OpenGrok: An Indexing Service for Your Development Code
Learn how to easily set up an indexing service that will allow you to index and rapidly search through your development code.
Join the DZone community and get the full member experience.
Join For FreeHow about a personalized Google service for your development code?
Enterprise software development is complex; especially if you are joining a new team or supporting legacy applications, you will need a tool to help you search through hundreds of thousands of lines of code. I have supported legacy applications with millions of lines of codes in the past.
There are a wide variety of indexing tools available both open source and vendor specific. One of my favorites is OpenGrok.
It's a Java-based application designed to index and search through your code with a very simple interface. It supports various version control systems like Git, Mercurial, SCCS, Clearcase, Perforce, etc.
Also, you can do a complex search like finding all pom.xml files with the account_opening dependency, and it's very fast.
Feel free to learn more about OpenGrok here.
It was not always easy to configure OpenGrok from scratch, but the good news is that OpenGrok is now ported on Docker and is easy to implement. It took me less than 30 minutes to set up this demo.
To get started with OpenGrok, you will need a Unix-based host running Docker and Git. Next, you need to pull the OpenGrok Docker image and configure your SCM repositories.
Steps:
Pull the Docker image:
docker pull scue/docker-opengrokMake a directory for your source code and indexing directory locally:
mkdir -p /opengrok/src /opengrok/dataGit clone your repositories:
cd /opengrok/src; git clone https://github.com/viajshar98/java-pipelinegit clone https://github.com/viajshar98/opengrok-hadoopIt should look something like this :
root@UbantuD:/opengrok/src# pwd
/opengrok/src
root@UbantuD:/opengrok/src# ls -al
total 16
drwxr-xr-x 4 root root 4096 Oct 22 11:04 .
drwxr-xr-x 4 root root 4096 Oct 22 10:30 ..
drwxr-xr-x 6 root root 4096 Oct 22 11:04 java-pipeline
drwxr-xr-x 18 root root 4096 Oct 22 10:48 opengrok-hadoopRun a Docker container and mount these directories; this will automatically run indexing as a part of startup.
docker run -v /opengrok/src:/src -v /opengrok/data:/data -p 8888:8080 scue/docker-opengrok
Your Indexing application will now be running on http://localhost:8888/source/
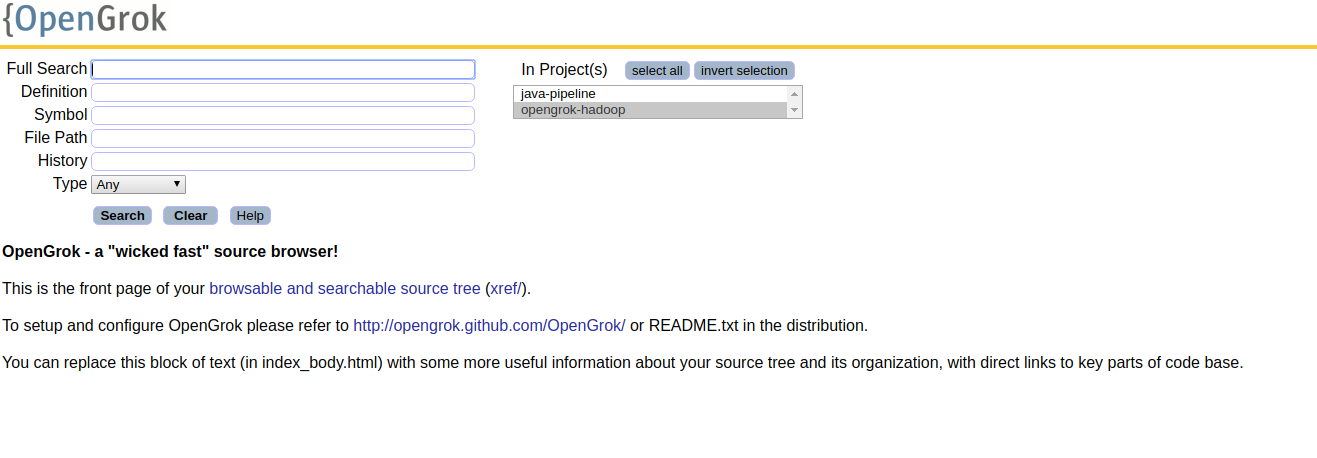
Now you can now search through your code:
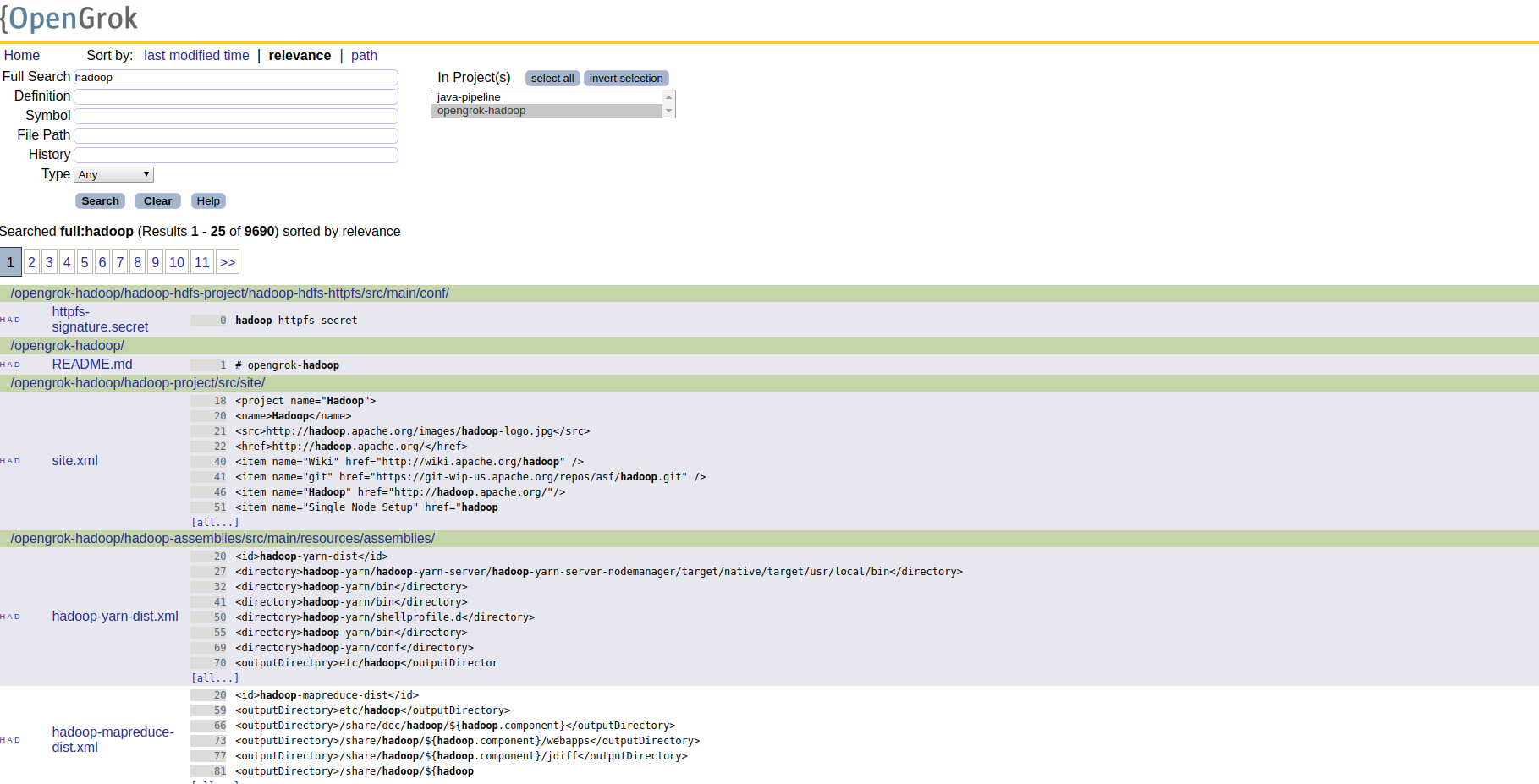
This is in no way an enterprise-ready setup, but it should give you a good idea about the potential of OpenGrok.
Tips to Make It Successful
This image does not have an SCM tool, so make sure you install Git/Clearcase or another version control tool as needed on your Docker agent.
Write some scripts to clone all needed repositories and pull changes as needed (hourly, every 4 hours, daily, etc).
If your team is using Git and not following trunk-based development, then you might need multiple repositories for each release branch.
If your teams are concerned about security and open read access to source code, then add ldap-based group access or create a local user in Tomcat and only share with your team members.
Feel free to reach out to me, comment, or ask questions if needed.
Opinions expressed by DZone contributors are their own.
Comments