Entangled Kubernetes Objects
A multimodal neural network that unifies per-modality losses and optimizers into a single cumulative loss, enabling flexible, scalable training across heterogeneous data.
Join the DZone community and get the full member experience.
Join For FreeAbstract
As artificial intelligence systems evolve to handle complex multimodal data, traditional neural network optimization methods face limitations in simultaneously managing heterogeneous input-output relationships. This paper proposes a novel optimization framework for neural networks that computes cumulative loss across multiple distinct input-output pairs. Each pair may involve unique data modalities and may use different optimization algorithms — such as Adam, SGD, or NAG — enabling more flexible and context-sensitive training.
Unlike conventional loss functions that aggregate a uniform loss across the network, our method permits tailored optimization strategies for each pair, which are then integrated into a cumulative loss function. This cumulative loss influences updates to all neurons in the network, including those not directly linked to a given input-output pair, due to full propagation through intermediate neurons.
The approach supports both single-dimensional and multidimensional inputs, allows overlapping or distinct neuron mappings for each data stream, and generalizes well to diverse input types. This flexible optimization paradigm enhances the capability of neural networks to process and learn from complex multimodal data environments.
Introduction
In recent years, artificial intelligence (AI) systems have made significant progress in processing and interpreting complex data. A growing area of focus is multimodal learning, in which systems integrate information from diverse data modalities such as images, audio, text, and sensory signals to perform inference and decision-making tasks. Traditional neural network architectures, while powerful, often struggle to generalize across multiple data types when trained using a uniform loss function and fixed optimization strategy.
This article presents a novel approach to neural network optimization, introducing a cumulative loss framework designed to handle multiple heterogeneous input-output (I/O) pairs. Each I/O pair may represent a unique modality or data stream and is processed using a potentially distinct optimization algorithm, such as Adam, SGD, or NAG.
Unlike standard training methods that treat all inputs uniformly, our model supports per-pair optimization and aggregates the individual losses into a cumulative loss function. This cumulative loss is then used to update the entire network, ensuring that even neurons not directly associated with specific I/O pairs contribute to the overall learning process through internal propagation.
The architecture supports both single- and multidimensional inputs and allows flexible routing — enabling input data to be processed through distinct or overlapping sets of neurons, with outputs collected from single or multiple neurons. This design facilitates the development of more adaptive and scalable neural networks capable of addressing real-world multimodal learning challenges.
Brief Description of the Invention
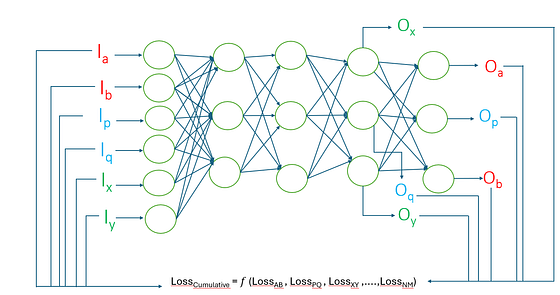
The present invention introduces a novel method for optimizing neural networks using a cumulative loss function derived from multiple input-output (I/O) pairs, each potentially associated with different data modalities and distinct loss calculations.
Unlike conventional training approaches that rely on a unified global loss function, this invention enables the computation of individual loss values for each I/O pair, which may represent different types of data streams — such as speech, vision, or olfactory signals.
Each I/O pair may enter and exit the neural network at different neurons or sets of neurons. These neurons may be distinct for each modality or partially overlap, depending on the architectural design. The network processes each input stream through its respective path, computes a modality-specific loss using a selected optimization algorithm (e.g., Adam, SGD, NAG), and aggregates these losses into a single cumulative loss value.
This cumulative loss is then used within a global optimization function to update the weights of all neurons in the network. Importantly, even neurons not directly associated with a given I/O pair contribute to learning through internal propagation, ensuring that the entire network participates in the optimization process.
Key features of the invention include:
- Support for both single- and multidimensional inputs
- Flexible assignment of input streams to specific or overlapping neuron sets
- Use of different optimization algorithms for different I/O pairs
- A generalized cumulative loss function to guide overall network optimization
- Implicit involvement of all neurons during training, enhancing convergence and performance
This invention provides greater flexibility, scalability, and adaptability in neural network training, particularly for multimodal learning applications in which simultaneous processing of heterogeneous data sources is critical.
Reduction to Practice
To demonstrate the viability of the proposed invention, we present a detailed implementation scenario in which a neural network is trained using multiple heterogeneous input-output pairs corresponding to different data modalities. This section outlines the practical setup, operation, and components involved in applying the invention.
System Scenario
Consider a neural network designed to determine the likeability of an object using multimodal data from three sources:
- Speech input: Verbal reviews or comments
- Vision input: Images or videos of the object
- Smell input: Chemical sensor data
Each data stream is represented as a distinct input-output (I/O) pair, with a defined objective (e.g., classification or regression) and an individual loss function. The system computes a cumulative loss that incorporates all modalities for joint learning.
Key Components of the Invention
1. Input Modalities (I/O Pairs)
Each modality has its own input and output channel:
A. Speech I/O (Pair 1)
- Input: Audio features (e.g., MFCCs, spectrograms)
- Output: Predicted sentiment or likeability score
- Loss Function: Cross-entropy or MSE
- Optimizer: Adam
B. Vision I/O (Pair 2)
- Input: Image features (e.g., CNN embeddings)
- Output: Visual assessment score
- Loss Function: Categorical cross-entropy or hinge loss
- Optimizer: SGD
C. Smell I/O (Pair 3)
- Input: Sensor array outputs (numerical vectors)
- Output: Smell-based rating
- Loss Function: Mean Squared Error
- Optimizer: NAG (Nesterov Accelerated Gradient)
2. Neuron Mapping and Path Propagation
Inputs are routed through dedicated neuron paths while the entire network remains interconnected:
- Neurons 1–5: Dedicated to speech input
- Neurons 6–10: Dedicated to vision input
- Neurons 11–15: Dedicated to smell input
- Neurons 16–20: Shared neurons used during cumulative gradient propagation
Even if a neuron is not explicitly involved in a specific I/O pair, it contributes to training via gradient flow during backpropagation.
Execution Workflow
- Input Feeding: Each modality provides input data to the network.
- Forward Pass: Inputs are routed through modality-specific neurons to generate outputs.
- Loss Calculation: Individual loss functions are applied to each I/O pair.
- Cumulative Loss: Losses are aggregated into a global cumulative loss.
- Optimization: Weights are updated based on cumulative gradient descent.
- Iteration: The process repeats for each training epoch until convergence.
Advantages of the Invention
The proposed neural network optimization method — based on cumulative loss computed across multiple distinct input-output (I/O) pairs — offers several advantages over conventional training techniques.
These benefits are particularly significant in multi-modal learning contexts and real-world AI systems that process diverse data types simultaneously.
Multimodality Support — Enables concurrent training with heterogeneous data types (e.g., speech, vision, smell) within a single neural network. Different modalities can be optimized independently using specialized loss functions.
Custom Optimization per I/O Pair — Supports distinct optimization algorithms (e.g., Adam, SGD, NAG) for different I/O pairs. This allows learning behavior to be tailored for each data stream, improving accuracy and convergence.
Cumulative Learning through Aggregated Loss — Combines multiple individual losses into a unified cumulative loss function, enabling coordinated optimization without enforcing uniform loss definitions.
Indirect Utilization of All Neurons — Neurons not directly involved in a specific I/O pair still contribute to learning through gradient propagation, promoting holistic optimization and improved robustness.
Flexible Neural Architecture — Supports overlapping or distinct neuron pathways for different modalities. The approach is adaptable to feedforward, recurrent, convolutional, and hybrid architectures.
Scalability and Extensibility — Easily extendable to additional modalities (e.g., taste, touch, textual input) and scalable with increasing data complexity.
Improved Generalization and Efficiency — Learning across multiple modality-specific loss landscapes enhances generalization to unseen or noisy inputs. Fine-grained optimization improves training efficiency.
Versatile Application Domains — Applicable to multisensory AI systems, robotics, human-computer interaction, autonomous agents, and other domains requiring complex data fusion.
Conclusion
This paper presents a novel neural network optimization framework based on the cumulative loss of multiple input-output (I/O) pairs. Unlike conventional methods that apply a single loss function uniformly across the entire network, this approach enables distinct loss functions and optimization strategies tailored to each modality.
The cumulative loss aggregates individual losses into a unified metric that guides overall network training. Importantly, all neurons — including those not directly associated with specific I/O pairs — participate in optimization through internal data propagation. This enables more holistic and adaptive learning in complex multimodal environments.
The proposed method offers significant advantages in flexibility, scalability, generalization, and applicability to real-world multisensory systems. By enabling fine-grained, per-pair optimization within a unified neural architecture, it opens new possibilities for efficient and intelligent multimodal learning.
Future work may explore automated strategies for designing cumulative loss structures, dynamic selection of optimization algorithms per I/O pair, and real-time adaptation of network pathways based on input context or user objectives.
Published at DZone with permission of Paritosh Ranjan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments