Designing High-Performance APIs
Learn API design principles for high-performance, scalable APIs that deliver exceptional user experiences and handle growing workloads.
Join the DZone community and get the full member experience.
Join For FreeWelcome back to our series on API design principles for optimal performance and scalability. In our previous blog post, we explored the importance of designing high-performance APIs and the key factors that influence API performance. Today, we continue our journey by delving into the specific API design principles that contribute to achieving optimal performance and scalability.
In this article, we will build upon the concepts discussed in the previous blog post. If you haven't had the chance to read it yet, we highly recommend checking it out to gain a comprehensive understanding of the foundational aspects of API performance optimization.
Now, let's dive into the API design principles that play a pivotal role in maximizing the performance and scalability of your APIs. By applying these principles, you can create APIs that deliver exceptional user experiences, handle increasing workloads, and drive the success of your system.
Note: This article continues our original blog post, "API design principles for optimal performance and scalability." If you're just joining us, we encourage you to read the previous post to get up to speed on the fundamentals of API performance optimization.
Importance of Designing High-Performance APIs
High-performance APIs are crucial in today's digital landscape. They are essential for enhancing the user experience, ensuring scalability, optimizing cost efficiency, maintaining competitiveness, boosting developer productivity, and driving overall business success. Users expect fast and responsive applications, and high-performance APIs deliver data promptly, providing a smooth user experience. Well-designed APIs can efficiently scale to handle increasing demands, saving costs on additional resources. In a competitive market, speed and reliability are key differentiators, and high-performance APIs give businesses a competitive edge. They also enable developers to work more efficiently, focusing on building features rather than troubleshooting performance issues. Ultimately, designing high-performance APIs should be a top priority for developers, technical managers, and business owners to exceed user expectations, foster success, and drive business growth.
Overview of the Key Factors Influencing API Performance
High-performance APIs are influenced by several key factors that directly impact their speed, scalability, and reliability. These factors include latency, scalability, caching, resource utilization, and network efficiency. Minimizing latency is essential for a fast and responsive API, achieved through techniques like caching, load balancing, and reducing network round trips. Scalability ensures that the API can handle increasing traffic and workload without compromising performance, utilizing techniques such as horizontal scaling and optimized database queries. Caching strategically improves API performance by storing frequently accessed data in memory. Efficient resource utilization, such as load balancing and connection pooling, optimizes CPU, memory, and network bandwidth. Network efficiency is improved by minimizing round trips, compressing data, and utilizing batch processing or asynchronous operations. By considering these factors during API design and development, developers can create high-performance APIs that deliver exceptional speed, scalability, and reliability.
Understanding API Design Principles
When designing high-performance APIs, it's crucial to consider certain principles that optimize their efficiency. Here are key API design considerations for performance:
- To start, prioritize lightweight design to minimize overhead and payload size, reducing network latency and enhancing response times. Efficient data structures like dictionaries and hash tables optimize data manipulation and improve API performance.
- Carefully structure API endpoints to align with expected usage patterns, minimizing unnecessary API calls and enhancing data retrieval and processing efficiency. Implement pagination for large datasets, retrieving data in smaller chunks to prevent overload and improve response times.
- Allow selective field filtering, enabling clients to specify the required fields in API responses. This eliminates unnecessary data transfer, enhancing network efficiency and reducing response times.
- Choose appropriate response formats, such as JSON, to ensure compact and efficient data transfer, enhancing network performance.
- Plan for versioning and backward compatibility in API design to enable seamless updates without disrupting existing clients. Proper versioning ensures a smooth transition to newer API versions while maintaining compatibility.
By considering these API design considerations, developers can create high-performance APIs that are efficient, responsive, and provide an excellent user experience.
Building APIs With Scalability and Efficiency in Mind
When designing APIs, scalability and efficiency are essential considerations to ensure optimal performance and accommodate future growth. By incorporating specific design principles, developers can build APIs that scale effectively and operate efficiently. Here are key considerations for building scalable and efficient APIs:
- Stateless Design: Implement a stateless architecture where each API request contains all the necessary information for processing. This design approach eliminates the need for maintaining a session state on the server, allowing for easier scalability and improved performance.
- Use Resource-Oriented Design: Embrace a resource-oriented design approach that models API endpoints as resources. This design principle provides a consistent and intuitive structure, enabling efficient data access and manipulation.
- Employ Asynchronous Operations: Use asynchronous processing for long-running or computationally intensive tasks. By offloading such operations to background processes or queues, the API can remain responsive, preventing delays and improving overall efficiency.
- Horizontal Scaling: Design the API to support horizontal scaling, where additional instances of the API can be deployed to handle increased traffic. Utilize load balancers to distribute requests evenly across these instances, ensuring efficient utilization of resources.
- Cache Strategically: Implement caching mechanisms to store frequently accessed data and reduce the need for repeated computations. By strategically caching data at various levels (application, database, or edge), the API can respond faster, minimizing response times and improving scalability.
- Efficient Database Usage: Optimize database queries by using proper indexing, efficient query design, and caching mechanisms. Avoid unnecessary or costly operations like full table scans or complex joins, which can negatively impact API performance.
- API Rate Limiting: Implement rate-limiting mechanisms to control the number of requests made to the API within a given time period. Rate limiting prevents abuse, protects server resources, and ensures fair usage, contributing to overall scalability and efficiency.
By incorporating these design principles, developers can create APIs that are scalable, efficient, and capable of handling increased demands. Building APIs with scalability and efficiency in mind sets the foundation for a robust and high-performing system.
Choosing Appropriate Architectural Patterns
Selecting the right architectural pattern is crucial when designing APIs for optimal performance. The chosen pattern should align with the specific requirements of the system and support scalability, reliability, and maintainability. Consider the following architectural patterns when designing APIs:
RESTful Architecture
Representational State Transfer (REST) is a widely adopted architectural pattern for building APIs. It emphasizes scalability, simplicity, and loose coupling between clients and servers. RESTful APIs use standard HTTP methods (GET, POST, PUT, DELETE) and employ resource-based URIs for data manipulation. This pattern enables efficient caching, scalability through statelessness, and easy integration with various client applications.
Toro Cloud's Martini takes RESTful architecture to the next level by providing an extensive set of specialized HTTP methods. In addition to the fundamental methods like GET, POST, PUT, and DELETE, Martini introduces methods such as SEARCH, PATCH, OPTIONS, and HEAD. These methods enable developers to perform specific operations efficiently, streamlining API design and enhancing overall performance. With the Martini iPaaS, developers can leverage these powerful methods while adhering to RESTful principles.
Screenshot of Martini that shows the use of Cache function.
Microservices Architecture
Microservices architecture involves breaking down the application into small, independent services that can be developed, deployed, and scaled individually. Each microservice represents a specific business capability and communicates with other microservices through lightweight protocols (e.g., HTTP, message queues). This pattern promotes scalability, agility, and fault isolation, making it suitable for complex and rapidly evolving systems.
Event-Driven Architecture
Event-driven architecture relies on the concept of events and messages to trigger and communicate changes within the system. Events can be published, subscribed to, and processed asynchronously. This pattern is beneficial for loosely coupled and scalable systems, as it enables real-time processing, event sourcing, and decoupled communication between components.
GraphQL
GraphQL is an alternative to RESTful APIs that allows clients to request and receive precisely the data they need, minimizing over-fetching or under-fetching of data. It provides a flexible query language and efficient data retrieval by combining multiple resources into a single request. GraphQL is suitable for scenarios where clients have varying data requirements and can enhance performance by reducing the number of API calls.
Serverless Architecture
Serverless architecture abstracts away server management and provides a pay-per-execution model. Functions (or serverless components) are deployed and triggered by specific events, scaling automatically based on demand. This pattern offers cost-efficiency, scalability, and reduced operational overhead for APIs with sporadic or unpredictable usage patterns.
By carefully selecting the appropriate architectural pattern, developers can design APIs that align with their specific needs, enhance performance, and provide a solid foundation for future scalability and maintainability.
Efficient Data Handling
Efficient data handling is crucial for API performance. When designing data models, it's important to consider optimizations that improve retrieval, storage, and processing efficiency. Here are key considerations for designing data models for optimal performance:
- Normalize data to minimize redundancy and ensure data integrity, or denormalize data for improved performance by reducing joins. Implement appropriate indexes on frequently queried fields to speed up data retrieval. Choose efficient data types to minimize storage requirements and processing overhead.
- Use lazy loading to fetch related data only when needed, or employ eager loading to minimize subsequent queries. Perform batch operations whenever possible to reduce database round trips and improve efficiency.
- Avoid the N+1 query problem by implementing eager loading or pagination techniques. By incorporating these considerations, developers can optimize data handling, resulting in faster retrieval, reduced processing time, and improved scalability and responsiveness of the API.
Implementing Effective Data Validation and Sanitization
Implementing robust data validation and sanitization processes is crucial for maintaining data integrity, security, and API performance. Consider the following practices to ensure effective data validation and sanitization:
Input Validation
Validate all incoming data to ensure it meets expected formats, lengths, and constraints. Implement input validation techniques such as regular expressions, whitelist filtering, and parameter validation to prevent malicious or invalid data from affecting API functionality.
Sanitization
Sanitize user input by removing or escaping potentially harmful characters or scripts that could lead to security vulnerabilities or data corruption. Apply sanitization techniques such as HTML entity encoding, input filtering, or output encoding to protect against cross-site scripting (XSS) attacks.
Data Type Validation
Validate data types to ensure proper storage and processing. Check for expected data types, handle type conversions or validations accordingly, and avoid potential errors or performance issues caused by incompatible data types.
Data Length and Size Checks
Enforce limitations on data lengths and sizes to prevent excessive resource consumption or data corruption. Validate input size, handle large data efficiently, and implement appropriate data size restrictions to maintain optimal performance.
Error Handling
Implement comprehensive error-handling mechanisms to gracefully handle validation errors and provide meaningful feedback to API consumers. Properly communicate error messages, status codes, and error responses to assist developers in troubleshooting and resolving issues quickly.
Security Considerations
Ensure that data validation and sanitization practices align with security best practices. Address common security vulnerabilities, such as SQL injection, cross-site scripting (XSS), and cross-site request forgery (CSRF), by implementing appropriate measures during data validation and sanitization.
Minimizing Unnecessary Data Transfers and Payload Size
Minimizing unnecessary data transfers and optimizing payload size is crucial for efficient API performance. Here are key practices to achieve this:
Allow clients to selectively retrieve only the necessary fields in API responses, reducing data transfer and response payload size. Implement pagination techniques to retrieve data in smaller chunks, improving response times for large datasets. Apply compression techniques like GZIP or Brotli to compress API responses, reducing payload size and enhancing data transmission speed. Enable data filtering to allow clients to retrieve only relevant information, minimizing unnecessary data transfer. Leverage cache-control headers to enable client-side caching of API responses, reducing the need for repeated data transfers. Consider using binary protocols for data transmission, as they typically result in smaller payload sizes compared to text-based formats like JSON.
By adopting these practices, developers can optimize data transfer, reduce payload size, and improve the overall performance of their APIs. Efficient data handling leads to faster response times, reduced bandwidth usage, and an enhanced user experience.
Leveraging Caching Techniques
Caching plays a significant role in optimizing API performance by reducing latency and improving response times. It involves storing frequently accessed data in memory, allowing subsequent requests for the same data to be served quickly without executing resource-intensive operations. Understanding caching and its impact on API performance is essential for developers.
When data is cached, it eliminates the need to fetch data from the original source, such as a database or external API, every time a request is made. Instead, the cached data can be directly retrieved, significantly reducing the response time. Caching can lead to a remarkable improvement in API performance, especially for data that is accessed frequently or doesn't change frequently.
By leveraging caching techniques strategically, developers can achieve the following benefits:
- Reduced Latency: Caching minimizes the time required to retrieve data, resulting in faster response times and improved user experience. Cached data can be delivered quickly, eliminating the need for time-consuming operations like database queries or network requests.
- Improved Scalability: Caching helps offload the load from the backend systems, allowing them to handle more requests efficiently. By serving cached data, the API can handle a higher volume of traffic without overburdening the underlying resources.
- Lowered Database Load: Caching reduces the number of database queries or expensive operations required to fetch data, thereby reducing the load on the database. This improves the overall efficiency of the system and prevents performance bottlenecks.
- Enhanced Availability: Caching mitigates the impact of external service failures or downtime. In cases where the original data source is unavailable, cached data can still be served, ensuring continuity of service.
To leverage caching effectively, developers should consider factors such as cache expiration times, cache invalidation mechanisms, and choosing the appropriate caching strategies for different types of data. By implementing caching techniques in their APIs, developers can significantly boost performance, improve scalability, and enhance the overall user experience.
Cache Functions
Enterprise-class integration platforms will typically include a caching function to facilitate caching of dynamic or static data. Below is a snippet showing how to use the Cache function in the integration platform Martini:
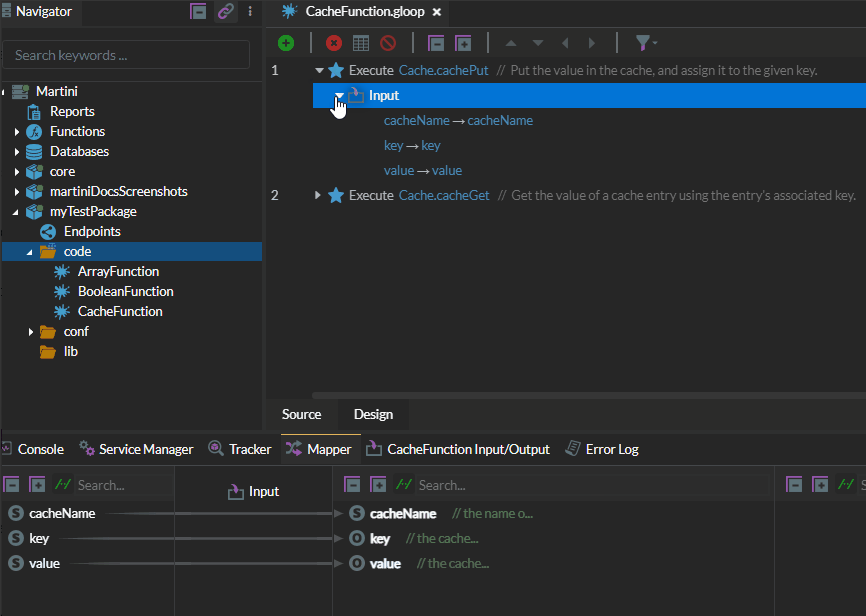
Screenshot of Martini that shows the use of the Cache function.
Types of Caching (In-Memory, Distributed, Client-Side) and Their Use Cases
Caching is a powerful technique for optimizing API performance. There are different types of caching, each with its own use cases and benefits. Understanding these caching types can help developers choose the most suitable approach for their APIs. Here are three common types of caching:
1. In-Memory Caching
In-memory caching involves storing data in the memory of the server or application. It provides fast access to cached data, as it avoids disk or network operations. In-memory caching is ideal for data that is frequently accessed and needs to be retrieved quickly. It is commonly used for caching database query results, frequently accessed API responses or any data that can be stored temporarily in memory.
2. Distributed Caching
Distributed caching involves distributing the cache across multiple servers or nodes, enabling high availability and scalability. It allows caching data across a cluster of servers, ensuring redundancy and fault tolerance. Distributed caching is beneficial for large-scale systems that require caching data across multiple instances or need to handle high traffic loads. It improves performance by reducing the load on the backend and providing consistent access to cached data.
3. Client-Side Caching
Client-side caching involves storing cached data on the client side, typically in the user's browser or local storage. This caching type enables caching resources or data that are specific to a particular user or session. Client-side caching reduces network requests, improves response times, and provides an offline browsing experience. It is commonly used for caching static assets, API responses specific to individual users, or data that doesn't change frequently.
Choosing the appropriate caching type depends on factors such as the nature of the data, usage patterns, scalability requirements, and desired performance improvements. In-memory caching is suitable for fast data retrieval; distributed caching offers scalability and fault tolerance, while client-side caching enhances user experience and reduces server load. By leveraging the right caching type for their APIs, developers can significantly improve response times, reduce server load, and enhance the overall performance of their systems.
Strategies for Cache Implementation and Cache Invalidation
Implementing caching effectively requires careful consideration of cache strategies and cache invalidation techniques. Here are key strategies to ensure efficient cache implementation and proper cache invalidation:
- Cache-Aside Strategy: The cache-aside strategy involves retrieving data from the cache when available and fetching it from the data source if not. When a cache miss occurs, the data is fetched and stored in the cache for future use. This strategy is flexible and allows developers to control what data is cached and for how long.
- Write-Through Strategy: The write-through strategy involves updating both the cache and the data source simultaneously when data changes occur. This ensures data consistency, as any modifications are propagated to both the cache and the underlying data store. Although it incurs additional write operations, this strategy guarantees that the cache always contains up-to-date data.
- Time-to-Live (TTL) Expiration: Setting a Time-to-Live (TTL) for cached data specifies the duration for which the data remains valid in the cache before it expires. After the TTL expires, the data is considered stale, and subsequent requests trigger a refresh from the data source. This approach ensures that the cached data remains fresh and reduces the risk of serving outdated information.
- Cache Invalidation: Cache invalidation is the process of removing or updating cached data when it becomes stale or obsolete. There are different cache invalidation techniques, such as:
- Manual Invalidation: Developers explicitly invalidate the cache when data changes occur. This can be done by directly removing the affected data from the cache or by using cache tags or keys to selectively invalidate related data.
- Time-Based Invalidation: Instead of relying solely on TTL expiration, time-based invalidation involves setting specific intervals to periodically invalidate and refresh the cache. This approach ensures that the cache is regularly refreshed, reducing the chances of serving outdated data.
- Event-Based Invalidation: In this approach, the cache is invalidated based on specific events or triggers. For example, when a related data entity changes, a corresponding event is emitted, and the cache is invalidated for that entity. This ensures that the cache remains synchronized with the data source.
Implementing an appropriate cache strategy and cache invalidation mechanism depends on factors such as data volatility, update frequency, and data dependencies. Choosing the right approach ensures that the cache remains accurate and up-to-date and provides the desired performance improvements.
Asynchronous Processing
Asynchronous processing is a valuable technique in API design that offers several benefits for performance, scalability, and responsiveness. Here are the key advantages of incorporating asynchronous processing in API design:
Improved Responsiveness
By leveraging asynchronous processing, APIs can handle multiple requests concurrently without blocking or waiting for each request to complete. This enables faster response times and enhances the overall responsiveness of the API. Users experience reduced latency and improved interaction with the system.
Increased Scalability
Asynchronous processing allows APIs to efficiently handle high volumes of concurrent requests. By executing tasks in the background and not tying up resources while waiting for completion, APIs can scale horizontally to accommodate a larger number of requests without compromising performance. This scalability is crucial for handling spikes in traffic or accommodating growing user bases.
Enhanced Performance
Asynchronous processing helps optimize resource utilization and improve overall system performance. By offloading time-consuming or resource-intensive tasks to background processes or worker threads, APIs can free up resources to handle additional requests. This leads to improved throughput, reduced bottlenecks, and efficient utilization of system resources.
Improved Fault Tolerance
Asynchronous processing can enhance the fault tolerance of APIs. By decoupling tasks and handling errors or failures gracefully, APIs can recover from failures without impacting the overall system. For example, if a downstream service is temporarily unavailable, asynchronous processing allows the API to continue processing other requests and handle the error condition asynchronously.
Support for Long-Running Tasks
Asynchronous processing is particularly beneficial for handling long-running tasks that may take considerable time to complete. By executing these tasks asynchronously, APIs can avoid blocking other requests and provide timely responses to clients. This ensures a smoother user experience and prevents potential timeouts or performance degradation.
Incorporating asynchronous processing in API design enables improved responsiveness, scalability, performance, fault tolerance, and support for long-running tasks. It empowers APIs to handle concurrent requests efficiently, optimize resource utilization, and provide a seamless user experience even under demanding conditions.
Techniques for Implementing Asynchronous Operations
Implementing asynchronous operations in API design requires utilizing suitable techniques to handle tasks in a non-blocking and efficient manner. Here are some commonly used techniques for implementing asynchronous operations:
- Callbacks: Callbacks involve passing a function or callback handler as a parameter to an asynchronous operation. When the operation completes, the callback function is invoked with the result. This approach allows the API to continue processing other tasks while waiting for the asynchronous operation to finish.
- Promises: Promises provide a more structured and intuitive way to handle asynchronous operations. Promises represent the eventual completion (or failure) of an asynchronous operation and allow the chaining of operations through methods like '.then()' and '.catch().' This technique simplifies error handling and improves code readability.
- Async/await: Async/await is a modern syntax introduced in JavaScript that simplifies working with promises. By using the 'async' keyword, functions can be marked as asynchronous, and the 'await' keyword allows for the blocking of execution until a promise is resolved. This approach offers a more synchronous-like programming style while still performing asynchronous operations.
- Message Queues: Message queues provide a way to decouple the processing of tasks from the API itself. Asynchronous tasks are placed in a queue, and separate worker processes or threads handle them in the background. This technique allows for efficient parallel processing and scaling of tasks, improving overall performance.
- Reactive Streams: Reactive Streams is an API specification that enables asynchronous processing with backpressure. It provides a way to handle streams of data asynchronously, allowing the API to control the rate at which data is processed to prevent overwhelming the system. This technique is particularly useful when dealing with large volumes of data or slow-consuming downstream systems.
Choosing the appropriate technique for implementing asynchronous operations depends on factors such as the programming language, framework, and specific requirements of the API. By leveraging callbacks, promises, async/await, message queues, or reactive streams, developers can efficiently handle asynchronous tasks, improve performance, and provide a more responsive API experience.
Handling Long-Running Tasks Without Blocking the API
To handle long-running tasks without blocking the API, several techniques can be employed. Offloading tasks to background processes or worker threads allows the API to quickly respond to incoming requests while the long-running tasks continue in the background. Asynchronous task execution enables the API to initiate long-running tasks independently, providing immediate responses to clients and allowing periodic checks for task status. Employing an event-driven architecture decouples the API from task execution, ensuring scalability and fault tolerance. Tracking progress and notifying clients of task completion or milestones keeps them informed without constant polling. Implementing timeouts and error handling prevents indefinite waiting and enables graceful handling of timeouts or retries. These techniques ensure that long-running tasks are handled efficiently, maintaining the responsiveness and performance of the API.
Optimizing Database Queries
Efficient database queries are crucial for optimizing API performance. They reduce response time, improve scalability, and utilize resources effectively. By optimizing queries, you can enhance the API's responsiveness, handle concurrent requests efficiently, and minimize network bandwidth usage. Moreover, efficient queries ensure a consistent user experience, reduce infrastructure costs, and contribute to the overall success of the API. Prioritizing optimized database query design significantly improves API performance, scalability, and reliability, benefiting both the users and the system as a whole.
Indexing and Query Optimization Techniques
Optimizing database queries for API performance involves implementing indexing and query optimization techniques. Indexing helps speed up data retrieval by creating appropriate indexes for frequently accessed columns. Query optimization involves optimizing query structures, using efficient join operations, and minimizing subqueries. Additionally, denormalization can be considered to reduce the number of joins required. Database tuning involves adjusting parameters and settings to optimize query execution, while load testing and profiling help identify performance bottlenecks and prioritize optimization efforts. By implementing these techniques, developers can improve query performance, leading to faster response times, better scalability, and an enhanced user experience.
Pagination and Result Set Optimization for Large Datasets
Optimizing API queries with large datasets involves employing pagination and result set optimization techniques. Pagination breaks the dataset into smaller chunks, retrieving data into manageable pages. By specifying the number of records per page and using offset or cursor-based pagination, query performance improves significantly. Result set optimization focuses on retrieving only necessary fields, reducing payload size and network transfer time. Filtering, sorting, and proper indexing enhance query execution while analyzing the query execution plan helps identify bottlenecks and optimize performance. Implementing these techniques ensures efficient management of large datasets, resulting in faster API response times and an enhanced user experience.
Minimizing Network Round Trips
Network latency plays a crucial role in API performance, as it directly affects response times and overall user experience. Understanding the impact of network latency is essential for optimizing API performance. When API requests involve multiple round trips between the client and server, latency can accumulate, resulting in slower response times.
High network latency can be caused by various factors, including geographical distance, network congestion, and inefficient routing. Each round trip introduces additional delays, which can significantly impact the API's performance, especially for real-time or interactive applications.
Reducing network round trips is key to minimizing latency and improving API performance. Techniques such as batch processing, where multiple requests are combined into a single request, can help reduce the number of round trips. Asynchronous processing, where long-running tasks are performed in the background without blocking the API, can also minimize latency by allowing the client to continue with other operations while waiting for the response.
Compressed data transfer is another effective approach to reduce the size of data transmitted over the network, minimizing the impact of latency. By compressing data before sending it and decompressing it on the receiving end, less time is spent transferring data, resulting in faster API responses.
Understanding the impact of network latency and employing strategies to minimize network round trips are crucial for optimizing API performance. By reducing the number of round trips and optimizing data transfer, developers can significantly improve response times, enhance user experience, and ensure efficient communication between clients and servers.
Techniques for Reducing Network Round Trips
Reducing network round trips is essential for optimizing API performance and minimizing latency. Here are two effective techniques:
1. Batch Processing
Batch processing involves combining multiple API requests into a single request. Instead of sending individual requests for each operation, batch processing allows you to group them together. This reduces the number of round trips required, resulting in improved performance. By batching related operations, such as creating, updating, or deleting multiple resources, you can minimize the overhead of establishing multiple connections and transmitting individual requests.
2. Compressed Data Transfer
Compressing data before transmitting it over the network is another technique to reduce network round trips. By compressing data on the server side and decompressing it on the client side, you can significantly reduce the size of the data transferred. Smaller data payloads require less time to transmit, resulting in faster API responses. Compression algorithms like GZIP or Brotli can be used to compress data efficiently, providing a good balance between compressed size and decompression speed.
By implementing batch processing and compressed data transfer, developers can effectively reduce network round trips, minimize latency, and improve API performance. These techniques optimize the utilization of network resources, enhance response times, and deliver a smoother user experience.
Main Best Practices for Optimizing API Communication
Optimizing API communication is crucial for reducing network round trips and improving performance. Here are five best practices to follow:
1. Use Efficient Data Transfer Formats: Choose lightweight and efficient formats like JSON or Protocol Buffers to minimize data size and improve response times.
2. Employ Compression: Implement compression techniques (e.g., GZIP or Brotli) to reduce the amount of data transmitted over the network, resulting in faster API responses.
3. Implement Caching: Utilize caching mechanisms to store frequently accessed data, reducing the need for repeated network requests and minimizing round trips.
4. Prioritize Asynchronous Operations: Offload long-running tasks to background operations, allowing the API to continue serving requests without blocking and impacting response times.
5. Optimize Network Requests: Combine related operations into a single request using batch processing to reduce the number of round trips required for communication.
By following these best practices, developers can optimize API communication, minimize network round trips, and enhance the overall performance of their APIs. These strategies result in faster response times, improved user experience, and more efficient network utilization.
Implementing Rate Limiting and Throttling
Rate limiting and throttling are essential techniques for controlling the rate of API requests and preventing abuse or overload of API resources. These concepts help ensure fair and efficient usage of APIs while maintaining stability and performance.
Rate limiting involves setting limits on the number of API requests that can be made within a specific time window. It helps prevent excessive usage by enforcing a maximum request rate for individual users or client applications. By setting appropriate limits, you can prevent API abuse, protect server resources, and maintain a consistent quality of service.
Throttling, on the other hand, focuses on regulating the speed or frequency of API requests. It allows you to control the rate at which requests are processed or responses are sent back to clients. Throttling is useful for managing system load and preventing overwhelming spikes in traffic that can lead to performance degradation or service disruptions.
Both rate-limiting and throttling techniques involve implementing mechanisms such as request quotas, time-based restrictions, or token-based systems to enforce limits on API usage. By strategically implementing these measures, you can ensure a fair and reliable API experience for users, mitigate security risks, and protect the stability and performance of your API infrastructure.
Strategies for Preventing Abuse and Protecting API Resources
To prevent abuse and protect API resources, consider the following strategies when implementing rate limiting and throttling:
- Set Reasonable Limits: Establish sensible limits on the number of API requests allowed within a specific time period. Determine the optimal balance between meeting user needs and protecting your API resources from abuse or overload.
- Use Quotas and Time Windows: Implement request quotas, such as allowing a certain number of requests per minute or per hour, to distribute API usage fairly. Consider using sliding time windows to prevent bursts of requests from exceeding the limits.
- Implement Token-Based Systems: Require clients to authenticate and obtain tokens or API keys. Use these tokens to track and enforce rate limits on a per-client basis, ensuring that each client adheres to the defined limits.
- Provide Granular Rate Limiting: Consider implementing rate limiting at various levels, such as per user, per-IP address, per-API key, or per endpoint. This allows for fine-grained control and ensures fairness and protection against abuse at different levels.
- Graceful Error Handling: When rate limits are exceeded, provide clear and informative error responses to clients. Include details on the rate limit status, remaining quota, and when the limit will reset. This helps clients understand and adjust their usage accordingly.
- Monitor and Analyze Usage Patterns: Continuously monitor API usage and analyze patterns to identify potential abuse or unusual behavior. Utilize analytics and monitoring tools to gain insights into traffic patterns and detect any anomalies or potential security threats.
- Consider Differential Rate Limiting: Implement differentiated rate limits for different types of API endpoints or operations. Some endpoints may be more resource-intensive and require stricter limits, while others may have more relaxed limits.
Considerations for Setting Appropriate Rate Limits and Throttling Thresholds
When setting rate limits and throttling thresholds, several factors should be considered. First, prioritize user experience by finding a balance between restrictions and convenience. Ensure that limits aren't overly restrictive or burdensome for legitimate users. Second, evaluate the capacity of your API resources, such as servers and databases, to determine appropriate limits that maintain optimal performance without exhausting resources. Third, align rate limits with business requirements, taking into account different service tiers or levels. Next, analyze the resource intensity of different API operations to set varying rate limits accordingly. Consider bursts of requests during peak periods and implement suitable limits to handle them. Also, provide clear error responses and retry mechanisms for exceeded limits. Continuously monitor usage, performance, and user feedback to adjust rate limits and throttling thresholds as needed. By considering these factors, you can establish appropriate rate limits and throttling thresholds that safeguard API resources while ensuring a seamless user experience.
Testing and Performance Tuning
Testing for performance and scalability is crucial to ensure optimal API performance. It helps identify bottlenecks, validate scalability, optimize response times, ensure reliability, benchmark performance, and enhance the user experience. By simulating real-world scenarios and load conditions and using appropriate testing tools, you can fine-tune your API, optimize performance, and deliver a reliable and satisfying user experience.
Techniques for Load Testing and Stress Testing APIs
Load testing and stress testing are essential techniques for evaluating the performance and resilience of your APIs. Here are some techniques to consider:
- Load Testing: Load testing involves simulating expected user loads to assess how your API performs under normal operating conditions. Use load-testing tools to generate concurrent requests and measure response times, throughput, and resource usage. Vary the load to determine your API's maximum capacity without performance degradation.
- Stress Testing: Stress testing pushes your API beyond its expected limits to identify failure points and determine its resilience. Increase the load gradually until you reach the breaking point, observing how the API behaves under extreme conditions. This helps uncover potential bottlenecks, resource limitations, or performance issues that may arise during peak traffic or unexpected spikes.
- Performance Monitoring: Use monitoring tools during load and stress testing to capture important performance metrics. Monitor response times, error rates, CPU and memory usage, database queries, and other relevant indicators. Analyze the data to identify any performance bottlenecks or areas for improvement.
- Test Data Management: Prepare realistic and diverse test data that represents the expected usage patterns of your API. This ensures that your load and stress tests simulate real-world scenarios accurately. Consider using anonymized production data or synthetic data generation techniques to create suitable test datasets.
- Test Environment Optimization: Set up a dedicated testing environment that closely resembles the production environment. Fine-tune your test environment to match the expected hardware, software, and network configurations. This helps ensure that the test results accurately reflect the performance of the API in the actual production environment.
- Scenario-Based Testing: Design test scenarios that cover various use cases, different endpoints, and complex workflows. Include scenarios that mimic peak loads, high data volumes, and specific user interactions. By testing different scenarios, you can uncover potential performance issues in specific areas of your API.
- Test Result Analysis: Carefully analyze the results of your load and stress tests. Identify performance bottlenecks, resource limitations, or any unexpected issues. Use this analysis to optimize your API's performance, fine-tune configurations, and make necessary code or infrastructure improvements.
By applying these load testing and stress testing techniques, you can gain valuable insights into your API's performance, identify areas for improvement, and ensure its ability to handle varying levels of workload and stress.
Performance Tuning Approaches and Optimization Iterations
Performance tuning involves iterative optimization to enhance your API's performance. Here are key approaches:
First, identify performance bottlenecks by analyzing metrics and logs. Prioritize critical areas to optimize first. Improve code and algorithms by eliminating unnecessary computations and reducing complexity. Optimize database queries using indexes, query optimization, and caching. Review infrastructure and configuration for optimal resource utilization. Perform load and performance testing to validate improvements and detect new bottlenecks.
Continuously monitor performance metrics and make iterative optimizations based on real-time data. Remember, performance tuning is an ongoing process requiring regular review and adaptation. By adopting these approaches, you can continually enhance your API's performance and deliver an efficient experience to users.
Recap of Key Principles for Designing High-Performance APIs
In conclusion, designing high-performance APIs involves considering key principles. First, focus on API design, scalability, and architectural patterns. Efficiently handle data by optimizing data models and minimizing unnecessary transfers. Leverage caching techniques and embrace asynchronous processing to improve performance. Optimize database queries and minimize network round trips. Implement rate limiting and throttling strategies to protect API resources. Rigorously test and monitor performance metrics to identify bottlenecks. By following these principles, you can design and optimize high-performance APIs that deliver exceptional user experiences and drive system success.
Importance of Ongoing Monitoring and Optimization Efforts
Ongoing monitoring and optimization efforts are crucial for maintaining high-performance APIs. By continuously monitoring performance metrics and making iterative optimizations, you can proactively identify and address potential bottlenecks, ensure scalability, and deliver optimal user experiences. Remember that API performance optimization is not a one-time process but requires consistent attention and adaptation. By staying proactive and committed to ongoing monitoring and optimization, you can ensure that your APIs continue to perform at their best and provide long-term value to your users.
Implications of High-Performance APIs on User Experience and Business Success
High-performance APIs have significant implications for user experience and business success. By designing and optimizing APIs for optimal performance, you can provide users with fast and reliable services, leading to improved user satisfaction, engagement, and retention. Additionally, high-performance APIs contribute to the overall efficiency and scalability of your system, enabling you to handle increased traffic and workload effectively. This, in turn, can lead to enhanced customer loyalty, a positive brand reputation, and increased revenue opportunities. Investing in high-performance APIs is a strategic decision that can drive the success of your business in today's competitive digital landscape.
Opinions expressed by DZone contributors are their own.
Comments