DSPy Framework: A Comprehensive Technical Guide With Executable Examples
DSPy improves AI development by replacing prompt engineering with patterns. This guide explores how DSPy's features enable language model applications.
Join the DZone community and get the full member experience.
Join For FreeBuilding AI applications today needs the crafting of each prompt carefully balanced, but one small change can bring the whole system crashing down. Traditional prompt engineering is brittle, unpredictable, and exhausting to maintain. That’s where DSPy (Declarative Self-improving Python) comes in.
Developed by Stanford NLP researchers, DSPy takes a totally different approach. Instead of manually tweaking prompts and hoping for the best, it treats language models as programmable components like any other part of your software stack. With DSPy, you declare what you want your AI to do, not how to prompt it. The framework then automatically optimizes prompts, handles errors gracefully, and ensures reliable outputs, all while letting you focus on the bigger picture.
The framework offers three revolutionary advantages:
- Declarative programming – Define WHAT your system should accomplish, not HOW to prompt the model
- Automatic optimization – Continuously improve prompts using training data without manual intervention
- Production resilience – Built-in patterns for validation, caching, and monitoring
By shifting from fragile prompt crafting to robust engineering, DSPy enables developers to build AI systems that maintain reliability as requirements evolve and models change. The PyDataFlowNote implementation demonstrates how these principles translate to production-ready systems through practical examples.
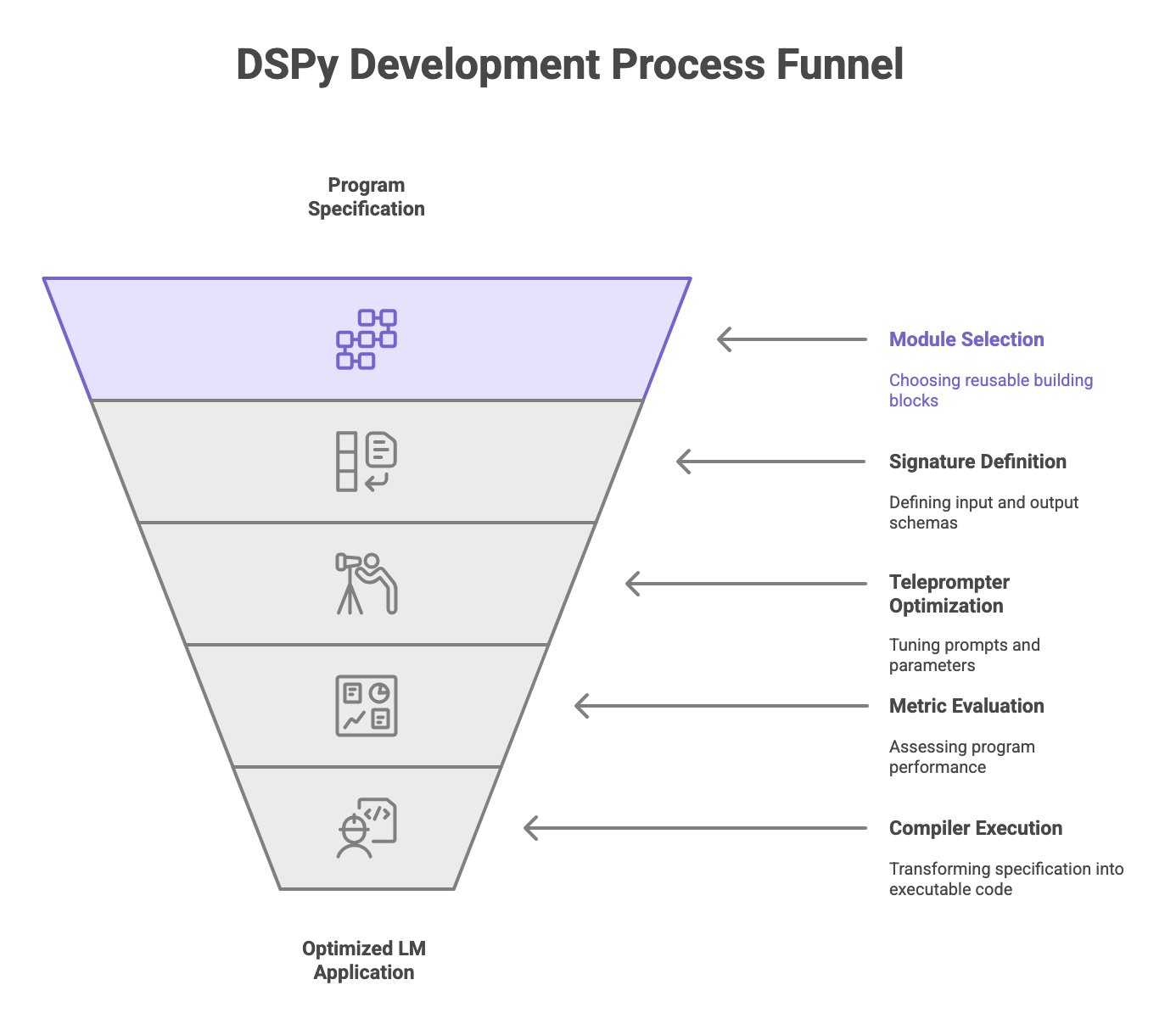
Core Concepts and Architecture
This section establishes the foundational concepts of DSPy, including signatures for task declaration and modules for pipeline composition. You'll learn how these abstractions enable reusable, testable components that automatically adapt to different language models.
Signatures: Declarative Task Specification
At the heart of DSPy lies the concept of signatures — declarative specifications of what a language model should accomplish rather than how it should accomplish it. A signature defines the input-output behavior of a task without specifying the exact prompts or reasoning steps.
# basic_examples.py
class BasicQA(dspy.Signature):
context = dspy.InputField(desc="Background information")
question = dspy.InputField()
answer = dspy.OutputField(desc="Accurate answer")This code demonstrates DSPy's signature system, which replaces traditional prompt engineering with declarative task specifications. The BasicQA signature defines a simple question-answering interface, while ChainOfThoughtQA adds explicit reasoning steps. This approach offers type safety and automatic prompt optimization, eliminating the need for manual prompt crafting and reducing brittleness in language model interactions.
Modules: Composable Building Blocks
DSPy modules are the executable components that implement signatures. They can be composed together to create complex pipelines, similar to how neural network layers are combined in PyTorch.
class SimpleRAGPipeline(dspy.Module):
def __init__(self):
self.generate_answer = dspy.ChainOfThought(BasicQA)
def forward(self, question):
return self.generate_answer(question=question)This RAGPipeline module demonstrates DSPy's composable architecture by combining retrieval and generation components into a cohesive system. The code implements a Retrieval-Augmented Generation pattern that first searches for relevant information, then generates answers using that context. This modular approach offers reusability and testability while enabling automatic optimization of the entire pipeline, which is essential for building maintainable AI systems at scale.

Optimization Engine: Self-Improving AI Systems
One of DSPy's most powerful features is its ability to automatically optimize language model pipelines using training data. Discover how DSPy automates the most painful part of LLM development - prompt engineering. This section shows how to create systems that continuously improve using your data.
optimizer = BootstrapFewShot(metric=accuracy_metric)
optimized_pipeline = optimizer.compile(pipeline, trainset=training_data)This optimization code showcases DSPy's automatic improvement capabilities, where the BootstrapFewShot optimizer analyzes training examples to enhance pipeline performance. The system automatically generates better prompts and selects optimal few-shot examples without manual intervention. This functionality offers significant time savings and performance improvements over traditional prompt engineering, making it essential for production systems that need consistent, measurable performance gains.
Integration With Pydantic for Data Validation
While DSPy provides robust handling of language model interactions, integrating it with Pydantic creates a powerful combination for building production-ready systems. Learn to integrate Pydantic validation inspired by DZone's validation guide to enforce strict output schemas and prevent malformed responses from propagating through your system.
src/pydantic_integration.py
class AnalysisModule(dspy.Module):
"""DSPy module that produces Pydantic-validated outputs"""
def __init__(self):
super().__init__()
self.analyzer = dspy.ChainOfThought(TextAnalysis)
def forward(self, text: str) -> AnalysisResult:
"""Analyze text and return validated results"""
# Get raw prediction from DSPy
prediction = self.analyzer(text=text)
# Parse and validate the output using Pydantic
try:
result_data = self._parse_analysis_output(prediction, text)
validated_result = AnalysisResult(**result_data)
return validated_result
except ValidationError as e:
# Handle validation errors with fallback
return self._handle_validation_error(text, e)
except Exception as e:
# Handle other errors
return self._handle_general_error(text, e)This integration demonstrates how Pydantic models enforce strict data validation on DSPy outputs, ensuring consistent structure and data quality. The AnalysisResult model defines exact constraints for sentiment analysis results, while the AnalysisModule combines DSPy's language processing with Pydantic's validation. This approach offers runtime safety and data integrity that's crucial for production systems, preventing malformed outputs from propagating through your application and causing downstream errors.
Advanced Patterns and Best Practices
Error Handling and Resilience
Building production systems requires robust error handling. DSPy modules should be designed to gracefully handle failures and provide meaningful fallbacks.
src/advanced_patterns.py
class ResilientQAPipeline(dspy.Module):
"""QA Pipeline with error handling and Logfire monitoring."""
def __init__(self, max_retries: int = 3):
super().__init__()
self.qa = dspy.ChainOfThought(BasicQA)
self.fallback_qa = dspy.Predict(BasicQA)
self.max_retries = max_retries
self.metrics = PipelineMetrics()
logfire_manager.log_event("ResilientQA pipeline initialized", "info", component="resilient_qa_pipeline")
@logfire_span("resilient_qa_forward", component="advanced_patterns")
def forward(self, context: str, question: str) -> dspy.Prediction:
"""Process question with retries."""
logfire_manager.log_event("Processing question with ResilientQA", "info", question=question[:100], context_length=len(context), max_retries=self.max_retries)
for attempt in range(self.max_retries):
try:
self.metrics.total_calls += 1
start_time = time.time()
qa_module = self.qa if attempt == 0 else self.fallback_qa
result = qa_module(context=context, question=question)
This resilient pipeline implements a multi-tier fallback system that automatically switches from complex reasoning (ChainOfThought) to simpler prediction methods when failures occur. The code includes retry logic, answer quality validation, and graceful degradation with informative error messages. This approach offers high availability and user experience protection by ensuring your application continues functioning even when individual components fail, which is crucial for production systems where uptime and reliability are paramount.
Caching and Performance Optimization
class CachedRAGPipeline(dspy.Module):
"""RAG Pipeline with caching and Logfire monitoring."""
def __init__(self, cache_size: int = 100):
super().__init__()
self.qa_pipeline = ResilientQAPipeline()
self._cache: Dict[str, dspy.Prediction] = {}
self.cache_size = cache_size
self.cache_hits = 0
self.cache_misses = 0
logfire_manager.log_event("CachedRAG pipeline initialized", "info", component="cached_rag_pipeline", cache_size=cache_size)
@logfire_span("cached_rag_forward", component="advanced_patterns")
def forward(self, question: str, context: Optional[str] = None) -> dspy.Prediction:
"""Process question with caching."""
context = context or "General knowledge about technology and AI."
cache_key = self._create_cache_key(question, context)
logfire_manager.log_event("Processing cached RAG query", "info", question=question[:100], has_context=context is not None)
if cache_key in self._cache:
self.cache_hits += 1
result = self._cache[cache_key]
result.from_cache = True
logfire_manager.log_event("Cache hit", "info", cache_hits=self.cache_hits, hit_rate=self.cache_hits/(self.cache_hits + self.cache_misses))
return result
self.cache_misses += 1
logfire_manager.log_event("Cache miss - processing new query", "info", cache_misses=self.cache_misses)
start_time = time.time()
result = self.qa_pipeline(context=context, question=question)
processing_time = time.time() - start_time
self._manage_cache_size()
self._cache[cache_key] = result
result.from_cache = False
logfire_manager.log_event("Query processed and cached", "info", processing_time=processing_time, cache_size=len(self._cache))
return resultThis caching implementation demonstrates how to optimize DSPy pipeline performance by storing and reusing results for similar queries. The code normalizes questions into cache keys using MD5 hashing and maintains an in-memory cache of previous results. This pattern offers significant latency reduction and cost savings by avoiding redundant language model calls, which is essential for high-traffic applications where the same or similar questions are frequently asked.
Testing and Evaluation
DSPy applications benefit from systematic testing approaches that go beyond traditional unit tests.
tests/test_pipelines.py
class TestBasicPipelines:
"""Test basic DSPy pipeline functionality"""
def setup_method(self):
"""Setup test environment"""
if LOGFIRE_AVAILABLE:
logfire_manager.log_event("Setting up test environment", "info", test_class="TestBasicPipelines")
try:
self.lm = setup_dspy_basic()
self.pipeline = BasicPipeline()
# Load test cases from sample data
from src.util import load_sample_data, get_test_cases
try:
sample_data = load_sample_data()
self.test_cases = get_test_cases(sample_data)
except Exception:
# Fallback to hardcoded test cases
self.test_cases = [
{
"question": "What is machine learning?",
"expected_topics": ["algorithms", "data", "learning", "artificial", "intelligence"]
},
{
"question": "How does photosynthesis work?",
"expected_topics": ["plants", "sunlight", "energy", "carbon", "oxygen"]
},
{
"question": "What is Python programming?",
"expected_topics": ["programming", "language", "code", "software", "development"]
}
]
except Exception as e:
pytest.skip(f"Cannot setup DSPy (likely missing API key): {e}")This testing framework combines traditional unit testing with DSPy's specialized evaluation system to ensure pipeline quality and performance. The code includes both individual test cases and systematic evaluation across datasets with custom metrics. This comprehensive testing approach offers confidence in system behavior and performance benchmarking, which is required for maintaining quality standards in production AI systems and detecting regressions during development.
Production Deployment Examples
Learn configuration management and monitoring patterns that bridge the gap between experimentation and production. This section implements the deployment pipeline from the Logfire observability guide.
src/production_examples.py
@dataclass
class ProductionConfig:
"""Configuration for production deployment"""
openai_api_key: str
model_name: str = "gpt-3.5-turbo"
max_tokens: int = 500
cache_size: int = 1000
max_retries: int = 3
request_timeout: int = 30
rate_limit_per_minute: int = 100
enable_monitoring: bool = True
log_level: str = "INFO"This monitoring wrapper demonstrates how to instrument DSPy modules for production observability by tracking performance metrics and logging system behavior. The code captures success rates, latency statistics, and error conditions while maintaining the original module interface. This monitoring approach offers critical visibility into system performance and health, enabling proactive issue detection and performance optimization that's essential for maintaining reliable AI services in production environments.
