Data Modeling With Tables and Documents vs. Redis Structures
In the past, database approaches have required the translation of your data model design to the underlying data modeling language of the database. Redis reverses this.
Join the DZone community and get the full member experience.
Join For FreeToday, there is no shortage of databases to choose from (in fact, there's over 250 according to db-engines). Some of these databases were created in the era of mainframes and are still alive; others have adapted to emerging hardware; many have assumed that Moore’s Law would perpetuate and are built for scale-up; and others have adapted to the cluster of commodity nodes utilizing scale-out.
Whichever happens to be your database of choice, they all provides a data model for you to express your data concern to the database. The data modeling language of your database is a binding contract between you and the database. This binding contract governs how you interact with your data in the database. The binding contract is also engraved deep into the core DNA of the database. It is fundamental and foundational to your databases identity.
What does that binding contract look like?
Relational databases: tables. Rows and columns are the way to express your problem in RDBMS. This works for some problems, but we know where this falls short; normalization practices kill performance and Agile apps can’t change this schema easily. These rigid forms don't allow changes to the schema to occur easily.
Document databases: JSON/XML. Documents can let you express data in human-readable forms, but they are quite verbose. The repeated attributes kill efficiency. They are also hard to use when you have to express more complex relationships with many-to-many complexities.
Key/value databases. These work well when you need a simple
GET/SETaccess method, but it falls short when you want smarter data access with server-side logic. The coarser-level access requires too much data to be moved back and forth. Imagine retrieving 100KBs of compound value just to retrieve a bitfield!
The point is that each approach is good for a subset of your problems — but not for all of your problems. Trying to fit problems into a single generic data type that your database understands is limiting. It is limiting when you're designing your data model. It is also limiting when you're trying to build high-performance applications. The constant translation of the abstractions back and forth and the bending of your design to the common denominator data structure that the database supports wastes computational capacity. It can be the difference between a $20K/month cloud bill vs. $80K/month.
Modeling Interactions With Your Data
Let's put aside data modeling for a second.
Look at the outline of a city. There are libraries and there are movie theaters, there are high rises and there are single family homes, there are hospitals and there are shopping malls... we shape and decorate each building to increase the efficiency of human interactions. We optimize the structure to maximize the way we want to assemble for the job at hand. The layout of the building is critical to efficiency the success of human interactions within it.  When you want to optimize how you interact with your data, a single structure (table, document, key-value) is not optimal, either. Some interactions with your data work well with tables; others may need documents. Some need key-value or graphs, time series, or indexed structures such as a B-tree, a skip list, or a full-text index. It would not make sense to build a single structure for all interactions. Why bend all your data into one structure?
When you want to optimize how you interact with your data, a single structure (table, document, key-value) is not optimal, either. Some interactions with your data work well with tables; others may need documents. Some need key-value or graphs, time series, or indexed structures such as a B-tree, a skip list, or a full-text index. It would not make sense to build a single structure for all interactions. Why bend all your data into one structure?
Modeling Data With Redis
Redis takes a completely different approach. Redis provides data structures and “verbs” (or methods) with each structure to allow you to natively interact with them. Redis' full list of data types includes key/value, sets, lists, hash tables, sorted sets, bitfields, geo, and more. Redis modules allow anyone to add more types in directly into the Redis engine.
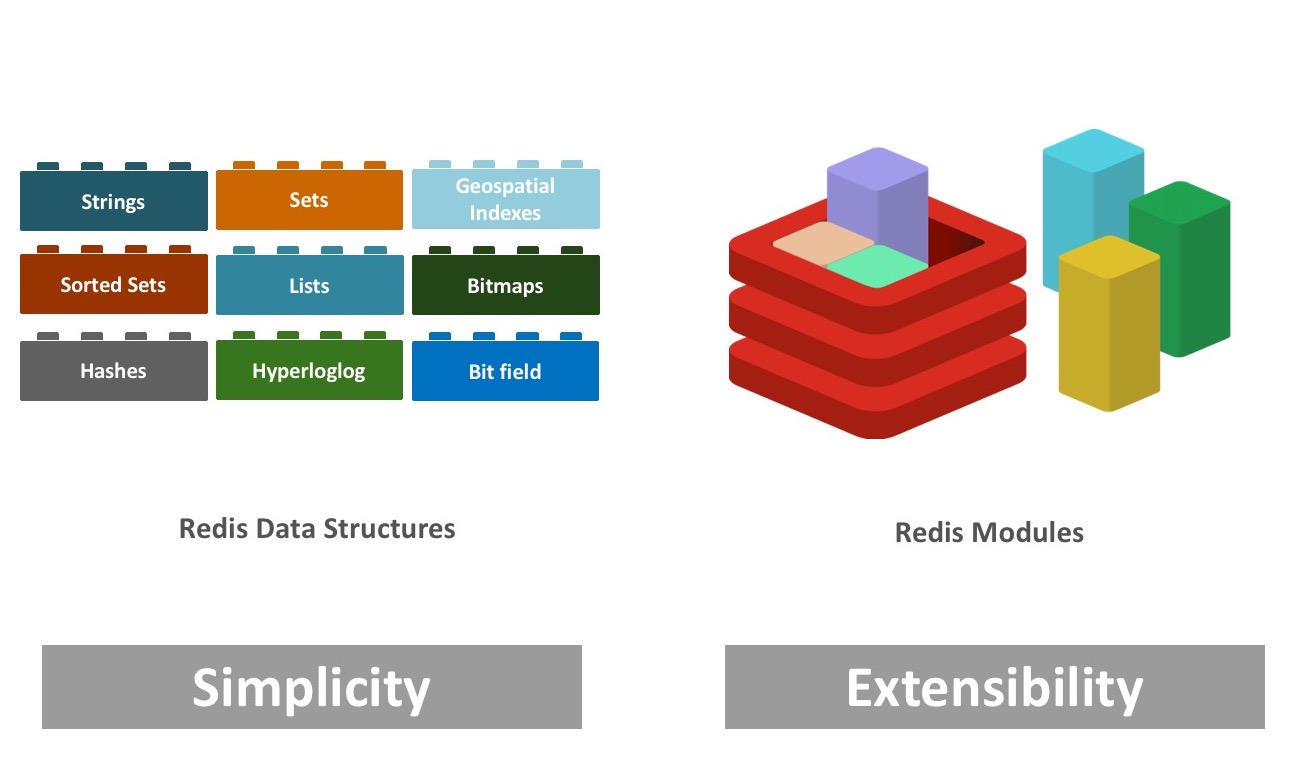
When modeling data with Redis, you need to pick the data type that best suits the needs. In each database, you can combine hash tables, documents, sorted sets, bitfields, geo-structures, etc. You are not constrained to one underlying type. For example:
Sets can be used to house collections like tracking a shopping cart. SADD key member [member] allows you to add new items to the cart. Use other methods like SCARD key to find out how many items are in the shopping cart.
Hashes maintain table-like structures, like fields and values under a key. If you are storing a user profile with many attributes like age, sex, and nationality to the user's preferences, you use HMSET key field value [field value ...] to add a new user. You can then use HSETNX key field value to update a field in the user attributed.
Instead of the single, common denominator data type, Redis provides native options.
This approach is similar to frameworks and libraries that come with your favorite programming language. Java does not ask you to model your objects using the same underlying data structure. Imagine others; Python's collections or C#'s System.Collection gives you lists, sets, dictionaries, and more. You get to choose the data types that fit your app logic best. You can have the same experience in Redis. Except in Redis's case, types can operate on the server side with higher performance in a distributed scalable and highly available cluster with tunable durability, persistence, consistency, and atomicity guarantees.
Modules in Redis
Redis 4.0 is coming soon (the first RC is already out) and with it, Redis will support modules. Modules allow custom types and methods to be built by anyone. The modules are loaded into the engine and expose their own types and methods. You can find modules on modules hub or GitHub. There are many that are built by community and Redis Labs, the company behind Redis, that serve many purposes — i.e. secondary indexes, full-text search, graph processing, time-series, and enhanced JSON handling with Redis.
Unlike other extensibility models, however, modules do not translate their data into some other type that the database understands. Modules let you embed your logic directly into the kernel of the database. The Redis approach avoids translations and abstractions and keeps Redis highly performant.
Data Modeling With Redis Structures vs. Others
In conclusion, approaches provided by databases in the past have required the translation of your data model design to the underlying data modeling language of the database. Redis reverses this. Redis allows you to combine all data types to model your data concerns without having to stick to one underlying data structure. You model with the best structure that works for your app's problems. With modules in Redis 4.0, the options expand to data types and their methods beyond what the core provides.
Opinions expressed by DZone contributors are their own.
Comments