Designing Irreversible Security Release at Hyper-Scale: Lessons Learned From Things You Can’t Undo
Engineers rely on rollback to keep systems stable—but sometimes it isn’t possible. This article explores irreversible changes and why baking and testing matter.
Join the DZone community and get the full member experience.
Join For FreeWhat Makes a Change Irreversible?
Reverting a line of code is easy, and most of the time, firmware is backward-compatible. But what if a piece of hardware is specifically designed not to take older firmware, and the only option is to fix it with a new version?
You could argue: Why design the hardware in such a manner? Well, it could be for a myriad of reasons, including a hardware design bug, a security hash algorithm that was a one-way function, or an older firmware bug that's being fixed in the newer release. It's easy to update the software behavior if needed, but it's not possible to change any hardware behavior. So we go to the next best option — mimic software to accept the hardware flaw and invert the operation on the software side.
Can it be just software that's irreversible? Absolutely! There could be legacy code sitting in the Git repository for years, afraid of breaking things written by some old engineer who has left or retired. For example, there was an engineer in my org who was a Guix guru. I worked closely with him to understand it enough to create a decent readme for anyone trying to onboard. What the readme didn't include was all the troubleshooting I had to do to get a working Guix environment. Typical engineer behavior. When we add a readme, we tend to mention happy paths and rarely some edge cases. This might work great if you’re installing or setting up something in a closed environment, like a Python virtual environment. But imagine setting up something directly on the system path, and when you add in the different flavours of operating systems, there would be more than enough problems that might need random troubleshooting, going through random online threads or articles. Do we keep a note of all the troubleshooting? Maybe. But would it help the next time or the next person using a different distro? Maybe not!
The Hardware and the Role It Played
Every server in the cloud needs to constantly go through provisioning, which happens all the time, depending on where it is in its lifecycle. It could be in repair or being tested for development, or the most common use case is being recycled by the customer or even being vacated by the current customer and getting ready to be wiped clean and installed with all the latest and greatest firmware to be attached to the general capacity pool.
Provisioning is not only critical but also a major feature meticulously reviewed by the security team. Any tampering in the way needs to be monitored with logs, metrics, and alarms. But where do we actually start? How do we even start trusting the server to begin with?
The hardware of the hour and the one you’re curious about is none other than the root of trust (ROT) device. Why is it called that way? Well, for starters, as the name suggests, it is the device from which the trust happens, to put it very simply.
Every provisioning needs a trustworthy device, which is then used to wipe and flash the latest firmware on the other devices on the whole server. Depending on how other devices on the server are provisioning, we could even use other devices to perform an air-gapped, secure provisioning wipe.
For example, if the server comes with a bare-metal controller (BMC) device connected to the ROT, we could first wipe and flash the BMC using the ROT with the firmware we want. And since the BMC was wiped and blessed by the secure ROT hardware, we could now start trusting the BMC for any further provisioning that may or may not require it.
ROT, being a critical and the first point of contact that secures the provisioning process, can't be just updated and expected to always work. Proper testing and extensive validation need to happen before releasing new firmware on it. If it's any minor bug fixes, maybe the release could be a little lenient, but in the case where it falls short of going back to its previous stable behavior, and the only way is to do a new version with a roll-forward fix, that's when releases need to be extremely cautious when dealing with hyperscale servers.
Why Regular Methods Like CI/CD Fell Short
Continuous integration and deployment are great tools, but weren't an obvious choice in this case. What's missing is a granular deployment that had to be orchestrated across 50+ regions for 200k+ servers. Once the scale comes into the picture, obvious options aren't obvious anymore. The elephant in the room was — what if we need to do a rollback?
Another option discussed was to release the feature via CI/CD, but then control the granularity via some limit. Imagine a limit to be a globally accessible key value pair, mostly of datatypes — String, Boolean, or Integer. This limit is more of an infrastructure change, typically released to regions via shepherd, and is not dependent on service application releases. This comes in handy if the service running on the cloud needs to make dynamic decisions based on some business criteria. This criterion could be based on the platform, any hardware, or even customer-based. And imagine each availability domain in every region can be controlled with extreme granularity. It can get verbose, but then in the case of granular control, the limit really helps a lot.
Big question: Did it help? Well, it didn't quite meet all the requirements. With a limit, you have control, but if something fails, your rollback also involves a service application roll forward due to the nature of the problem. Also, in order to select or cherry-pick server serials from each region to each availability domain, it is extremely tedious to selectively choose, and we also need to wait till that server becomes available, i.e., if any customer is using it, then we need to wait till it's vacated to test it. If time and engineering resources were on our side, we could have taken this route. But then we didn't have either luxury!
Designing for Failure
The first strategy was to manually deploy across all availability domains, bake it for a day, and then proceed to the next. If you assume on average there are three availability domains for every region, then it's almost 150 days and another 150 days baking time, which is almost 10 months. Another option was to go to one region at a time, with again some bake time, which translated to around 100 days, which wasn't bad, but still not feasible.
After a couple of discussions, we finally sat down and agreed on this: grouped 50+ regions into 7 categories based on their fault tolerance, criticality, and customer presence. Then release to one AD on a single region per category, bake it for a day, and if it looks good, go ahead and release to other regions in that category. This gave more confidence as the category deployment progressed.
|
Dev region |
1 region (1 availability domain) |
|
Group 1 |
1 region (3 availability domain) |
|
Group 2a |
6 regions (1 or 2 availability domain each) |
|
Group 2b |
8 regions (1 or 2 availability domain each) |
|
Group 3a |
8 (2 availability domains with moderate tag) |
|
Group 3b |
6 (3 availability domains with moderate tag) |
|
Group 4a |
4 (3 availability domains with critical tag) |
|
Group 4b |
4 (3 availability domains with critical tag) |
* Data shown is only for regions which needed this feature.
Validation Strategies When Rollback Is Not an Option
The obvious question needed a resilient answer: How to ensure validation is impervious to any issue? We started isolating the change to a small subset of servers within the dev region, baked it for a week, and gathered a lot of data. To name a few: provisioning time, fault metrics, hardware issues, number of iterations before an issue burgeons, heating issues, firmware load errors, firmware load times, etc. The data on the small subset of servers slowly increased confidence, little by little. We then enabled it on all servers in the dev stack and diligently went through the data collection process for a week. We also had to bake it for two weeks in the dev region, run it through multiple iterations across multiple platforms, and make sure the firmware was good enough to go to production.
Testing in the dev stack was comparatively easier than making the production call. The senior leadership and architects had to approve before starting anything, and thankfully, the data collected in the dev stack helped a lot to vouch for it. Still, it was not a quick nod but rather a delayed one after clearly outlining the release implementation and steps to be taken in case things still went south, even after so much testing and validation. 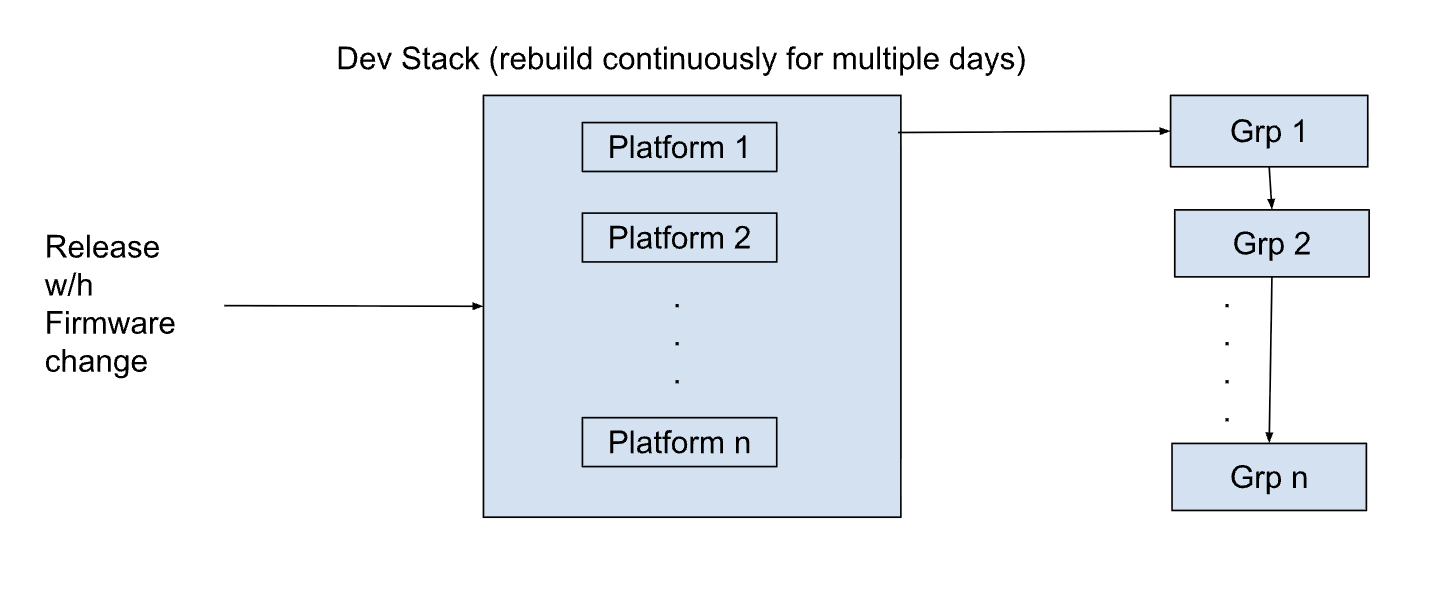
Infrastructure Risks and Alignment
Everything is great until things start to go the opposite way. The risks would have been multi-fold and quickly escalated to the top executive level. Every team involved was clearly aware of the risk: servers losing capacity across the fleet if not properly tested. This would not only result in millions in losses but also damage the company's credibility. Validation became crucial and not just once, but across multiple iterations across platforms. Multiple servers were constantly being provisioned for multiple days until we were confident in the production release. Data was diligently collected, and provisioning was carefully monitored whenever it was released to new regions. We even created a temporary team to hand-hold releases and monitor the first few servers in every region, going through it relentlessly.
Finally, once we baked enough and after 700+ iterations across multiple platforms, we were confident enough to take it to production. Luckily, the in-house pre-dev firmware qualification process was so exhaustive that we didn't fail a single iteration during our dev region testing.
Even though the data collected gave decent stability to the leadership, we still formed a small team to closely monitor the progress in case of any unknown parameters. The scale of the fallback was so big that we ended up taking all backup and precautionary measures at every step.
Any Stone Unturned: Was There a Better Option That Was Not Thought Of
People always ask: Did you end up making the right decision? Well, it's obvious there could be more than one solution to any problem, and the path we took was definitely one of many, and the data we collected clearly backed it. The dev stack testing clearly helped us catch all the weeds early on before hitting prod and keep the release within expectations.
Did we end up doing enough tests? I believe we did, and we exhausted our options in the dev stack by cherry-picking one or more platforms that needed this update and iterating on them continuously until we were confident enough to conclude the test or until we saw a failure.
Could we have spent fewer resources? For sure, but it's better to be prepared than to constantly anticipate issues and look for fallback scenarios. The cost to pay in the case was larger than the temporary engineering resource.
Final Thoughts
One could argue, why not roll forward if rollback is an issue? Well, for a cloud infrastructure, time is money. An unoccupied server every second bleeds money — not much by itself — but at scale, across 50+ regions worldwide, it matters a lot — the millions, to give you a ballpark. The first time the task reached the team’s table, things were cloudy, and the room was full of questions. Now that the dust has settled, it's a great lesson on how we overcame issues when the path that needs to be taken is yet to be paved.
The problem is not that hard if you closely go through the facts. It's the execution within a given timeline that makes someone a team, and even within the team, some engineer to take up the tasks and see through the end of the tunnel when millions are at stake.
Problems are great if executed decisively, and that's what makes every engineer an engineer. It's not just code but the decisions that revolve around great problems.
Opinions expressed by DZone contributors are their own.
Comments