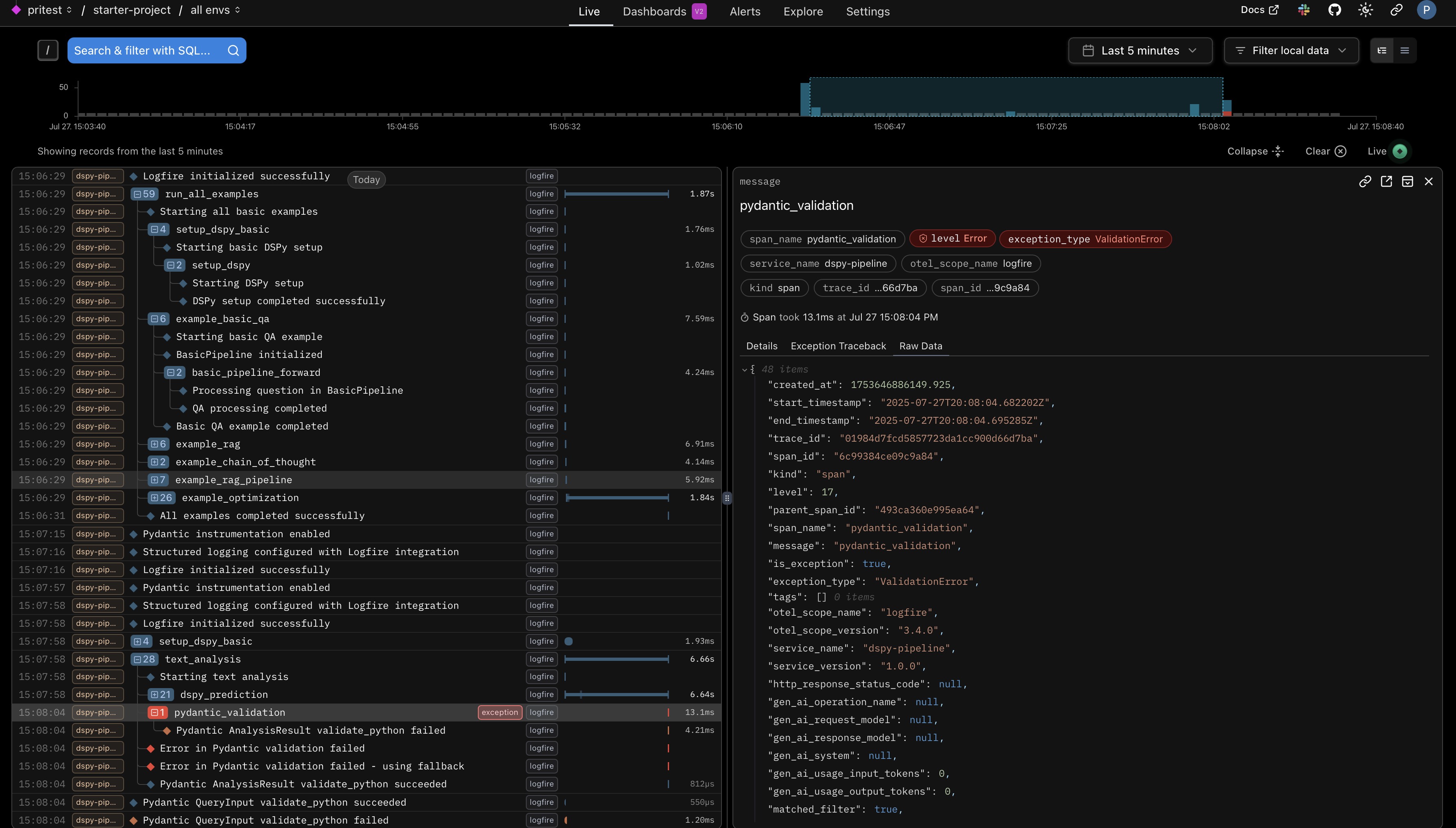
Future Directions and Ecosystem
DSPy represents a significant evolution in language model programming, and its ecosystem continues to expand. Key areas of development include:
- Integration with modern ML infrastructure: DSPy is increasingly being integrated with MLOps platforms, enabling better experiment tracking, model versioning, and deployment pipelines.
- Multi-modal extensions: Future versions are expected to support multi-modal inputs and outputs, allowing for more complex AI applications that handle text, images, and other data types seamlessly.
- Advanced optimization techniques: The framework’s optimization capabilities are continuously improving, with new algorithms that can better balance performance, cost, and reliability.
- Enterprise features: Enhanced security, compliance, and governance features are being developed to meet enterprise requirements.
Conclusion
DSPy, especially when combined with robust data validation libraries like Pydantic, provides a powerful foundation for building production-ready language model applications. Its declarative approach to prompt programming, combined with automatic optimization capabilities, represents a significant advancement over traditional prompt engineering methods.
The framework’s modular design encourages best practices in software engineering while its optimization features ensure that applications can continuously improve their performance. As the ecosystem continues to mature, DSPy is positioned to become a standard tool for serious language model application development.
The PyDataFlowNote implementation demonstrates how these principles translate to real-world systems through practical patterns you can immediately apply:
- Declarative signatures that separate intent from implementation
- Automated optimization that continuously improves performance
- Validation layers that ensure output quality
- Resilience patterns that maintain availability during failures
- Observability tooling that provides production insights
By adopting DSPy’s principles of modularity, optimization, and systematic evaluation, developers can build AI applications that are not only more reliable and maintainable but also more adaptable to changing requirements and improving language model capabilities. The complete code examples provided in this article demonstrate practical patterns that can be immediately implemented in production environments, offering a solid foundation for building robust, scalable AI systems.
Further Reading
- Explore the PyDataFlowNote examples.
- Integrate Pydantic validation (DZone guide).
- Implement monitoring with Logfire (DZone tutorial).
Opinions expressed by DZone contributors are their own.
Comments