Data Processing With Python: Choosing Between MPI and Spark
Know the differences between MPI and Spark for big data processing and find out which framework suits your needs for parallel and distributed computing.
Join the DZone community and get the full member experience.
Join For FreeMessage Passing Interface (MPI) and Apache Spark are two popular frameworks used for parallel and distributed computing, and while both offer ways to scale applications across multiple machines, they are designed to meet different needs.
In this article, I will highlight key differences between MPI and Spark with the aim of helping you choose the right tool for your big data processing.
What Is MPI?
The Message Passing Interface (MPI) is a standardized and portable message-passing system designed to function on a wide variety of parallel computers. The standard defines the syntax and semantics of library routines and allows users to write portable programs in the main scientific programming languages (Fortran, C, or C++).
In other words, MPI is an application programming interface (API) that defines a model for parallel computing across distributed processors. It gives the flexibility to scale across distributed machines for parallel execution, leveraging compute and memory resources.
What Is Spark?
Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
In other words, Apache Spark is an open-source analytics engine for processing large amounts of data. It is designed to be fast, scalable, and programmable.
Let's examine how a process is executed in Spark and MPI:
How MPI and Spark Execute a Process
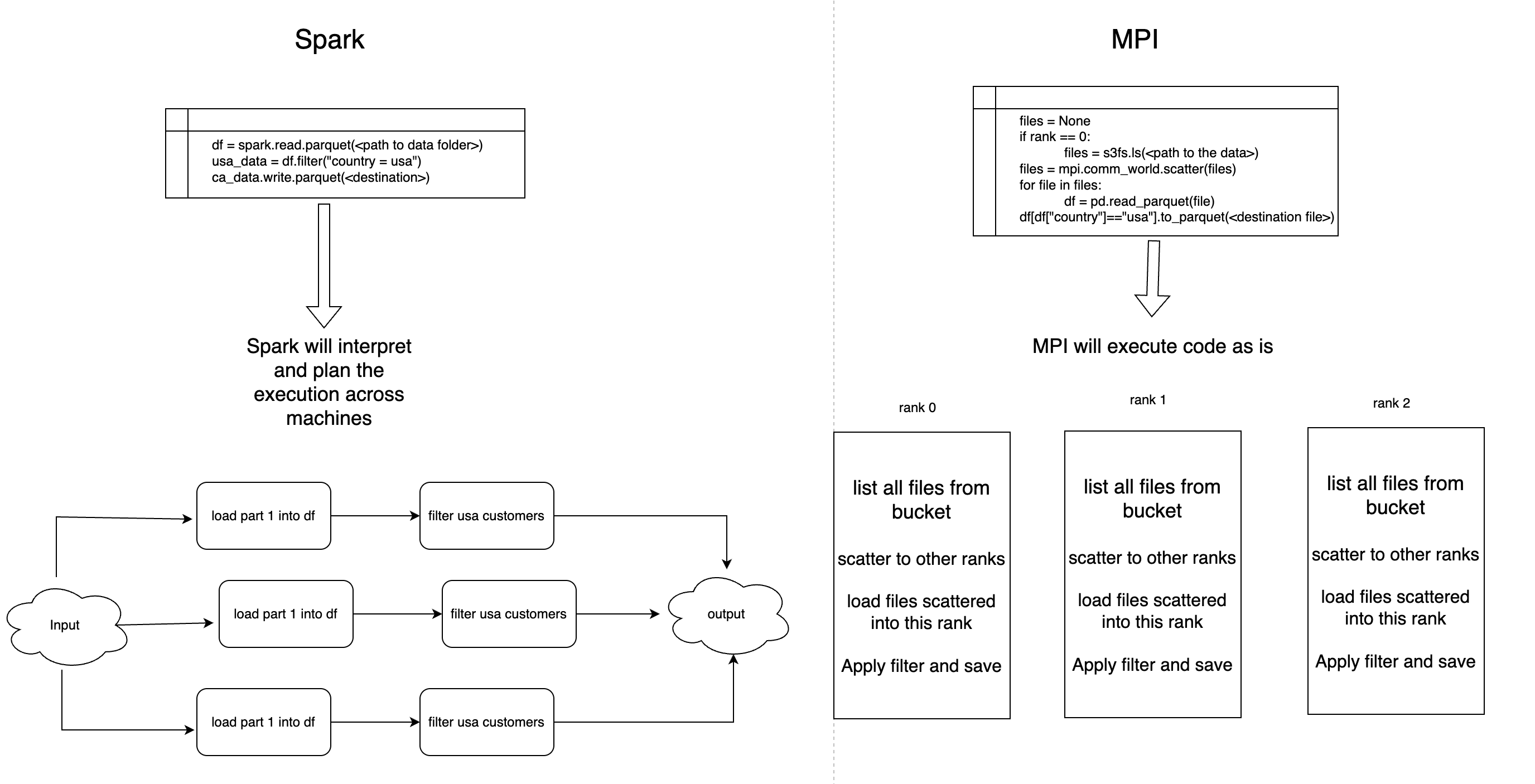
Comparing MPI and Spark
Both MPI and Spark are designed to scale your application beyond a single machine to multiple machines and run processes in parallel. The similarities between MPI and Spark probably end here. Even though they aim to enable distributed computing, the way they achieve this is vastly different, and that's what you need to understand to determine what fits your application better.
Spark is a specialized framework for running parallel and distributed workloads across machines. It has many helpful methods that one can leverage to process large amounts of data. For instance, one has to just run the below command to read through all the parquet files in one location:
spark.read.parquet("<path to the files>")
Spark does all the heavy lifting of loading these files in partitions across several nodes (machines). Its low-touch code is super convenient, but on the flip side, there might be compromises on performance and additional capabilities you may need.
MPI, on the other hand, is a framework that gives programmers the building blocks for developing parallel distributed applications that can scale across multiple machines. Unlike Spark, MPI doesn't provide convenient methods to interact with data and the programmers have the responsibility for distributing the files across machines, processing the data, and aggregating the data all by themselves. MPI doesn't provide you the luxury of prebuilt methods like Spark, but it offers flexibility to achieve maximum performance.
In short, if you want to tweak and configure based on your needs with high performance, MPI is the real deal. If you want convenience but at the cost of performance, Spark is what you need.
Key Differences Between MPI and Spark
|
Spark
|
MPI
|
| Spark is interpretive, meaning your spark code gets converted into underlying machine code. | It executes the exact code you have written and can use any libraries to perform data processing. |
| Less control over parallelism and may not utilize all the resources efficiently. | Full control to the programmer, and it's on the programmer to utilize parallel and distributed computing that best fits the need. |
| JVM startup overload time can lead to serious performance implications. | No JVM and no resource churn. |
| More convenient for programmers. | Programmers have to write their own code. |
Limitations of MPI
Even though MPI offers excellent flexibility, it has its limitations.
- One has to understand the memory requirements of the job thoroughly and provision the resources accordingly to ensure MPI runs smoothly.
- MPI doesn't have convenient built-in methods for programmers, and there is a considerable learning curve to get started with it.
Limitations of Spark
While Spark offers convenience, it too has limitations:
- Spark's extra layers and JVM startup time can slow down performance, especially for small tasks or when fast processing is needed.
- Spark hides a lot of the complexity, so users have less control over how resources are used and how tasks run in parallel.
Conclusion
Both MPI and Spark are powerful tools for distributed computing, but they serve different purposes. Spark provides a convenient, high-level approach focused on ease of use, while MPI offers more control and flexibility for performance tuning at the cost of complexity. With their strengths and limitations, you can make an informed decision as to which framework will best suit your application's needs.
Opinions expressed by DZone contributors are their own.
Comments