Data Contracts as the "Circuit Breaker" for Model Reliability
AI models do not fail due to bad coding; they fail due to an upstream change in the input. Combine contracts with circuit breakers to stop bad data from entering models.
Join the DZone community and get the full member experience.
Join For FreeIntro: When Good Models Go Wrong
A few years ago, I spent months working on a microservices-based customer intake processing system for our application. The code was good, the tests were passing, and we had load-tested it with crazy high TPS. Yet, on one particular Tuesday afternoon, a small change to the response schema from an upstream service, where the date field changed from ISO 8601 to epoch milliseconds, cascaded through four downstream services and corrupted a day’s transactions without anyone realizing it until it was too late.
We fixed it in a few hours, but the lesson has stayed with me, and it’s affected every integration I’ve worked on since then. Crashes are easy to see. Silent data corruption is not.
I see the exact same thing happening with AI and machine learning pipelines today. Except now, the consequences are larger, and the feedback cycles are slower. A model will not throw an exception if the input schema changes slightly. It will, however, make worse predictions. Quietly. Confidently. For weeks.
In this article, I’d like to propose a solution that brings together two worlds in which I’ve spent my entire professional life: software engineering’s resilience patterns and data governance. What I’d like to argue is the need to combine the concept of data contracts with the Circuit Breaker pattern to build a proactive defense against silent data quality failures that affect AI reliability.
The Real Reason AI Models Fail in Production
There’s a general understanding that if a model is not performing well, it’s a problem with the model itself, its architecture, its hyperparameters, the training process, etc. Sometimes this is true, but far more solvable.
The upstream data changed. Nobody told the model.
“Poor data quality is a silent killer of any AI projects.” This is consistent with many production environments. The data engineers did their job, the modelers did their job, and nobody owned the contract between the two.
This might manifest in a number of ways:
- Schema drift: A column that has always been a float type now starts arriving as a string type. The feature engineering process, quietly and behind the scenes, attempts to convert it and introduces some error in the process.
- Semantic drift: An attribute named "account_status" that previously only had values such as "ACTIVE", "CLOSED", and "DELINQUENT" now starts having a new value, "UNDER_REVIEW", that the model has never seen before. The model maps it to the category that it is closest to in the embedding space, which could be completely incorrect.
- Distribution shift: The data source the model uses changes how it samples data or alters other aspects of the data. The model is now seeing a different data distribution than it was previously trained on, and the schema looks exactly the same. So, nothing appears to have changed.
- Cadence changes: A data source that is a batch source and has historically refreshed data every day now starts refreshing data every hour, or vice versa.
A 2023 Gartner study found that the primary cause of AI project failure is poor data quality, and more than 60% of organizations reported that data issues, rather than model issues, were the primary cause of most of their production incidents.
The diagram below shows the silent changes in the data and how they propagate through the machine learning pipeline.
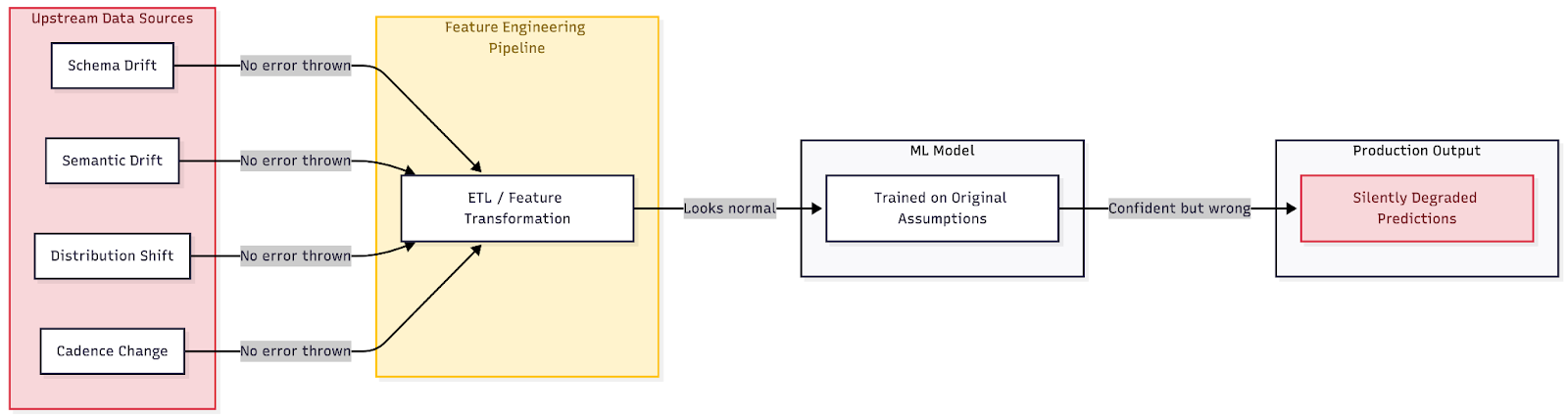
Data changes upstream will flow through the pipeline without error, producing confidently wrong model outputs that will go undetected for weeks.
The fundamental issue here is that there is no contract between data producers and data consumers. In a microservices world, we solved this problem a decade ago through API contracts and schema registries. In a data world — and this might sting a little — we're still operating on trust and hope.
This is a data governance and data quality issue. And the good news is that the data management community has a conceptual toolkit to solve this problem. We just need to integrate it into the AI pipeline.
What Are Data Contracts?
Most teams believe they have data contracts. In reality, they have documentation with good intentions. A wiki page with "this field is supposed to be a float" or a Slack channel where someone will ask, "Hey, did the schema change here?" A data contract is not documentation. A data contract is enforceable, but documentation is not.
A real data contract is an enforceable agreement between two parties: the producer (the system or team that produces the data) and the consumer (the system or team that consumes the data). A real data contract is an agreement that includes:
- Schema: The exact structure, data types, and allowed values for every single field.
- Semantics: What each field means, including business definitions and edge cases.
- Quality: Minimum quality thresholds for completeness, freshness, accuracy, and uniqueness.
- SLAs: Service level agreements for delivery cadence, latency, and availability.
- Versioning: A definition for schema changes, including deprecation schedules for backward-incompatible changes.
It’s like thinking of it as a data API specification. Just as OpenAPI (Swagger) has standardized how we specify a REST API, data contracts have standardized how we specify a data interface.
It’s a concept that’s been getting a lot of traction among the DataOps community. Andrew Jones has been a prominent influencer in formalizing data contract specifications, and tools like Soda and Great Expectations provide frameworks for data quality expectations, which are part of a data contract.
The importance of AI is unparalleled, as every ML model relies on a set of data assumptions that are not only unspecified but also unenforced. When those assumptions are violated, the model starts to deteriorate. A data contract spells out those assumptions, making it testable and enforceable — bringing the level of rigor that data stewardship teams have been advocating for, into the ML pipeline.
The Circuit Breaker Pattern: A Primer
You already know what a circuit breaker is; there is one in your house. It works by tripping and shutting off the electricity if the load gets too high. You simply flip it back on to restore service. Simple, elegant, and has saved many houses from burning to the ground.
The concept of circuit breakers has been around for a long time in software development, popularized by Michael Nygard in his book “Release It!” It has been a standard pattern for building resilient distributed systems. I have been using this concept for a long time. We use Spring Cloud Circuit Breaker based on Resilience4j to handle circuit breakers for our microservices-based application to prevent cascading failures in downstream services, which are very critical to business.
The circuit breaker works as follows:
- Closed state – this is the normal operating state. All requests go through to the downstream service. The circuit breaker is monitoring the failure rate.
- Open state – this is where the circuit breaker has detected a failure rate above a certain threshold. It has “tripped” and will stop sending requests to the downstream service. Instead, it will immediately send a fallback response or error.
- Half-open state [recovery probe] – after a cooldown period, the breaker allows a limited number of test requests to pass. If they are successful, the breaker closes; otherwise, it stays in the open position.
State machine for circuit breaker here^; the circuit breaker changes states based on failure rates and recovery probes.
This pattern has become accessible to every Java developer with the introduction of frameworks such as Spring Cloud Circuit Breaker and Netflix Hystrix. The pattern is simple but very useful. It’s all about failing fast.
We have been using this pattern for service-to-service communication for more than a decade. We have 100s of our services with a circuit breaker pattern implemented on our platform. If our XXX critical service goes down, we simply trip the circuit breaker and fail gracefully. But if our upstream data source changes schema silently and starts corrupting our ML features? Nothing. No circuit breaker. No fallback. Just a degradation of our features for weeks. The failure mode is the same: a degraded upstream service silently corrupts a downstream service. But we didn’t have a similar pattern implemented for our data pipelines until we did.
Applying the Circuit Breaker to Data Pipelines
The basic idea is not as complex as it sounds: we propose that every data input to an AI model is a dependency that can cause a circuit breaker to trip. If we do this with HTTP calls to other microservices, we can do this with data going into a model.
While a traditional microservice circuit breaker monitors HTTP request error rate and latency, a data circuit breaker monitors data quality metrics defined in the data contract:
|
Circuit Breaker State |
Trigger Condition |
Action |
|---|---|---|
|
Closed (healthy) |
All contract quality thresholds met |
Data flows normally into the model pipeline |
|
Open (tripped) |
Quality metrics breach contract thresholds (e.g., null rate > 5%, freshness > 2 hours stale, schema mismatch detected) |
Data flow is halted; model receives no new input; fallback strategy activates |
|
Half-Open (probing) |
After cooldown, a sample batch is validated against the contract |
If the sample passes, the breaker closes; if it fails, the breaker stays open |
The fallback options when the breaker trips can be:
- Stale but safe – using the last known good data snapshot. The model will continue to run, just on slightly outdated, but still good, data.
- Graceful degradation – the model will continue to run, but flag its output as "low confidence" and send it to a human for review.
- Full halt – for high-stakes applications like fraud detection or compliance, the model will simply stop running until the data quality is resolved.
This is a fundamental shift from "we'll detect the problem when it happens and send an alert" to "we'll prevent the problem from happening in the first place."
Architecture: Data Contracts + Circuit Breakers in Practice
Let me walk through a concrete data architecture that ties these patterns together. This is heavily inspired by how we operate this on our lending platform, but adapted for the data to model case:
The Data Contract Registry
A centralized service responsible for storing all active data contracts. Each data contract is versioned and associated with a data source and a consumer. The service provides APIs for:
- Registering a data contract
- Validating data against a data contract
- Publishing a data contract violation event
The Quality Gate
A lightweight service (or a 'sidecar' pattern, if you will) that sits in between the data source and the model pipeline. For every data batch or stream event received, the quality gate:
- Fetches the relevant data contract from the registry
- Validates data against schema, semantics, and quality rules
- Reports metrics to the circuit breaker
The Circuit Breaker Controller
A stateful component that:
- Aggregates quality metrics from the quality gate over a specified window size
- Manages the breaker state (closed, open, half-open)
- Publishes state change events to a Kafka topic for downstream consumption
- Executes fallback strategies when the breaker is opened
The Flow
The architecture is an end-to-end solution that includes data contracts, quality gates, and circuit breakers. The circuit breaker is located between the quality gates and the model pipeline, automatically routing to fallbacks if the quality of the data worsens.
If you are using AWS, which we are, then this architecture fits nicely with existing AWS services. For example, the quality gate can be performed by a Lambda function or ECS task, the contract registry can be on DynamoDB or other AWS-native datastores, the circuit breaker state can be maintained by ElastiCache (Redis), and the event bus can be on Kafka (or MSK, the AWS variant).
We already make significant use of all these tools for our financial platform microservices, so the marginal cost for using them with the data pipeline is negligible. If you are using Kubernetes, then the quality gate can also function nicely as a sidecar container to your model serving pods.
The key architectural concept is the separation of concerns. The data producer is responsible for the data contract, the quality gate is responsible for the quality, and the circuit breaker is responsible for the fail-fast. There is no need for a single team to “own” the entire process.
From Chaos Engineering to Data Resilience
The last time I intentionally broke my data pipeline and saw what happened was?
On our system, we do disaster recovery drills regularly — an orchestrated set of exercises on 100+ components, including APIs, batch jobs, and streaming apps. The team is very good at infrastructure chaos engineering.
However, when I asked, “What happens if the credit bureau feed starts sending garbage schema for two hours?” nobody answered because nobody had ever really tested this scenario. Most organizations practice chaos engineering on infrastructure, but very few practice data chaos engineering — intentionally introducing data quality errors to see if their systems correctly detect and respond to those errors.
Data Chaos Engineering in Practice
- Schema injection: Apply a schema modification temporarily, for example, by adding a column or changing a data type. Validate that the quality gate detects this modification and the circuit breaker is triggered.
- Null injection: Increase the proportion of null values for a critical feature beyond the contract value. Validate that the breaker is triggered.
- Staleness simulation: Apply a delay in the data delivery beyond the SLA value. Validate that the staleness check is triggered.
- Distribution poisoning: Apply a small perturbation to the distribution of a critical feature. Validate the detection.
The data chaos engineering cycle. Here, faults are injected to ensure that the contracts and breakers are functioning correctly. The missing pieces are fed back into the contract and breaker development.
I have seen that by running these experiments every month, taking the same level of discipline that we already take in running our existing DR drills for our services, instills enormous confidence in the system's ability to look after itself. It also reveals missing pieces in your data contracts that you might never find by just reviewing your documentation. If you introduce a fault and nothing catches it, that means your contract is incomplete. We learned that we had three missing contract clauses just by running data chaos experiments for the first month.
The principles of chaos engineering are applicable in this case. You are not testing if your system works under perfect conditions; you are testing if your system fails safely under realistic, degraded conditions.
Real-World Scenario: Stopping a Bad Prediction Before It Ships
For example, a financial services company might use ML models to predict customer behavior for risk analysis. The ML model might use various data sources as features, such as an external third-party data provider for customer risk indicators.
The scenario:
A third-party vendor changes their API and doesn't notify anyone. A critical field in the data set now returns numeric data instead of categories. The field previously returned HIGH_RISK, MEDIUM_RISK, LOW_RISK, and MINIMAL_RISK categories, but now it returns numeric data between 1 and 100. The ETL process doesn't fail but defaults to a mapping of the data, which essentially flattens all the risk into a single category across all customers.
Without a data contract and circuit breaker:
The model runs for weeks with corrupted features. Predictions are no longer accurate, but the gradual change is mistaken for market conditions or seasonality. By the time the actual cause is determined, thousands of decisions are made based on incorrect predictions. The process to address the problem involves several teams working in war rooms over the course of days, analyzing logs and assessing the damage, a considerable engineering and possibly business waste.
With a data contract and circuit breaker:
The data contract is very specific in that it requires the risk indicator field to contain one of four string values. If the vendor changes the format of the API, the quality gate immediately recognizes that the data is not passing the semantic validation. The circuit breaker is triggered within minutes. The system defaults to the last verified snapshot of the data and flags all predictions as "Degraded Confidence." An alert is sent to the data engineering team. The schema is fixed within hours, and zero corrupted predictions are ever made.
The speed is a secondary benefit, the actual value is in the prevention of damage (as a preventative control rather than a detective). The circuit breaker prevented the bad data from entering the model before the corrupted prediction was ever made.
FAQs
What is the difference between a data contract and a schema registry, e.g., Confluent Schema Registry?
A schema registry will verify structure, e.g., field names, data types, and nesting. A data contract extends that with semantic rules, e.g., allowed values, definitions, quality rules, e.g., nulls, freshness, and SLAs, e.g., delivery cadence, availability. In other words, the schema registry is just part of the data contract.
Won't triggering circuit breakers cause the model to stop working too often?
This is not a fundamental flaw; it's just a calibration issue. People often underestimate the amount of variation that is normal in their data. We did. Start with large values, then adjust them once you know your data's normal behavior. The half-open state helps with recovery. In practice, circuit breakers will not often fail, and when they do, it's likely due to real issues.
Does this apply to real-time streaming data, or is it limited to batch data?
Both. For streaming, the quality gate checks every event or micro-batch. The circuit breaker aggregates metrics over a time window. For batch, the quality gate checks at the batch level, prior to writing to the feature store. This pattern is unaware of the delivery mechanism.
What about unstructured data, like text and images?
For unstructured data, like text and images, the data contracts are concerned with other quality aspects, like encoding, language, document size, and metadata. The Circuit Breaker still applies, just to other metrics. For example, in an image processing pipeline, if 90% of the images received are 90% smaller than the average, it could be a sign of corrupted images or thumbnail images only.
How do I get data producers to adopt contracts?
Start with the highest value, highest risk data sources. Present it in the context of reducing their support load. The producer team is interrupted every time a consumer reports a bug because of the change in the data. I have been in enough cross-team incident reviews to know that these interruptions are not popular. Contracts remove the need for these interruptions. Once one producing team has adopted contracts and seen the reduction in downstream incidents, the rest tend to spread naturally. We began with a data feed and now have contracts in place for our most critical internal data sources.
Conclusion
The data engineering community has spent years developing ever-more sophisticated monitoring, alerting, and observability tools. That's all been good work. But let's be honest: monitoring is fundamentally reactive. Monitoring just lets you know something's gone wrong... after the damage is done. You want monitoring and prevention, but only prevention will stop the damage before it happens.
Data contracts and circuit breakers are a fundamental shift in data resiliency: Contracts make the expectations explicit. Circuit breakers make those expectations active, in real time, before the bad data ever gets to the models and agents that rely on it.
When building AI systems that make critical decisions... and increasingly, all of us are doing this... You simply cannot operate on implicit trust between data producers and data consumers. The chasm between "the data exists" and "the data is fit for purpose" is where model reliability goes to die.
The data governance and data quality practices that this community has advocated for over the years are precisely what you need. And now, taking them to the AI layer is what's next.
Bridge the gap. Write the contract. Wire the breaker. Start with one data source, the one that has burned you before. You know the one. Your models will thank you.
Key Takeaways
- The cause of AI system failure is data, not code. The most common cause of production AI system failure is a change in data schema or semantics, which degrades model predictions silently.
- Data contracts make data producer and consumer expectations around schema, semantics, data quality thresholds, and SLAs explicit, making implicit assumptions explicit and testable.
- The Circuit Breaker pattern stops bad data from being fed to a model by automatically stopping data flow when data quality thresholds are violated, allowing for fallbacks to be implemented.
- Data chaos engineering makes you confident that your data contracts and circuit breakers will work when your data quality actually fails by intentionally inducing data quality failures.
- Target high-value, high-risk data sources first. Success in one area can generate enough organizational momentum for wider application.
Opinions expressed by DZone contributors are their own.
Comments