Detecting Communities in Social Graph
Join the DZone community and get the full member experience.
Join For FreeIn analyzing social network, one common problem is how to detecting communities, such as groups of people who knows or interacting frequently with each other. Community is a subgraph of a graph where the connectivity are unusually dense.
In this blog, I will enumerate some common algorithms on finding communities.
First of all, community detection can be think of graph partitioning problem. In this case, a single node will belong to no more than one community. In other words, community does not overlap with each other.
High Betweenness Edge Removal
The intuition is that members within a community are densely connected and have many paths to reach each other. On the other hand, nodes from different communities requires inter-community links to reach each other, and these inter-community links tends to have high betweenness score.Therefore, by removing these high-betweenness links, the graph will be segregated into communities.
Algorithm:
- For each edge, compute the edge-betweenness score
- Remove the edge with the highest betweenness score
- Until there are enough segregation
Hierarchical Clustering
This is a very general approach of detecting communities. Some measure of distance (or similarities) is defined and computed between every pair of nodes first. Then classical hierarchical cluster technique can be applied. The distance should be chosen such that it is small between members within a community and big between members of different community.Random Walk
Random walk can be used to compute the distance between every pair of nodes node-B and node-C. Lets focus on undirected graph for now. A random walker starts at node-B, throw a dice and has beta probability that it randomly pick a neighbor to visit based on the weight of links, and with 1 - beta probability that it will teleport back to the original node-v. At an infinite number of steps, the probability distribution of landing on node-w will be high if node-B and node-C belongs to the same community. The intuition here is that the random walker tends to be trapped within the community so all nodes that has high probability distribution tends to be within the same community as node-B (where the random walker is started).Notice that the pick of beta is important. If it is too big (close to 1), then the probability after converging is independent of the starting node (ie: the probability distribution only reflect the centrality of each node but not the community of the starting node). If beta is too small (close to zero), then the walker will die down too quick before it fully explore the community's connectivity.
There is an analytical solution to this problem.
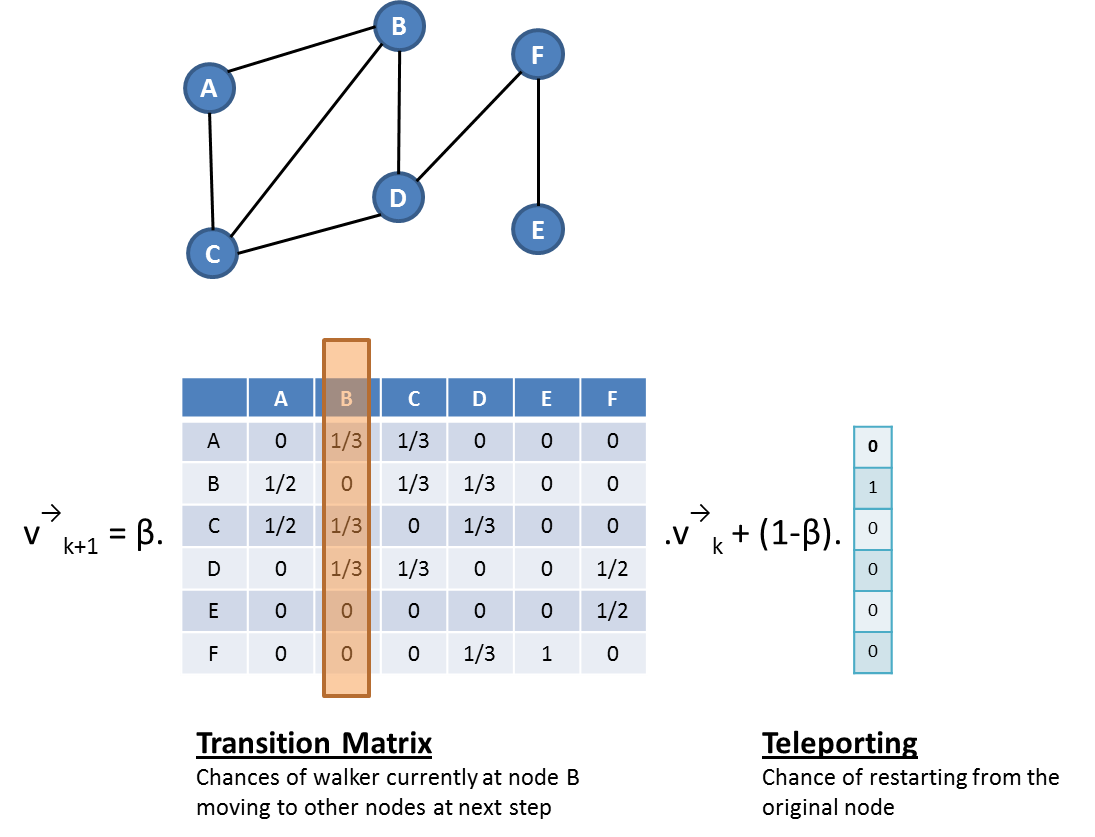
Lets M be the transition matrix before every pair of nodes. V represents the probability distribution of where the random walkers is.

The "distance" between node-B and every other nodes is the eigenvector of M. We can repeat the same to find out distance of all pairs of nodes, and then feed the result to a hierarchical clustering algorithm.
Label Propagation
The basic idea is that nodes observe its neighbors and set its own label to be the majority of its neighbors.- Nodes are initially assigned with a unique label.
- In each round, each node examine the label of all its neighbors are set its own label to be the majority of its neighbors, when there is a tie, the winner is picked randomly.
- Until there is no more change of label assignments
Modularity Optimization
Within a community, the probability of 2 nodes having a link should be higher than if the link is just formed randomly within the whole graph.probability of random link = deg(node-B) * deg(node-C) / (N * (N-1))
The actual link = Adjacency matrix[B, C]
Define com(B) to be community of node-B, com(C) to be community of node-C
So a utility function "Modularity" is created as follows ...
sum_over_v_w((actual - random) * delta(com(B), com(C)))

Now we examine communities that can be overlapping. ie: A single node can belong to more than one community.
Finding Clique
Simple community detection usually starts with cliques. Clique is a subgraph whether every node is connected to any other node. In a K-Clique, there are K nodes and K^2 links between them.However, communities has a looser definition, we don't require everyone to know every other people within the community, but we need them to know "enough" (maybe a certain percentage) of other people in the community. K-core is more relaxed definition, it requires the nodes of the K-core to have connectivity to at least K other members. There are some less popular relaxation, K-Clan requires every node to connect with every other members within K steps (path length less than K). K-plex requires the node to connect to (N - K) members in the node where N total number of members within the K-plex.
The community is defined as the found K-core, or K-clan, or K-plex.
K-Clique Percolation
Another popular way of finding community is by rolling across adjacent K-Clique. Two K-Clique is adjacent if they share K-1 nodes. K is a parameter that we need to pick based on how dense we expect the community should have.The algorithm is illustrated in following diagram.
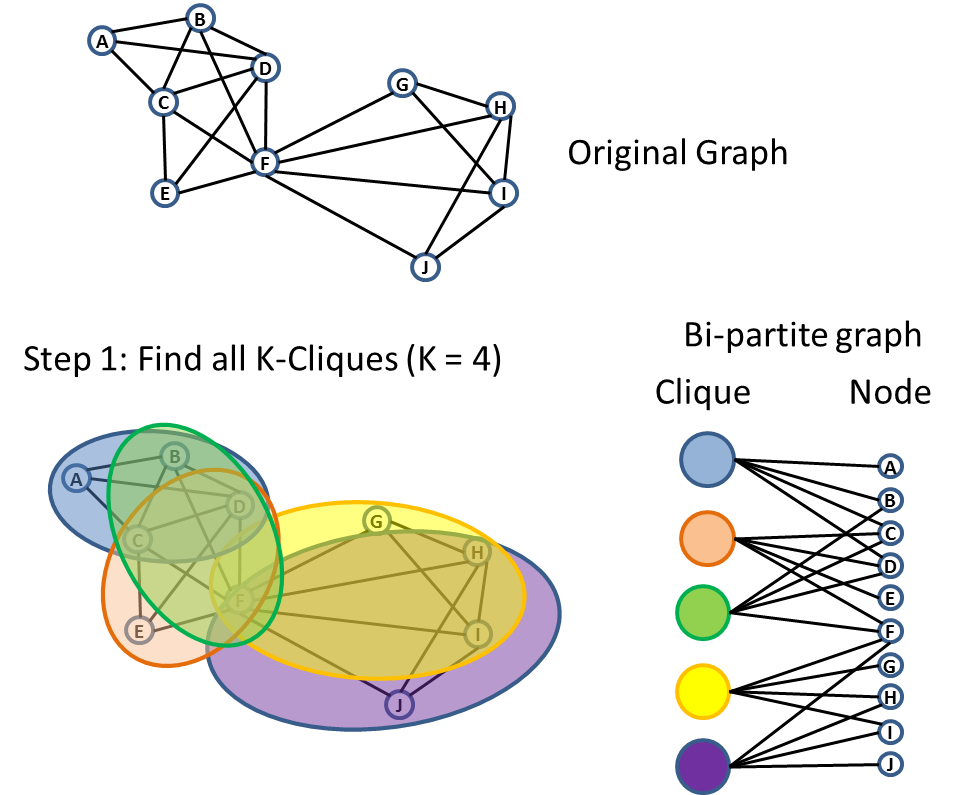
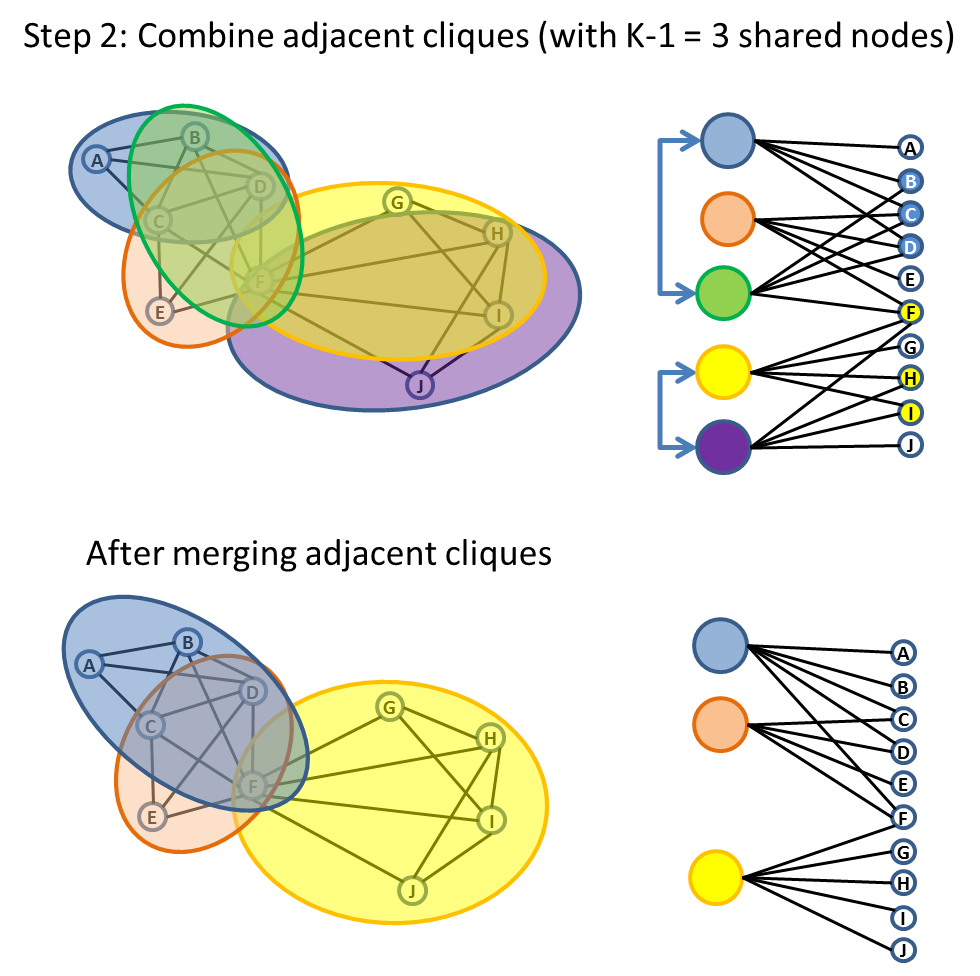
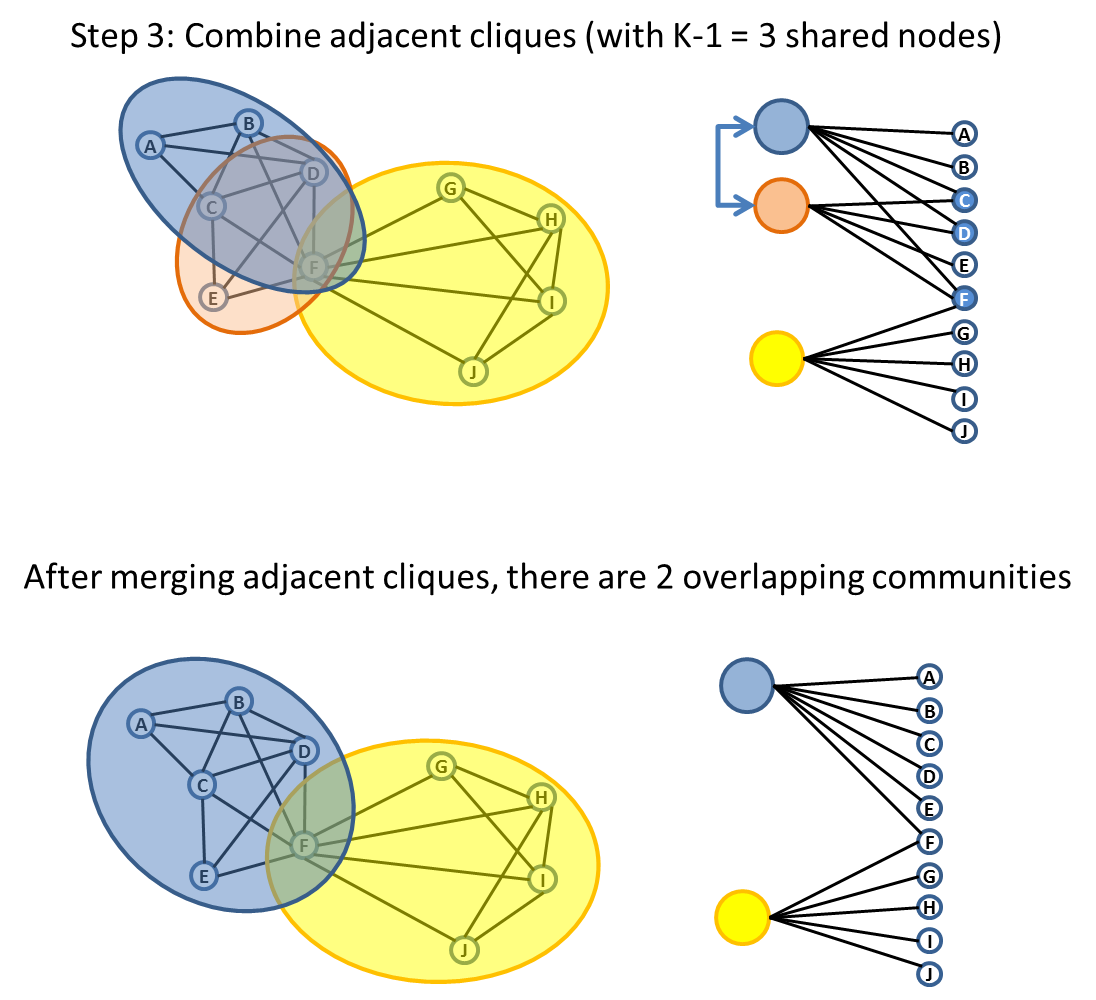
K-Clique percolation is a popular way to identify communities which can potentially be overlapping with each other.
Published at DZone with permission of Ricky Ho. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments