DevEx Ambient Agent With Advanced Knowledge Graph
The Agentic DevEx Assistant boosts developer productivity by automating tasks, providing contextual insights, and offering personalized career growth guidance.
Join the DZone community and get the full member experience.
Join For FreeAs developers, we all face friction points throughout the day — from repetitive tasks to sifting through documentation or getting stuck on a challenging bug. The Agentic DevEx Assistant was built to help with these challenges by acting as a developer’s co-pilot. Instead of just generating code, this tool works alongside you, proactively offering contextual assistance, automating common tasks, and helping you navigate your team’s collective knowledge.
My aim is to reduce that friction, speed up feedback loops, and create a more efficient and enjoyable development environment.
Note: You can find the code in https://github.com/chrisshayan/devex-agent.
Another common challenge that I have faced in my career is the lack of a clear path for professional growth. It can be hard to know what to learn next, how to apply those learnings effectively in your code, and whether your efforts are actually improving the quality of your work. The Agentic DevEx Assistant helps bridge this gap by providing guidance, connecting learning to practical coding tasks, and offering insights into how your code quality is evolving.
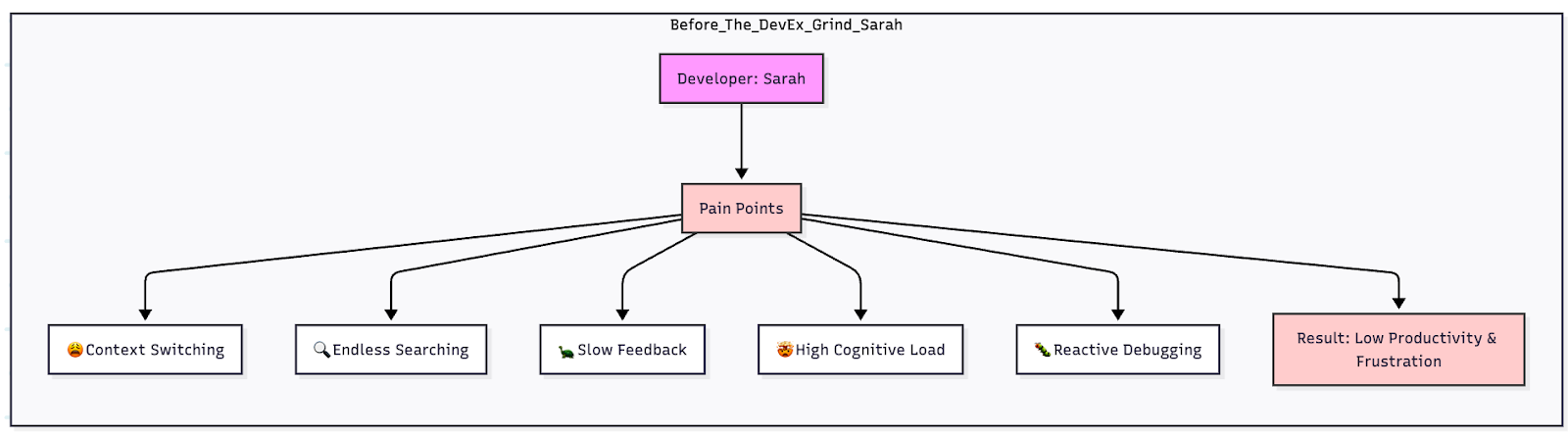
To do this, the assistant seamlessly integrates with your existing tools like GitHub, Jira, Confluence, and SonarCloud. By learning from your organization’s unique codebase and processes, it becomes a valuable force multiplier for the entire team, making it easier to focus on what matters most: building great software.
My approach is a context-aware agent that seamlessly integrates into the developer’s workflow. Crucially, it does not generate production application code itself. Instead, it empowers developers by:
- Proactive problem identification: Identifying potential issues (bugs, performance bottlenecks, security flaws, style violations) before they escalate.
- Intelligent contextual assistance: Providing highly relevant information, suggestions, and guidance precisely when and where a developer needs it.
- Workflow automation and orchestration: Automating repetitive, non-coding tasks (e.g., environment setup, dependency analysis, issue triaging, template generation).
- Knowledge navigation and synthesis: Helping developers quickly find, understand, and apply information from vast internal and external knowledge bases.
- Accelerating feedback loops: Streamlining code reviews, testing cycles, and deployment processes through automated analysis and insights.
- Career coaching advice and evaluation of the training roadmap as an individual development plan (IDP).
The architecture of the DevEx Agent is a layered system designed to process disparate data streams, synthesize them into a coherent understanding, and then take intelligent, context-aware action. At its core, it acts as a central nervous system for your development ecosystem.
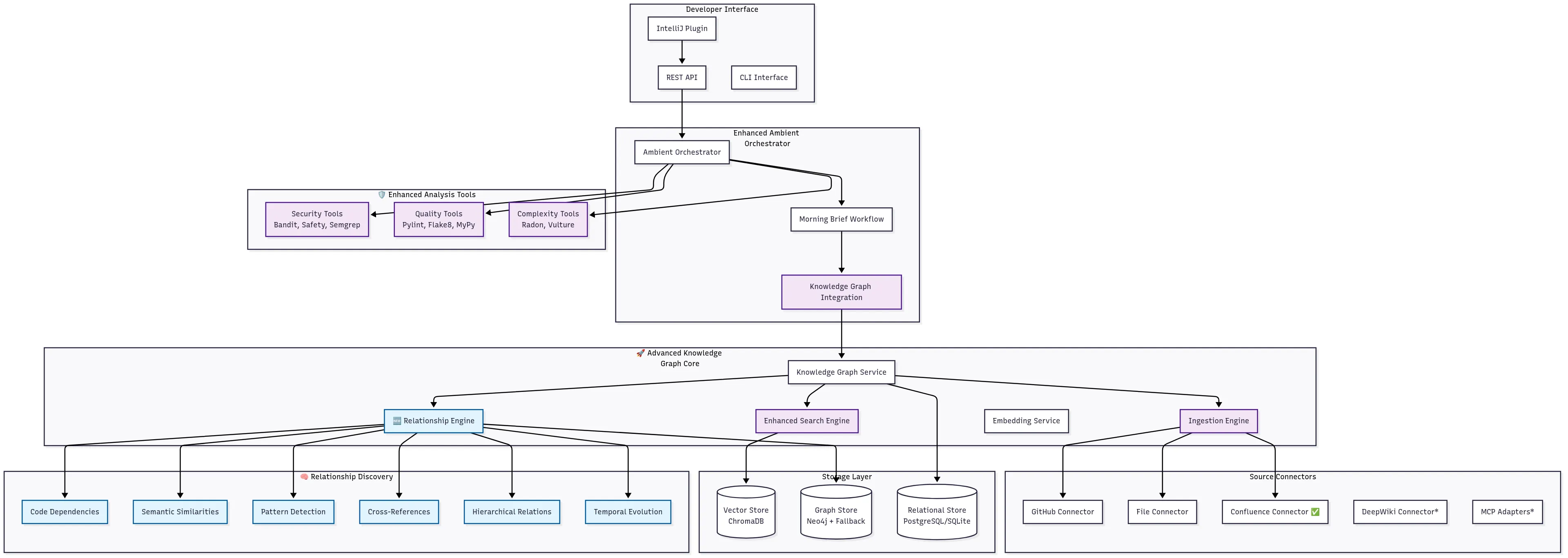
The system consists of three main logical components:
- The Integration Layer: This is the agent’s sensory system. It comprises a set of Event Listeners that connect to and consume data from various development tools. This includes webhooks from GitHub for code changes and pull requests, APIs from Jira for ticket updates, data from Confluence for documentation, and metrics from SonarCloud or other code quality tools. This stream of real-time data forms the foundation of the agent’s awareness.
- The Intelligence Core: This is the brain of the operation, where raw data is transformed into actionable knowledge. It features two key components:
- The Knowledge Graph: Raw events are processed and added to a dynamic knowledge graph. This isn’t just a database; it’s a graph-based representation that links entities like a specific code function, a pull request, a Jira ticket, a bug report, and a developer. This interconnected structure provides the rich context necessary for deep reasoning.
- ML Pattern Detection: This component applies machine learning models to the Knowledge Graph to identify patterns that go beyond simple rule-based checks. It can detect anti-patterns specific to your codebase, predict the likelihood of a bug based on commit history, or even recommend best practices by analyzing successful patterns in your organization.
- The Agentic Action Layer: This is the agent’s ability to act. The Agentic Core takes the insights from the Intelligence Core and decides on the most appropriate action. It can then use a variety of Action Hooks to perform its task. This could mean leaving an inline comment on a pull request, creating a new Jira ticket with all relevant context, or sending a personalized notification to a developer about a learning opportunity.
Key Areas
The DevEx Agent’s strength lies in its novel approach to three core areas, each designed to tackle a different facet of the developer experience.
Knowledge Synthesis Through Knowledge Graphs
Most tools treat data as isolated silos. A Jira ticket is separate from the code it references, and a Confluence page is disconnected from the pull request it’s meant to document. The DevEx Agent overcomes this with its knowledge graph. It actively builds and maintains a comprehensive, interconnected web of all development-related artifacts. When you’re looking at a code change, the agent can instantly show you the related Jira ticket, the original design document, and any past bugs associated with that file. This rich context-at-your-fingertips approach drastically reduces the time a developer spends hunting for information and piecing together the “why” behind a task.
ML Intelligence for Contextual Problem Solving
The agent’s intelligence goes beyond simple static analysis. Using ML pattern detection, it learns from the specific patterns of your team. Instead of generic warnings, it can provide highly relevant suggestions. For example, if it observes that a certain coding pattern in your team’s microservices often leads to a specific type of bug, it can proactively flag that pattern in a new pull request. The agent’s intelligence is not a one-size-fits-all solution; it’s a living model that evolves with your codebase, helping you maintain a consistent and high-quality standard that is unique to your organization.
Career Coaching for Targeted Growth
One of the most overlooked aspects of the developer experience is personalized growth. Developers often struggle to find clear, actionable guidance on what they should learn and how to apply it. The DevEx Agent addresses this with a unique career coaching component. By connecting a developer’s stated learning goals with their daily work, the agent can:
- Identify learning opportunities: It can detect instances in a pull request where a developer could apply a new principle they’re trying to learn.
- Provide in-context feedback: It offers direct, non-judgmental coaching right inside the developer’s workflow, suggesting a refactoring or a different approach that aligns with their goals.
- Measure progress: By tracking these interventions and the resulting code changes, the agent can provide measurable feedback on a developer’s progress. It closes the loop by showing if a developer’s learning efforts are translating into tangible improvements in their code quality. This turns professional development from a vague goal into a data-driven journey.
Core Architecture and Technical Stack
The DevEx Agent is built on a modular, microservices-based architecture designed for flexibility and scalability. We’ve chosen a stack that balances performance with the complexity of real-time event processing and machine learning.
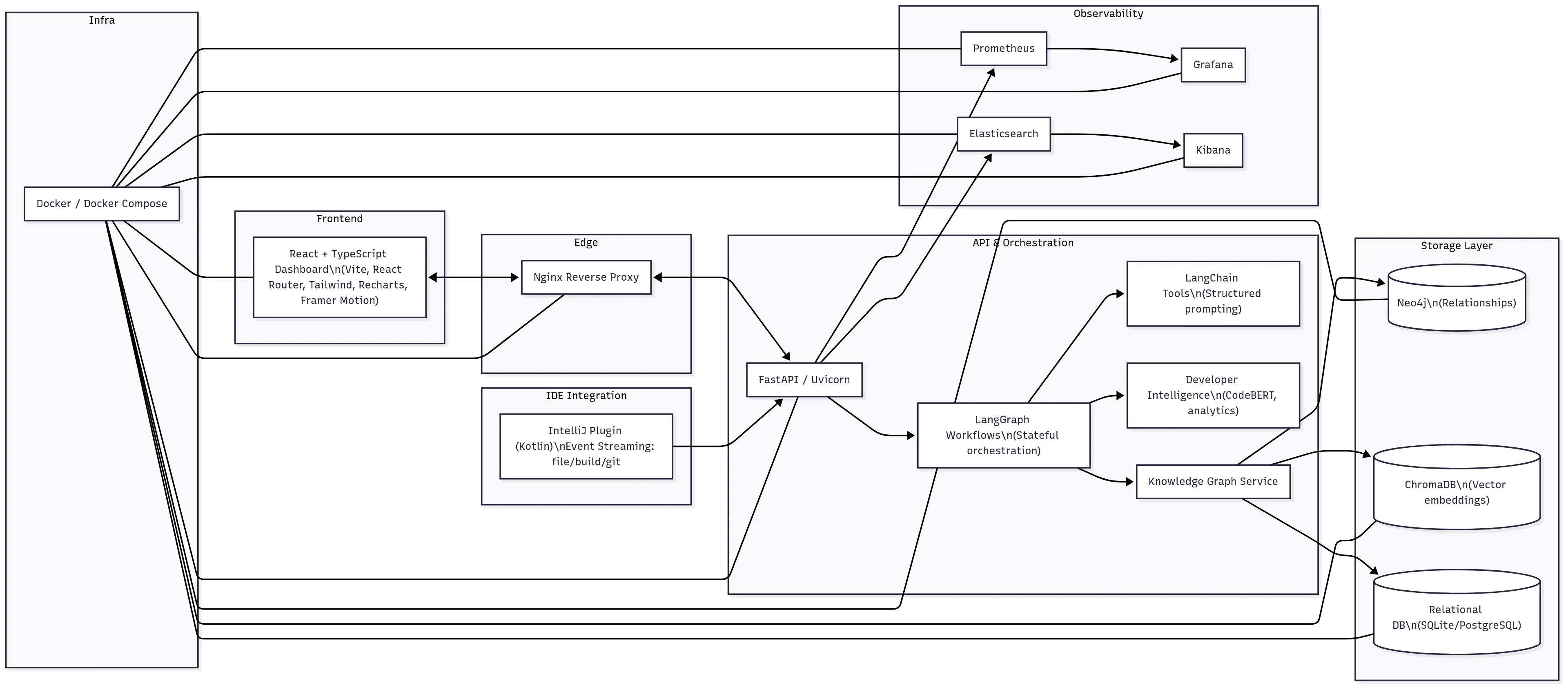
Microservices Architecture
The backend is powered by FastAPI and Uvicorn, creating a high-performance API surface. We leverage asyncio and httpx to handle IO-heavy tasks without blocking the event loop, which is critical for ingesting data from multiple sources simultaneously. For background jobs, like data ingestion and analysis, we use lightweight task invocations.
IDE integration is handled by a Kotlin-based IntelliJ plugin. This plugin streams events such as file changes, builds, and commits directly to the agent’s APIs, enabling the “ambient” context and just-in-time insights you see within the editor. The frontend is a modern React/TypeScript application using Vite for a fast development experience. We use Tailwind CSS for styling, Recharts for visualizing analytics, and Framer Motion for a smooth user experience. The dashboard includes pages for Developer Analytics, Pattern History, and Golden Sources Management.
Storage Layer
Our storage architecture is a multi-model system, each component chosen for a specific purpose:
- Knowledge graph (Neo4j): We use Neo4j to model the complex relationships between developers, code entities, skills, and patterns. This graph allows us to perform powerful traversals to find connections, like which developer
IMPLEMENTSa specificPatternor what code isSIMILAR_TOanother artifact. - Vector database (ChromaDB): ChromaDB stores high-dimensional semantic embeddings from models like CodeBERT. This enables incredibly fast cosine-similarity searches for retrieving relevant code snippets or documentation based on semantic meaning, which is a core part of our hybrid retrieval system.
- Relational storage (SQLite/PostgreSQL): Structured metadata, such as ingestion job logs, configuration for golden sources, and summarized analytics, is stored in a relational database. We default to SQLite for simplicity in single-user setups, but PostgreSQL is recommended for multi-user environments.
- Time-series analytics (InfluxDB): For high-resolution time-series data like build times, velocity, or code quality metrics, we’ve designed the analytics layer with an optional InfluxDB sink to provide fine-grained temporal analysis.
LangGraph Workflow Orchestration
To manage complex, multi-step agentic workflows, we use LangGraph. It acts as a typed state machine, ensuring long-running processes are resumable and robust. For example, our “Morning Brief” generation pipeline is a LangGraph workflow that:
- Combines recent events from the IDE, Git, and build systems.
- Performs code analysis.
- Retrieves relevant information from the Knowledge Graph.
- Uses an LLM for summarization to produce a personalized daily brief.
We also use LangChain tools and prompts to orchestrate multi-hop retrieval and to ensure that LLM outputs are structured and validated using strict Pydantic models.
The Memory Foundation
The Knowledge Graph is the agent’s memory, providing a rich, contextual understanding of the entire development ecosystem. It’s what allows the agent to reason beyond a simple keyword search.
Graph Data Model
Our graph schema is designed to capture the key entities and relationships within a software organization.
- Entity types:
Developer,CodeArtifact,Skill,Pattern, andSource(e.g., a GitHub repository or a Confluence space). - Relationship semantics: Edges describe relationships with verbs like
LEARNS,IMPLEMENTS,INFLUENCES, andSIMILAR_TO. We also use provenance edges to trace data back to its original source. - Temporal modeling: We track skill levels and pattern adoption with timestamps. This allows us to analyze trends over time and forecast a developer’s growth.
Golden Sources Architecture
Our Model Context Protocol (MCP) provides a flexible way to ingest data from various sources.
We use specialized connectors for:
- GitHub: A GitHub connector scans repositories, extracts content, and enriches it with Abstract Syntax Tree (AST) analysis for deeper pattern detection.
- File System: A file system connector ingests local projects while respecting
.gitignorefiles to avoid ingesting unnecessary artifacts. - Confluence: A connector pulls pages and attachments from Confluence, normalizing the content while preserving crucial metadata like links and labels.
Hybrid Retrieval Engine
To get the most relevant information, we’ve built a hybrid retrieval engine:
- Vector similarity search: Using CodeBERT embeddings stored in ChromaDB, we can quickly find semantically similar code or documentation.
- Graph traversal algorithms: We use algorithms like neighborhood expansion and dependency analysis on the Knowledge Graph to find related standards and examples.
- Semantic chunking: Our chunking process ensures that code and documentation are split into meaningful units (e.g., entire functions or classes), and we attach metadata to each chunk for context preservation.
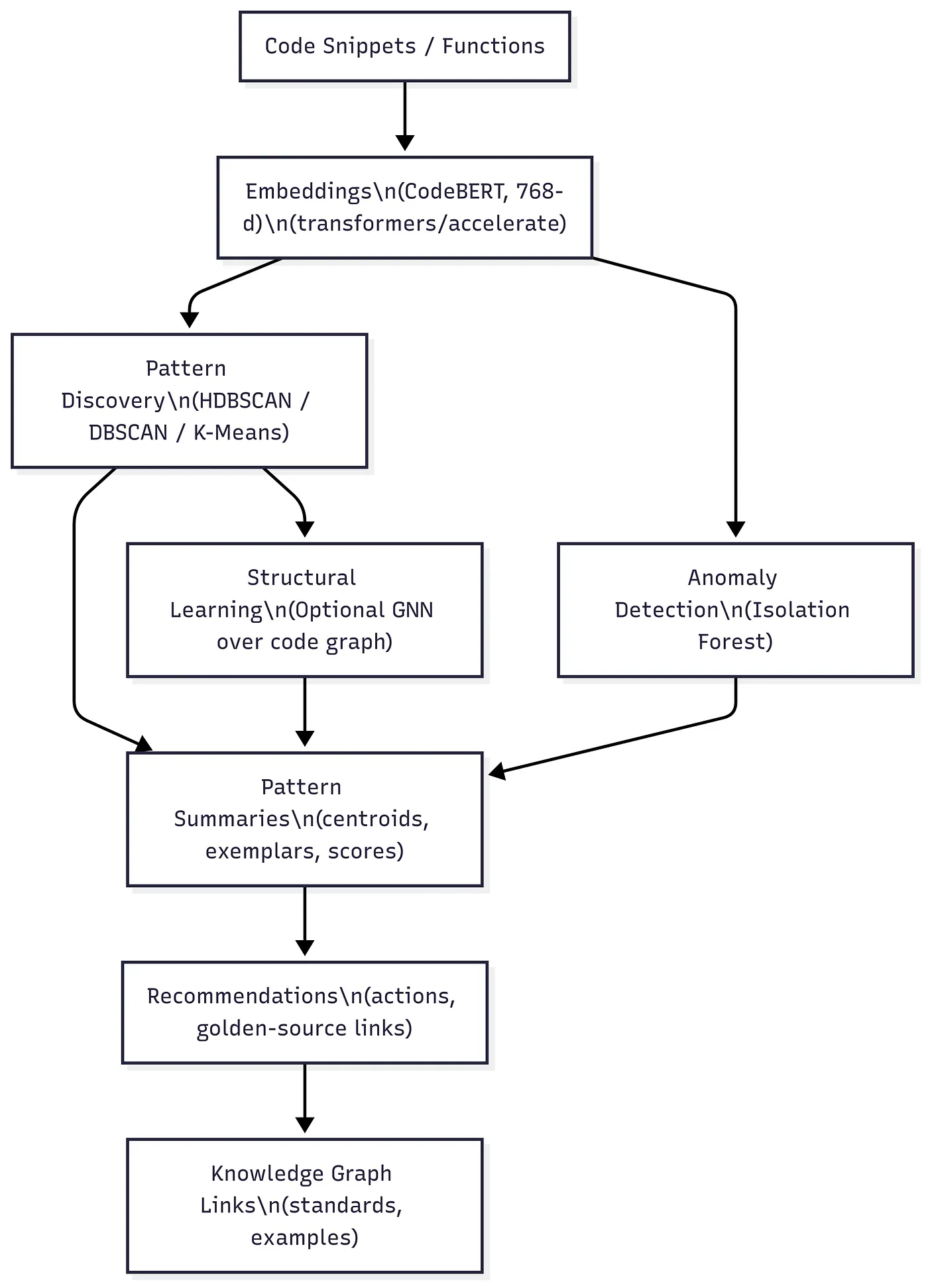
CodeBERT Integration: ML-Enhanced Pattern Detection
The DevEx Agent goes beyond simple static analysis by using machine learning to detect patterns and anomalies.
Why CodeBERT?
We chose Microsoft’s CodeBERT for its strong multilingual code and text embeddings, which are excellent at understanding function semantics and code idioms. While alternatives like GraphCodeBERT are available, CodeBERT’s broad ecosystem and strong zero-shot performance made it an ideal choice. We also support transfer learning to specialize the model on a developer’s specific codebase.
Pattern Detection Pipeline
Our pipeline for detecting patterns is as follows:
- Code embedding generation: Source lines and functions are transformed into 768-dimensional vectors using CodeBERT.
- HDBSCAN clustering: We use density-based clustering to group recurring coding idioms and patterns.
- Isolation Forest for anomaly detection: This algorithm flags outlier snippets as potential anti-patterns or security risks, with thresholds calibrated based on an organization’s specific baselines.
Developer Intelligence Engine
This is where ML meets personalized intelligence. The engine:
- Generates personalized suggestions by merging ML signals with Knowledge Graph references.
- Evaluates skill levels by combining embedding similarity to “golden sources” with code quality factors.
- Analyzes coding patterns to surface dominant patterns, anti-patterns, and style consistency, complete with file-level evidence.
- Tracks progress over time using rolling snapshots to create trajectories for skills, quality, and similarity to organizational standards.
Expert Career Coach: LLM-Powered Mentorship
The agent’s mentorship capabilities are driven by an LLM, providing personalized career coaching.
LangChain Integration Architecture
We use LangChain to integrate with OpenAI’s GPT models. Our prompts are designed to produce structured, JSON-validated outputs, and we take inspiration from frameworks like the SFIA (Skills Framework for the Information Age) to guide career progression and competency mapping.
Learning Path Engine
The agent can act as a personal learning path generator, which:
- Generates a personalized curriculum with sequenced plans and effort estimates based on a developer’s career stage and skill gaps.
- Recommends resources by blending curated defaults with LLM-expanded catalogs.
- Tracks progress using a milestone system with evidence capture and completion analytics.
Coaching Session Architecture
Coaching sessions are designed to be context-aware and proactive.
- Context-aware conversation management injects the current code context, recent events, and a developer’s skill profile into each session.
- Trigger-based coaching emits sessions based on scheduled “morning briefs,” detected skill gaps, or milestone completions.
- Analytics track suggestion acceptance and time-to-improvement, creating a feedback loop that helps retrain heuristics and adjust coaching difficulty over time.
During my career as a developer, I often wished for a better way to grow. I wanted a coach that could offer constant, personalized feedback on my code, and a way to measure whether I was truly improving or just spinning my wheels. I found myself spending too much time searching for answers and trying to apply new concepts without a fast feedback loop to tell me if I was on the right track. With the rise of new technologies, I finally saw an opportunity to build the tool I always wanted. The DevEx Agent is the result of that vision — a system designed to provide the coaching, measurement, and fast feedback that I believe can help every developer accelerate their learning and career growth.
Published at DZone with permission of Chris Shayan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments