Databricks Delta Lake Using Java
Join the DZone community and get the full member experience.
Join For FreeDelta Lake is an open source release by Databricks that provides a transactional storage layer on top of data lakes. In real-time systems, a data lake can be an Amazon S3, Azure Data Lake Store/Azure Blob storage, Google Cloud Storage, or Hadoop Distributed file system.
Delta Lake acts as a storage layer that sits on top of Data Lake. Delta Lake brings additional features where Data Lake cannot provide.
Key features of Delta Lake as follows
ACID transactions: In real-time data engineering applications, there are many concurrent pipelines for different business data domains that operate on data lake for concurrent operations that reads and updates the data. This will lead to an issue in the data integrity due to a lack of transaction features in Data Lake. Delta Lake brings transactional features that follow ACID properties which makes data consistent.
Data Versioning: Delta Lake maintains multiple versions of data for all the transactional operations which enables developers to work on the specific version whenever required.
Schema Enforcement: This feature is also called Schema Validation. Delta Lake validates the schema before updating the data. Ensures that data types are correct and required columns are present preventing invalid data and maintaining metadata quality checks
Schema Evolution: Schema evolution is a feature that allows users to easily change a table’s current schema to accommodate data that is changing over time. Most commonly, it’s used when performing an append or overwrite operation, to automatically adapt the schema to include one or more new columns. Data engineers and scientists can use this option to add new columns to their existing machine learning production tables without breaking existing models that rely on the old columns
Efficient data format: All the data in data lake is stored in Apache Parquet format enabling delta lake to leverage compressions and encoding of native parquet format
Scalable Metadata handling: In Big Data applications, the metadata also can be big data. Delta Lake treats metadata just like data, leveraging Spark’s distributed processing power to handle all its metadata
Unified layer for batch and stream processing: Delta Lake store can act like a source and sink for both batch processing and stream processing. This will be an improvement to existing Lambda architecture which has separate pipelines for batch and stream processing.
Fully compatible with Spark framework: Delta Lake is fully compatible and easily integrated with Spark that is highly distributed and scalable big data framework.
The logical view is represented as below

Generally we use Scala for developing Spark applications. As there are a vast number of developers in Java community and Java still ruling the enterprise world, we can develop Spark applications using Java also as Spark provides complete compatibility for Java programs and utilizes JVM environment.
We will be seeing how we can leverage Delta Lake features in Java using Spark.
xxxxxxxxxx
SparkSession spark = SparkSession.builder().appName("Spark Excel file conversion")
.config("spark.master", "local").config("spark.sql.warehouse.dir", "file://./sparkapp").getOrCreate();
// create Employee POJO and add objects to the list
List<Employee> empList = new ArrayList<Employee>();
Employee emp = new Employee();
emp.setEmpId("1234");
emp.setEmpName("kiran");
emp.setDeptName("Design dept");
empList.add(emp);
emp = new Employee();
emp.setEmpId("3567");
emp.setEmpName("raju");
emp.setDeptName("IT");
empList.add(emp);
// Encoders convert JVM object of type T to and from the internal SQL
// representation
Encoder<Employee> employeeEncoder = Encoders.bean(Employee.class);
Dataset<Row> empDF = spark.createDataset(empList, employeeEncoder).toDF();
// the format should be delta to leverage delta lake features while
// saving the data to table
empDF.write().format("delta").save("/tmp/delta-table20");
// the format should be delta to leverage delta lake features while
// reading the data from the table
empDF = spark.read().format("delta").load("/tmp/delta-table20");
// show the data from the dataframe
empDF.show();
The above Java program uses the Spark framework that reads employee data and saves the data in Delta Lake.
To leverage delta lake features, the spark read format and write format has to be changed to "delta" from "parquet" as mentioned in the above program.
In this example, we will create Employee POJO and initialize the POJO with some test data. In real time, this will be populated with files from Data Lake or external data sources.
The output of the program is as below
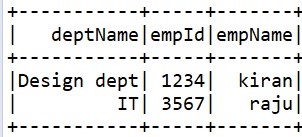
In order to run this as Maven project, add the below dependencies in the pom.xml
xxxxxxxxxx
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-core_2.11</artifactId>
<version>0.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
Append the new data to the existing delta table with "append" option.
xxxxxxxxxx
SparkSession spark = SparkSession.builder().appName("Spark Excel file conversion")
.config("spark.master", "local").config("spark.sql.warehouse.dir", "file://./sparkapp").getOrCreate();
// create Employee POJO and add objects to the list
List<Employee> empList = new ArrayList<Employee>();
Employee emp = new Employee();
emp.setEmpId("1234");
emp.setEmpName("kiran");
emp.setDeptName("IT");
empList.add(emp);
emp = new Employee();
emp.setEmpId("4862");
emp.setEmpName("david");
emp.setDeptName("Engineering");
empList.add(emp);
// Encoders convert JVM object of type T to and from the internal SQL
// representation
Encoder<Employee> employeeEncoder = Encoders.bean(Employee.class);
Dataset<Row> empDF = spark.createDataset(empList, employeeEncoder).toDF();
// the format should be delta to leverage delta lake features while
// saving the data to table
//append the data to the table
empDF.write().format("delta").mode("append").save("/tmp/delta-table20");
// the format should be delta to leverage delta lake features while
// reading the data from the table
empDF = spark.read().format("delta").load("/tmp/delta-table20");
// show the data from the dataframe
empDF.show();
The output of the above program is shown below:

The new data is appended to the table. Now there are 2 versions of the data, where the first version is the original data and data with appended is the new version of data
In order to get the data related to the first version, the below program illustrates the usage. The option "versionAsOf" will get the corresponding version of the data from Delta Lake table
xxxxxxxxxx
SparkSession spark = SparkSession.builder().appName("Spark Excel file conversion")
.config("spark.master", "local").config("spark.sql.warehouse.dir", "file://./sparkapp").getOrCreate();
// the format should be delta to leverage delta lake features while
// reading the data from the table.
// The property "versionAsOf" loads the corresponding version of data.
// Version 0 is the first version of data
Dataset<Row> empDF = spark.read().format("delta").option("versionAsOf", 0).load("/tmp/delta-table20");
// show the data from the dataframe
empDF.show();
The output corresponds to the first version of data:
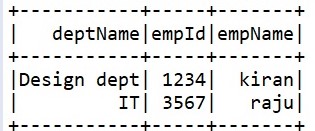
We can also overwrite with delta option using the mode "overwrite". This will overwrite the old data and create the new data in the table but still the versions are maintained and can fetch the old data with the version number
xxxxxxxxxx
empDF.write().format("delta").mode("overwrite").save("/tmp/delta-table20");
The Employee POJO used in the above examples is as given below
xxxxxxxxxx
public class Employee {
private String empName;
private String deptName;
private String empId;
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName;
}
public String getEmpId() {
return empId;
}
public void setEmpId(String empId) {
this.empId = empId;
}
}
Now, we change one of the field name in Employee POJO, say "deptName" field is changed to "deptId" field
The new POJO is as follows
xxxxxxxxxx
public class Employee {
private String empName;
private String deptId;
private String empId;
public String getDeptId() {
return deptId;
}
public void setDeptId(String deptId) {
this.deptId = deptId;
}
public String getEmpName() {
return empName;
}
public void setEmpName(String empName) {
this.empName = empName;
}
public String getEmpId() {
return empId;
}
public void setEmpId(String empId) {
this.empId = empId;
}
}
Now, we try to append data to the existing delta table with the modified schema
xxxxxxxxxx
SparkSession spark = SparkSession.builder().appName("Spark Excel file conversion")
.config("spark.master", "local").config("spark.sql.warehouse.dir", "file://./sparkapp").getOrCreate();
// create Employee POJO and add objects to the list
List<Employee> empList = new ArrayList<Employee>();
Employee emp = new Employee();
emp.setEmpId("6798");
emp.setEmpName("kumar");
emp.setDeptId("IT");
empList.add(emp);
// Encoders convert JVM object of type T to and from the internal SQL
// representation
Encoder<Employee> employeeEncoder = Encoders.bean(Employee.class);
Dataset<Row> empDF = spark.createDataset(empList, employeeEncoder).toDF();
// the format should be delta to leverage delta lake features while
// saving the data to table
//append the data to the table
empDF.write().format("delta").mode("append").save("/tmp/delta-table20");
// the format should be delta to leverage delta lake features while
// reading the data from the table
empDF = spark.read().format("delta").load("/tmp/delta-table20");
// show the data from the dataframe
empDF.show();
When we try to run the above program, the schema enforcement feature will prevent writing the data to the delta table. Delta Lake validates the schema before appending new data to the existing delta lake table. If there is any mismatch in the schema in the new data, it will throw the error about the schema mismatch
The below error occurs when we try to run the above program
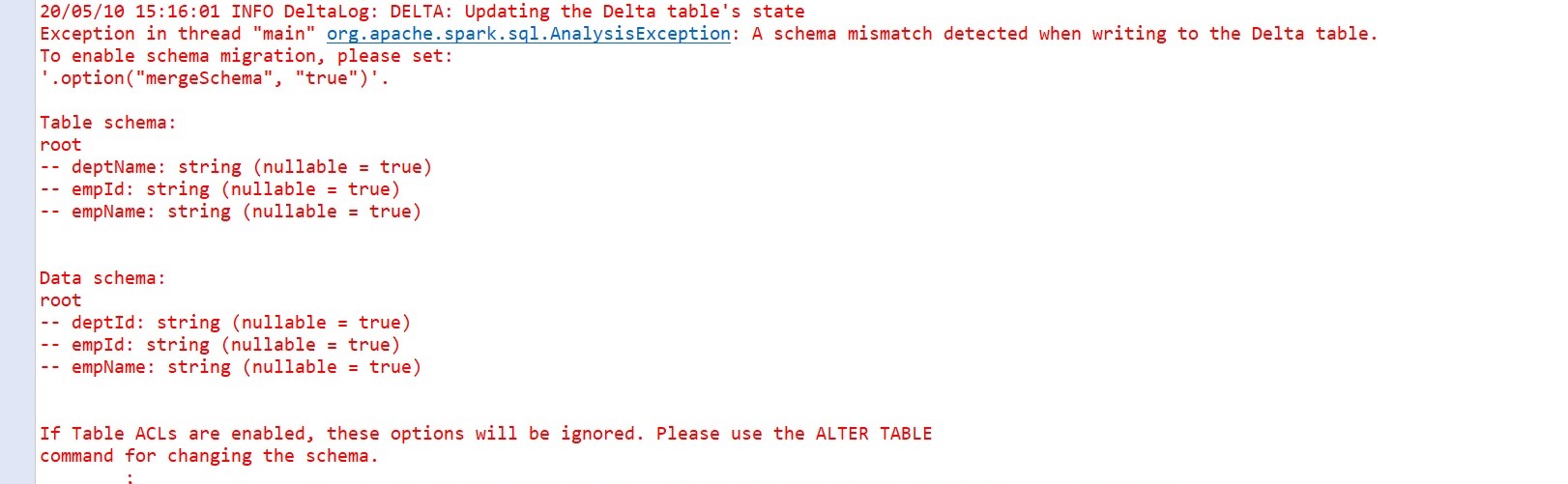
Now, we will add a new field in the existing old schema of the Employee table, which is "sectionName" and try to append data to the existing Delta Lake table.
Delta Lake will utilize a schema evolution feature that accommodates new or modified schema of the data that is being saved dynamically without any explicit DDL operations. This is achieved by using "mergeSchema" option while saving the data to Delta table as shown in the below program
SparkSession spark = SparkSession.builder().appName("Spark Excel file conversion")
.config("spark.master", "local").config("spark.sql.warehouse.dir", "file://./sparkapp").getOrCreate();
// create Employee POJO and add objects to the list
List<Employee> empList = new ArrayList<Employee>();
Employee emp = new Employee();
emp.setEmpId("6798");
emp.setEmpName("kumar");
emp.setDeptName("IT");
emp.setSectionName("Big Data");
empList.add(emp);
// Encoders convert JVM object of type T to and from the internal SQL
// representation
Encoder<Employee> employeeEncoder = Encoders.bean(Employee.class);
Dataset<Row> empDF = spark.createDataset(empList, employeeEncoder).toDF();
// the format should be delta to leverage delta lake features while
// saving the data to table
// append the data to the table
empDF.write().format("delta").mode("append").option("mergeSchema", "true").save("/tmp/delta-table20");
// the format should be delta to leverage delta lake features while
// reading the data from the table
empDF = spark.read().format("delta").load("/tmp/delta-table20");
// show the data from the dataframe
empDF.show();
The output of the above program is shown, as below:

As per the above output, "sectionName" field is merged with the existing schema of Delta lake table, and the null value is being updated for already existing records in the table in this new column.
In this way, we can leverage Delta Lake features in real-time applications that brings transactional, historical data maintenance, schema management capabilities to the existing Data Lakes.
Opinions expressed by DZone contributors are their own.
Comments