5 Warning Signs Your Data Architecture Needs a Redesign (Before It Falls Apart)
Five signs your data architecture needs redesign. Fix with semantic layer, active metadata, embedded governance, AI security, maintainable design.
Join the DZone community and get the full member experience.
Join For FreeMost data architectures don't fail all of a sudden. They clearly show warning signs for months, or sometimes years, before anyone takes action. By that time, the damage is already done.
I have spent 20 years building and reviewing data platforms across industries (from CPG to healthcare to consumer tech), and here is what I've learned to identify these signals early.
The good news is that you can fix them before they become a disaster.
The bad news is that most organizations ignore these signs until an AI initiative gets stuck, executives lose trust in reports/dashboards, or new joinees quit because the system is too complex to understand and maintain.
Here are five critical signs that your data architecture needs a redesign, along with what to do about each one.
Sign 1: Your AI Initiatives Keep Stalling at the Data Layer
You've got the right team. You've picked the best models. You've invested in the necessary infrastructure. Still, your AI projects keep hitting the same blockers: they can't move past experimentation.
The problem isn't your models. It's your data.
What's Actually Happening is AI systems need three things that most legacy data architectures don't provide:
- Semantic layer: Clear definitions of what your data means
- Data lineage: Traceability of where data came from and how it transformed
- Governed access: Controlled, policy-driven data access at scale
Without these, your AI models are working with incomplete or inconsistent information. They might produce results, but you can't simply trust them. And when business leaders ask, "Why did the model make this decision?" you can't answer.
The Architecture Gap
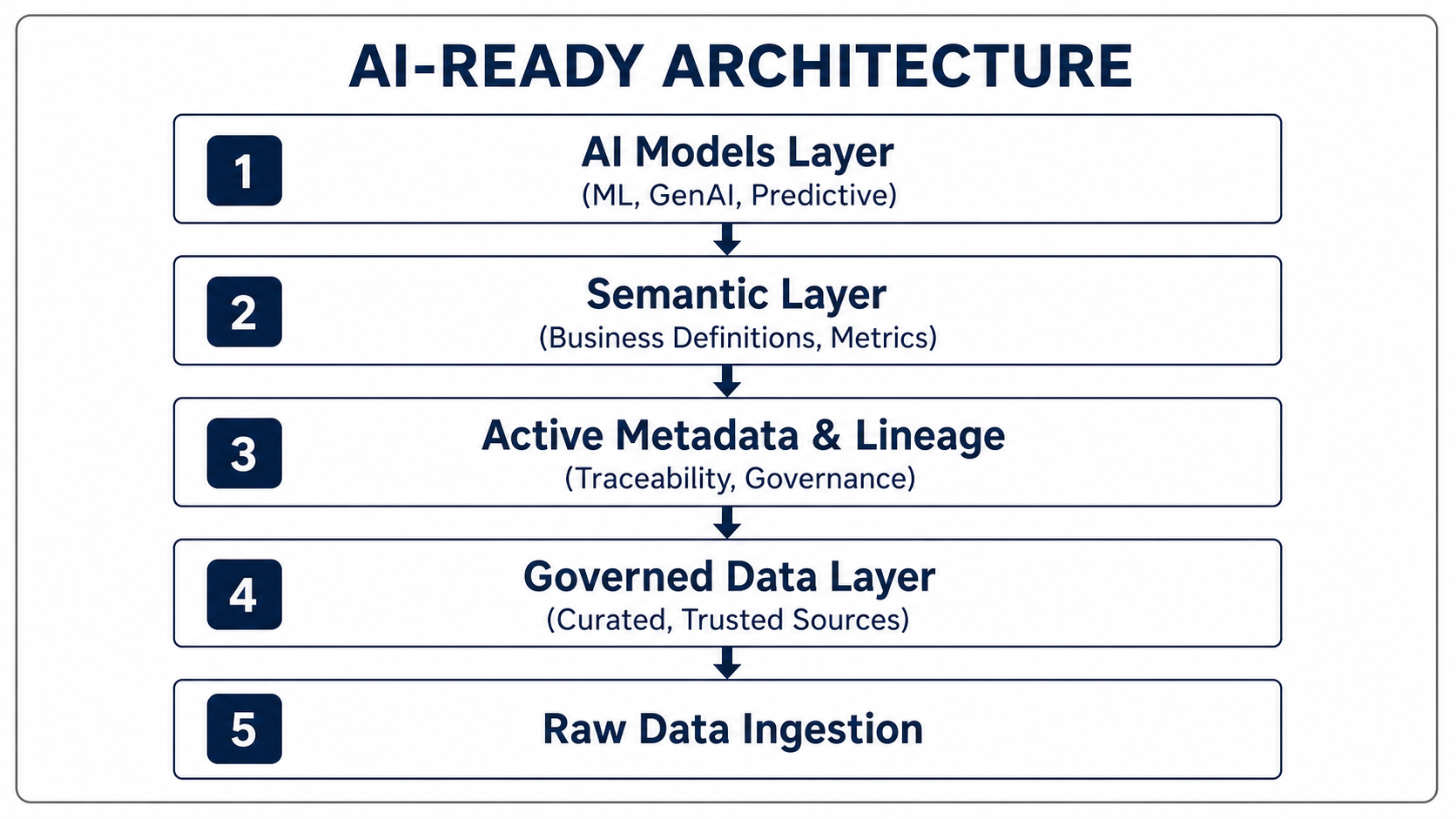
This is what an AI-ready architecture looks like. Most architectures skip the middle layers. They have ingested raw data and may have built some curated/gold-layer tables, but nothing in between. That's why AI fails.
What to Fix?
- Add a semantic layer that defines business metrics consistently across teams
- Implement active metadata that tracks lineage automatically
- Build governed access into your architecture, not as a separate policy document
AI readiness starts in the architecture. Not the model you picked.
Sign 2: Different Teams Get Different Answers From the Same Data
The marketing department says revenue is $10M. The finance department says it's $9.2M. The CEO's dashboard shows $10.5M.
Everyone's using the same source data. Yet nobody agrees.
This isn't a reporting problem; this is a semantic layer problem. When you don't have a centralized definition of what "revenue" means (or any other business metric), every team creates its own version.
Marketing might count revenue when a campaign is launched. Finance counts it when payment is recognized. The executive dashboard might include projected revenue. All "correct," but they don't match.
The Cost of Inconsistency

The Architecture You Need
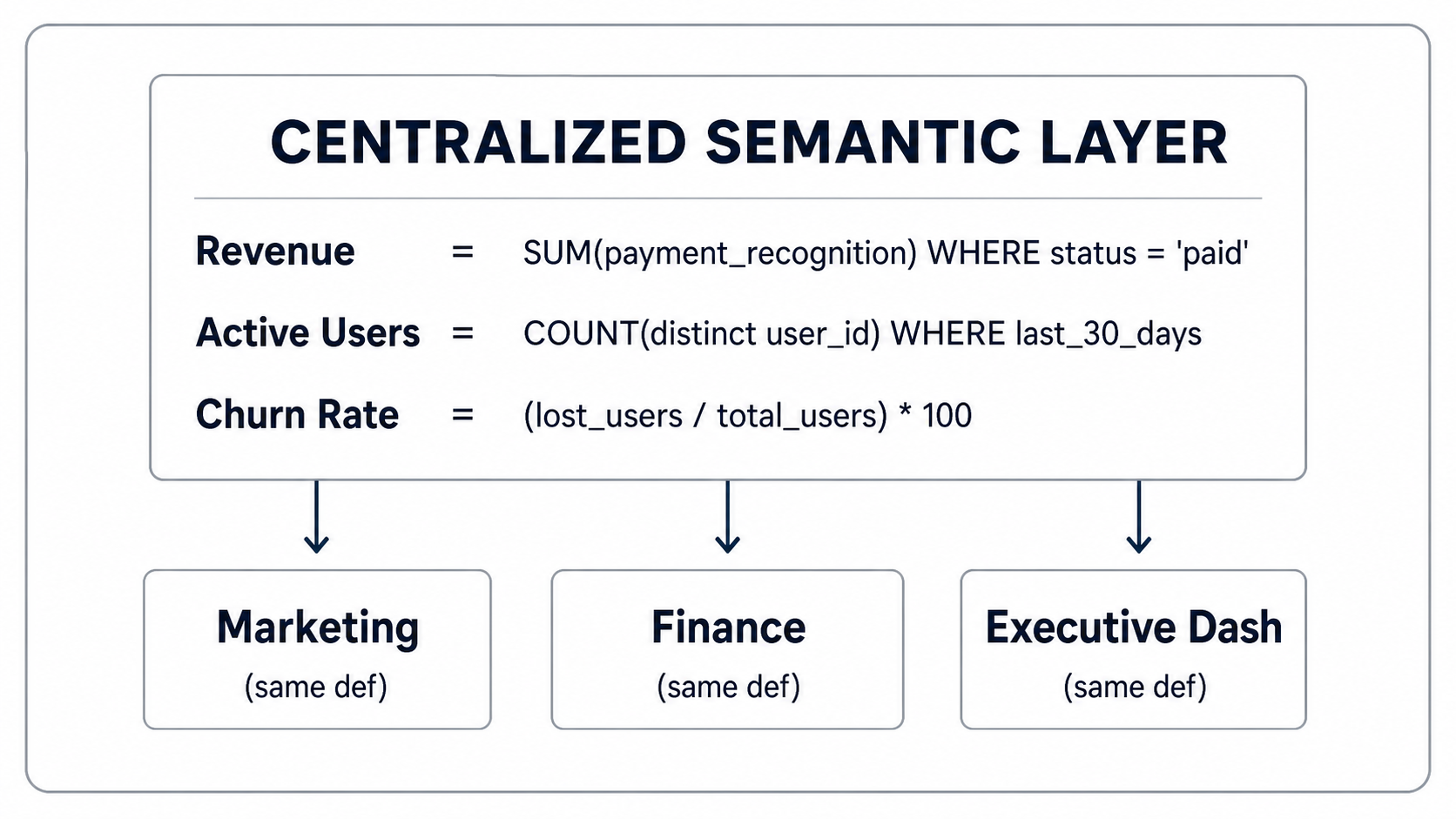
When everyone uses the same semantic definitions, numbers align. Trust returns. Decisions happen faster.
What to Fix?
- Define business metrics once in a centralized semantic layer
- Enforce those definitions across all reporting tools
- Document the logic in a central place like Confluence so anyone can trace how a number was calculated
Sign 3: Your Governance Lives in a Document That Nobody Reads
You have a data governance policy. It is a .docx and .pdf file sitting in a SharePoint or Confluence site. No one has opened it for a very long time.
Meanwhile, your team is manually handling access requests to the data, and imagine that someone forgot to tag the sensitive data, and the team has no idea which downstream systems are consuming PII data.
Governance in 2026 is embedded in the architecture, not sitting in a document somewhere. Real governance is not something about people remembering to follow rules. It's about the systems that automatically enforce them.
Old way (broken):
- Policy documents
- Training sessions
- Manual access reviews
- Periodic audits
Modern way (embedded):
- Automated lineage tracking
- Active metadata that tags sensitive data
- Policy enforcement at the query level
- Continuous compliance monitoring
Embedded Governance
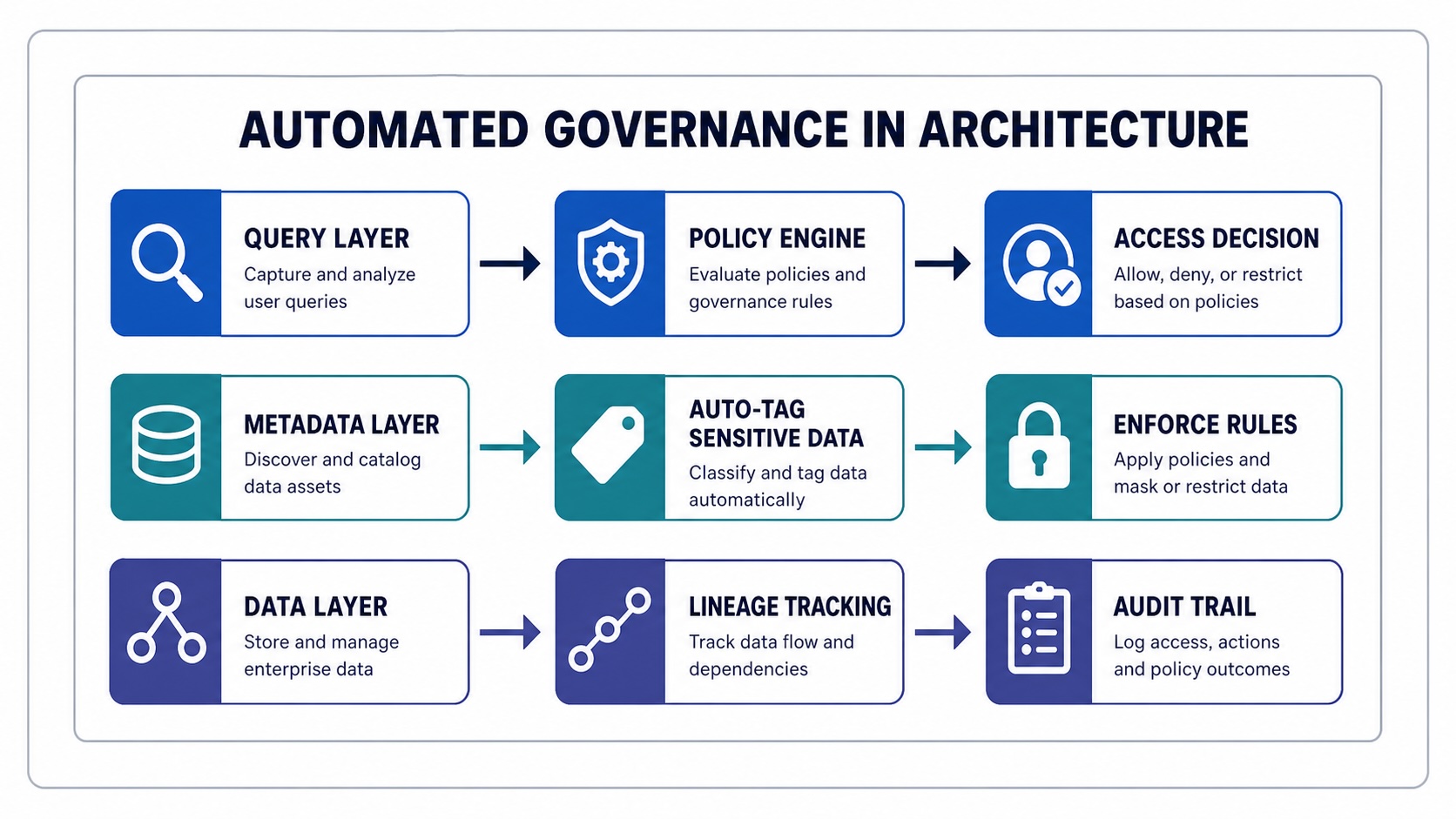
Every query is getting checked against policies. Sensitive data is getting tagged automatically. Lineage is being tracked without human input, and governance happens by design, not by reminders.
What to Fix?
- Move governance from documents to code (policy engines, access controls)
- Implement active metadata that automatically tags and classifies data
- Build lineage tracking into your pipeline tooling
- Enforce policies at the query layer, not as a post-check
Sign 4: Security Was Designed for Humans, Not for AI Agents
Your security model works great for analysts querying dashboards, data engineers running pipelines, and Data scientists building models. But here is what it was not built for -> "AI Agents" that query your data autonomously, all the time, at scale, without a HITL (human-in-the-loop).
The New Access Pattern
Old access:
- Human queries the data
- Human reviews the output/results
- Humans decide what to do with the results
AI agents access:
- Agents query the data continuously
- Agents processed 1000's of rows automatically
- Agents make decisions without a human reviewing them
- Agents scale across multiple data sets
The Security Gap

If your security model assumes humans are always involved, you end up with a growing security gap.
Security for AI Agents
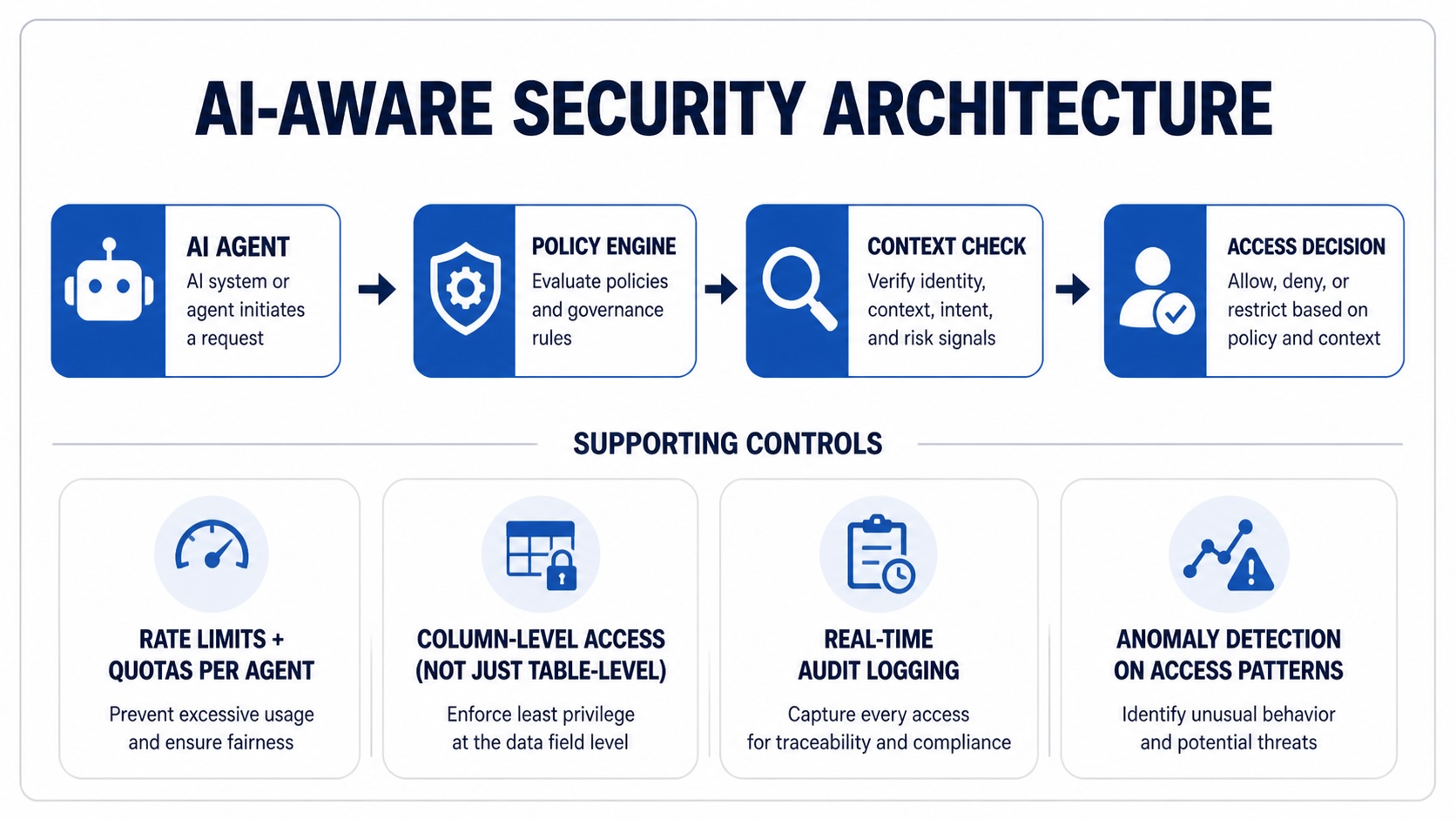
You need fine-grained, policy-driven security that works for both human and machine users.
What to Fix?
- Implement column-level security (not just object-level)
- Add rate limits and quotas for AI agents
- Log all access in real time with anomaly detection
- Use context-aware policies that consider the query intention, not just the user role
Sign 5: A New Engineer Needs Months to Understand the Architecture of the System
A new data engineer joined your team. They are smart, experienced, and highly motivated. But after 2 months, onboarding is complete, they still can't confidently answer "Where does this metric come from?" or "What happens if I change this part in the pipeline?"
Do you think it is a hiring problem? No, certainly not. It's an architecture problem.
Great Architecture Is Maintainable
If onboarding an engineer takes longer than it should, the design is the issue, not the engineer. Here are the red flags that you should pay attention to.
Red flags:
- No clear data modelling standards
- Missing or incomplete metadata
- Poorly defined ownership (who owns this table?)
- Fragmented pipeline design (no standard/consistent pattern)
- Documentation that is missing or outdated
Maintainable Architecture Principles
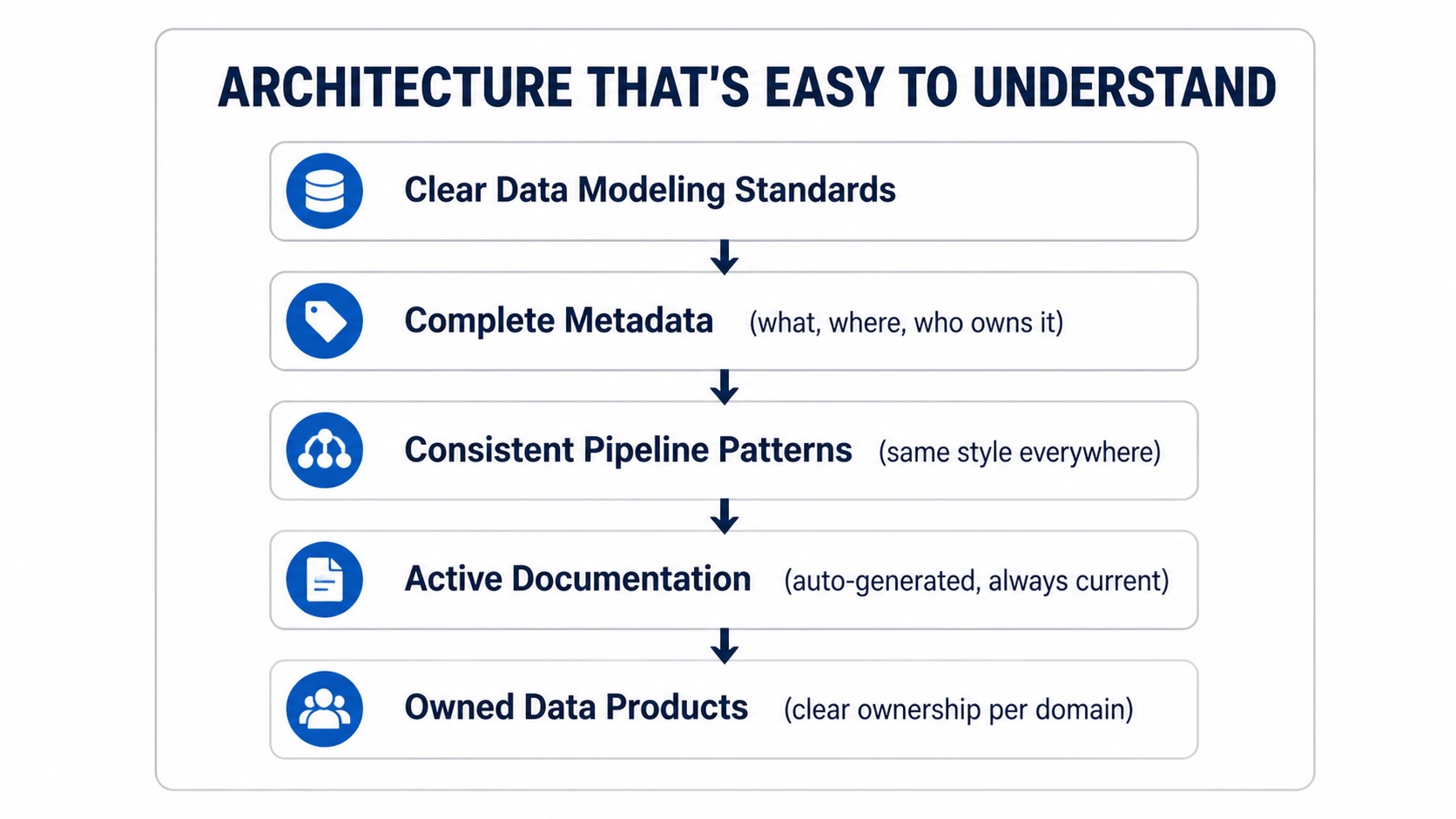
When these are part of your architecture, new joinees can navigate the system in weeks instead of months and follow it easily.
What to Fix?
- Standard data modelling across the organization
- Generate metadata automatically (Don't depend on manual documentation)
- Use a consistent pattern for pipelines (Same design, same tools, same naming standards)
- Assign clean ownership for every data product/data domain
- Auto-generate documentation for newly created pipelines/code
The fundamentals never change, but the layers around them have. After working for 20 years in this space, I have noticed that the core principles of data architecture remain the same.
What never changes:
- Data modeling
- Schema design
- Aligning with business outcomes/requiremnts
What has matured over time:
- Governance (embedded rather than document-driven)
- Metadata (became active from passive)
- Semantic layer (A centralised one, not scattered across)
- Security (AI-Aware, not human only)
- AI readiness (architecture first, not model first)
If these modern layers are missing from your architecture, now is the time to add them. Not when AI initiatives stall, not when executive leaders lose trust in the data, not when your best engineers quit because the system became too complex.
Which Sign Resonates Most With You?
I have worked with companies that have faced all five of these signs. Some are dealing with one. Most are dealing with three or four.
The question is not whether you have these problems. The question is: which one is costing you the most right now?
- Is it AI initiatives that can't move forward?
- Is it teams that can't agree on basic metrics?
- Is it governance that exists only in a document?
- Is it a security gap that you're discovering too late?
- Is it engineers who can't navigate your architecture?
Pick the one that's most urgent and start there. You don't need to solve everything at once.
But do start. Before the warning signs become breaking points.
Opinions expressed by DZone contributors are their own.
Comments