Data Platform as a Service
When we design and build a Data Platform, we are working on providing the capacities and tools that others teams need to develop their projects. Let's discuss!
Join the DZone community and get the full member experience.
Join For FreeIntroduction
It's been a few months since I was thinking about writing "What's a New Enterprise Data Platform?" In the last few years, I've been working as a Data Solution Architect and Product Owner for a new data platform; I've learned a lot and I would like to share my experiences with the community.
I'm not going to write about the Data-Driven approach, but how to build a platform that allows a company to implement it. When we design and build a Data Platform, we are working on providing the capacities and tools that others teams need to develop their projects. I am not forgetting the data but I think the data should be a service, not a product.
I've read a lot about the next generation of data platforms before this challenge (I'm always reading..). Usually, the architecture blueprint references the ideal architecture and it's okay. But the real world is not perfect. In a big company, there are different realities so it is important to correctly identify the company priorities and at the same time focus on the "To-be" (this is the hardest part). It's also very important to remember that it doesn't matter that we have the best architecture if nobody uses it or we are two years late.
In my opinion, there are four principal pillars that we have to consider from the beginning:
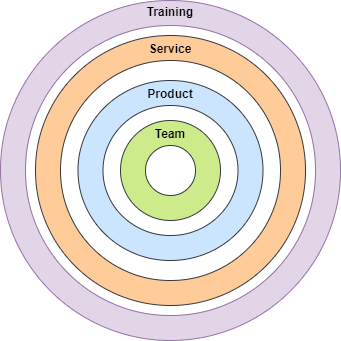
- Team: It is the most important and has the most impact in ensuring your success.
- Product: It is the platform, all the features, and capabilities that we'll offer to the user.
- Data as a Service: Allows you to deliver value to the users by facilitating outcomes that the users want to achieve without significant effort and cost.
- User training: It is another service but it is important enough to be highlighted independently.
At the end of the day, the product will be the union of all of them.
Product Oriented
There are a lot of features that an Enterprise Data Platform has to provide: Data Democratization, Data Catalogue, Data Quality, CI/CD, Monitoring, etc. The only way to provide these features in an enterprise environment is by following a product-oriented approach what it means:
- Listen to the potential users and try to understand what their needs or experiences are.
- Define the long-term goal of the product (the big picture)
- Use cases at a high level.
- The most important and common features.
- The building blocks that will compose the Data Platform, will be the product family.
- Simplify the services and make it easier for our customers to achieve their objectives. We will explain some of them further.
- Share with the users and get the initial feedback.
- Plan a minimum viable product.
- Follow the agile manifesto and the continuous improvement model.
- Roadmap visibility, get regular feedback from the users.
We must provide value to our users from the very beginning and at the same time get regular feedback. Users' needs are not static and change continually so don't worry if the long-term goal changes from time to time even in the beginning it could change often. A Data Platform must continuously evolve, change is part of the platform's life cycle.
On top of these, I've always followed three main principles that apply to Hybrid architecture and Cloud-native as well:
- Ingest the data only once.
- All teams have access to the same data.
- Separate compute and storage layer as much as possible.
- Avoid spaghetti architectures.
What happens with Data as a product? Of course, it is so important but is not a part of the Data Platform. I think is on top of the Data Platform.
Data as a Service
Nowadays, time is more important than ever (Speed-to-market). Avoiding core teams that centralize the management of data pipelines or platform provisioning is a must. The centralized team doesn't work; they'll end up in a bottleneck. There will be more tasks than they can manage. In the end, the entire company will submit requests to a single centralized team.
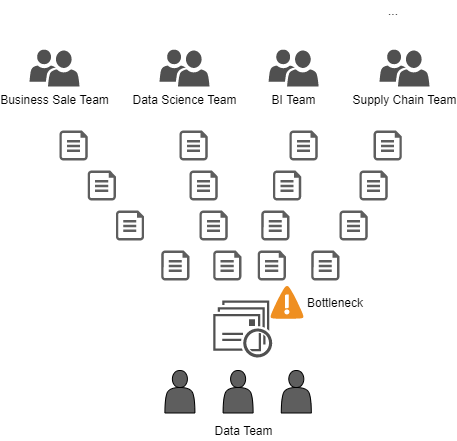
These situations generate user dissatisfaction and team frustration as well:
- The user can not achieve his goals.
- The team makes the best effort but they can not manage all the requests.
Instead of that, provide self-service capabilities that allow the users have several options:
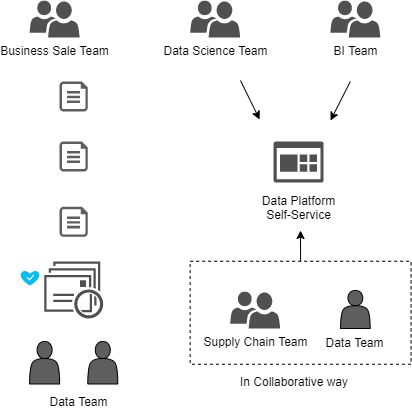
- Do it themselves.
- Provide a centralized team for business users; in this case, automation is very important. Not everyone can work autonomously, there are business teams that use reporting features and need a team to provide them with a service.
- In a collaborative way, support mixed teams although in the beginning, it requires a lot of effort in the long run will help a lot. It also encourages team collaboration and knowledge sharing.
What self-service capabilities should we provide? There are three essential needs:
- Users need to know what data is available and all the metadata related. For instance, allow them to look for tables, the lineage, and the refresh time of these tables, schema, business definition, etc.
- Provide a simple data ingestion engine that allows technical users to ingest their data autonomously.
- Observability to provide all the information that users need to monitor, orchestrate their process, etc.
In the end, we should automate processes as much as possible and provide an easy way to make them accessible to the users. This could be through git-ops, a website, or some other way.
The Team
People are the most valuable pillar of your Data Platform. An Enterprise Data Platform needs different sub-teams with different skills:

- DataOps: Of course it is not a team but a combination of cultures and practices. It's important to have a team that understands all these concepts and also soft skills. It requires knowledge about data engineering, data integration, and data quality. This team will be the ones who are most close to the user.
- Providing data to the Data Platform to be consumed by the users.
- Providing support for issues.
- Providing support for integrations.
- Helping in the data process optimizations.
- Helping to understand the data.
- Data Engineers: They are responsible for building the core of the Data Platform. It is a very technical team with knowledge of SQL, Streaming, Spark, and other technologies.
- Create and automate data reliable pipelines based on batch or streaming.
- Design the data organization and the data layers (raw, refined tables, feature..).
- Architecting data stores.
- Transforms data into a useful format for analysis.
- Technology research to improve the current and upcoming features.
- Software Engineers: They are important because of their build self-service capabilities and other features. Software engineers are needed to work on the backend website portals, data services based on OpenApi, WebSocket, etc.
- Front-end Engineers: There are varied kinds of users in the data platform. It is important to provide everyone with a good user experience through user-friendly tools such as self-service web portals. Front-end engineers work on navigation web process, designing the user interface, and develop part of the web application.
- Platform Engineers: One of the keys is to automate the provision of the platform and the operation, sometimes this kind of team is called DevOps even though we consider that DevOps is a culture like DataOps. The platform engineers must work together with Data Engineers and Software engineers.
- Design, develop, and evolve infrastructure as code.
- Design, develop, and evolve CI/CD solutions.
- Help with data processes optimizations providing a platform view.
- Solution Architect: Is the person in charge of leading the overall technical vision aligned with the needs and requirements defined by the Product Owner.
- Product Owner: Defines the goals, helps the team to maintain the vision, etc.
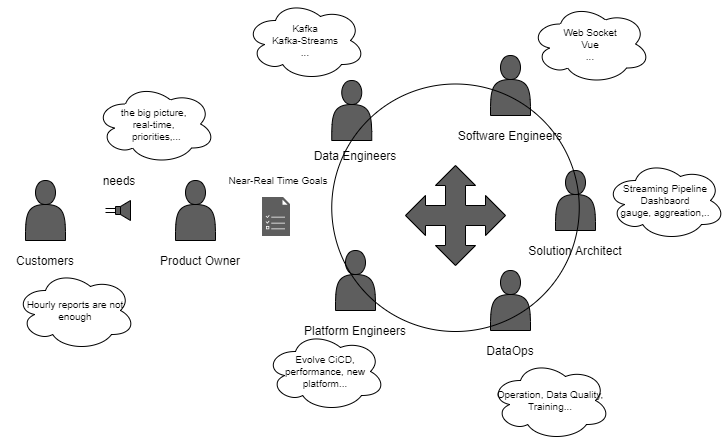
There are several teams involved in the data platform and all of them have to work together following DataOps and DevOps culture. All the people must work from time to time in each other's team. The quality and the high availability features of the product are a combination between the platform and the processes/applications, so all the team should work together and be aligned.
User Training
When we design a new platform, there are always new technologies; not only that, there are also new processes and methodologies. Because of that, training is very important. It will help to have an easy adoption from our users.
The usual training (4 hours in the morning lead by a trainer) is nice but, in some cases, it is not enough. I believe in a different approach, like allow the user to work together with your team for a while. This approach allows them to understand better the platform and, also, provide you better feedback.
Here is a usual example: we schedule training for five hours with ten people from the user team and some problems happen:
- Part of them have a lot of work, so they are not fully focused on the course.
- There is a production issue so two people miss two hours.
- Even people who complete the course may not use what they have learned for weeks.
Are these trainings unnecessary? Of course not. Although it requires more effort at the beginning, it needs to be complemented by other types of training or content:
- Practical examples, reference code, exercises, and support for the whole process.
- Extended team: When someone from another team participates in one of our teams. To participate means to help in design, development, and data platform operation.
Suppose there is a team that wants to start developing in the cloud and to be autonomous, so they would like to provide their infrastructure components. They have completed terraform training but they don't have the experience. It could be interesting if they can participate partially in a team that already has experience:
- Providing mentoring.
- Generates community among the teams.
- To solve day-to-day situations.
- At the end of the process, you can apply such as pair programming for a little while.
This approach allows teams to consolidate knowledge and generates a community and be generators of knowledge themselves. Data Platform teams also benefit because they know the realities of our users and their needs.
Data Platform
At the beginning and together with our users, we have to identify the use cases and features that we want to provide in our data platform.
Use Cases
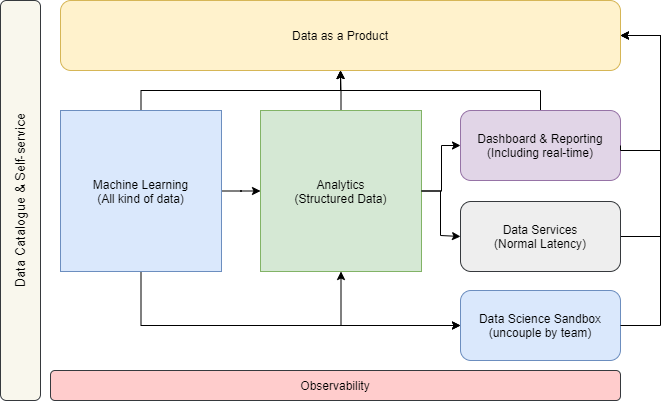
The first step was to identify the use cases from a high-level view.
Machine Learning and Deep Learning
Usually, the data science teams have a lot of technical limitations when they work in a traditional On-Premise BigData Platform:
- Performance: The storage and compute layers are bonded at the same physical node and can not be scaled independently. There are a lot of processes with high workloads. Scale-out in this kind of big data platform is complex and requires a lot of time and effort.
- Technological Backwardness: Data Sciences are continuously researching new algorithms, techniques, and products that allow them to discover a pattern or optimize processes. Eventually, this provides value to the company through data insights. To work in a flexible platform and agile in this changing environment was very important for them.
- Machine Learning Lifecycle: They need an operational platform for managing the end-to-end machine learning lifecycle.
In terms of data, they worked with a large variety of data:
- Structured data such as tables.
- Images.
- PDFs.
- And others.
Nowadays having analytical sandboxes are a must. A data sandbox is a scalable and developmental platform designed for data science and analytics. Provide an environment with tools, a computing resources required to support experimental or developmental analytic capabilities without impact to application databases or other analytics processes.
Data science teams need to analyze a large amount of data, to apply different algorithms. These processes are computationally and memory intensive. The exploratory process has no defined time windows. On traditional Bigdata platforms, although there are work prioritization queues, it is very usual that some processes affect others.
Sandboxes can be a solution to this problem because each team has its environment. These environments do not share compute or memory resources, they are isolated from each other.
Analytics
In contrast to Machine Learning, which is a highly specialized area. The are many teams using reporting and analytics capabilities:
- Business Intelligence Teams.
- Business Analysts.
- Operational teams use this informational layer to provide operational reporting without the risk of impacting their critical system.
- Any user who wants to have quick and easy access to data.
When all these users are working with structured data in a traditional data warehouse, they have the same issues:
- Understanding Data: Usually the Data Warehouses are built on "ETL spaghetti topology." There are thousands of ETLs. Each ETL can read from different sources and apply several transformations to generate the output data. This becomes a problem when several teams are generating similar data such as stock movements and applying different ETLs. It can be worse when ETLs are also nested and the lineage is not available.
- Data Latency: All data pipelines are based on batch process takes time to process and users need to wait to perform analysis. Of course, not all cases require near-real-time and in some cases, it is not possible to apply them because a large set of historical data needs to be analyzed.
- Performance: There are problems related to computing resources and storage capacity. As in a traditional big data platform, scale-out is complex and requires a lot of time and effort. Commonly, traditional data warehouses work at ninety percent of their capacity and that evolution requires years of effort.
Dashboard & Reporting
Some time ago, reporting was a functionality that was generally developed by a centralized team, usually the business intelligence team. Nowadays, all users need to create their operational, business, or informational reports.
The problems with traditional tools are mainly data, they are not ready for real-time and are oftentimes not very user-friendly.
Data Services
Not all teams consume the data from reporting tools or by directly accessing the data. In many cases, this data is provided through data services such as restful services and consumed by other applications.
In fact, and unlike other types of systems, these services generally expose the data with the same structure as the table or by applying projection, aggregation, and filter functions.
In this case, there are two common areas for improvement:
- Release speed: Each team develops its custom service, which requires a lot of effort in development and management tasks. Also, this project approach generates duplicate code.
- Owner: It was not clear who is responsible for providing these services. Depending on the project can be the data owner, the team needs to consume the data or even the platform team.
Observability
A data platform is a complex system consisting of many components and processes. It involves many teams with very different use patterns.
There are needs at different levels:
- Infrastructure.
- ETLs.
- Streaming process.
- Data Quality.
Observability could be a good approach. The goal is to publish as many events as possible from different Data Platform layers. This approach allows users to correlate events and make decisions based on different kinds of events; infrastructure, ETL processes, or logs. Each team decides which events it wants to observe.
For example, imagine we publish events with the state of all ETL processes, and at a certain point in time we have a global issue in the ETL engine:
- Teams that are monitoring their only load know that their process has failed perhaps once.
- Teams observing all events, even not only states but also other types of metrics. They may know that their processes have failed but they also know that there is a global issue and in the future, they will be able to get ahead of it. This allows them to make better decisions.
Of course, in addition to the ability to observe, it is necessary to provide standard monitoring and tools to facilitate the work of the teams.
Data Catalogue & Self-Service
A Data Catalogue manages the inventory of all organization's data. It includes metadata to help users:
- Discover data.
- Understand data.
- Provide the lineage of the data, to know which is the source.
It is a key component to avoid data silos and to democratize data. It does not matter that there is a Data Platform to provide all of the organization's data if users do not know what data is available.
Features
The following diagram shows the most important data platform features.
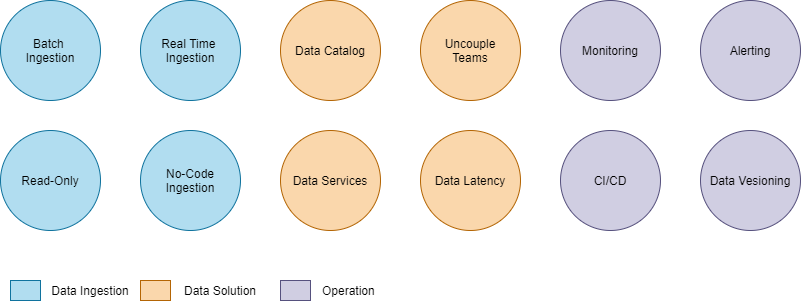
In the following article, I will share a data platform architecture and its features in detail. I hope you had a good time reading!
Opinions expressed by DZone contributors are their own.
Comments