all. However, if the subquery can return a NULL, then NOTIN returns no rows at all.

NULL really means "unknown" rather than nothing, which is why any expression that compares to a NULL value returns NULL, or unknown.
Logically, SQL Server evaluates the subquery, replaces it with the list of values it returns, and then evaluates the [NOT]IN condition. For the IN variant of our query, this does not cause a problem because it resolves to the following:
WHERE word = 'flibberty' OR word = 'jibberty' OR word = 'flob'
OR word = 'zygotes' OR word = 'zygote' OR word = 'zydeco'
OR word = NULL;This returns three rows, for the matches on the 'z...' words. The sting comes with NOTIN, which resolves to the following:
WHERE word <> 'flibberty' AND word <> 'jibberty'AND word <> 'flob'
AND word <> 'zygotes' AND word <> 'zygote' AND word <> 'zydeco'
AND word <> NULL;The AND condition with a compassion to NULL evaluates as "unknown," and so the expression will always return zero rows. This isn't a bug; it is by design. You can argue that a NULL shouldn't be allowed in the "any" column where you want to use a NOTIN expression, but in our real working lives, these things can creep into table sources. It is worth being cautious. So, use the EXISTS variant, or one of the others, or always remember to include a WHERE clause in the IN condition to eliminate the NULLs.
Published at DZone with permission of Phil Factor. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments